 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRate-Informed Discovery via Bayesian Adaptive Multifidelity Sampling
Nov 26, 2024



Ensuring the safety of autonomous vehicles (AVs) requires both accurate estimation of their performance and efficient discovery of potential failure cases. This paper introduces Bayesian adaptive multifidelity sampling (BAMS), which leverages the power of adaptive Bayesian sampling to achieve efficient discovery while simultaneously estimating the rate of adverse events. BAMS prioritizes exploration of regions with potentially low performance, leading to the identification of novel and critical scenarios that traditional methods might miss. Using real-world AV data we demonstrate that BAMS discovers 10 times as many issues as Monte Carlo (MC) and importance sampling (IS) baselines, while at the same time generating rate estimates with variances 15 and 6 times narrower than MC and IS baselines respectively.
Embedding Synthetic Off-Policy Experience for Autonomous Driving via Zero-Shot Curricula
Dec 02, 2022



ML-based motion planning is a promising approach to produce agents that exhibit complex behaviors, and automatically adapt to novel environments. In the context of autonomous driving, it is common to treat all available training data equally. However, this approach produces agents that do not perform robustly in safety-critical settings, an issue that cannot be addressed by simply adding more data to the training set - we show that an agent trained using only a 10% subset of the data performs just as well as an agent trained on the entire dataset. We present a method to predict the inherent difficulty of a driving situation given data collected from a fleet of autonomous vehicles deployed on public roads. We then demonstrate that this difficulty score can be used in a zero-shot transfer to generate curricula for an imitation-learning based planning agent. Compared to training on the entire unbiased training dataset, we show that prioritizing difficult driving scenarios both reduces collisions by 15% and increases route adherence by 14% in closed-loop evaluation, all while using only 10% of the training data.
Hierarchical Model-Based Imitation Learning for Planning in Autonomous Driving
Oct 18, 2022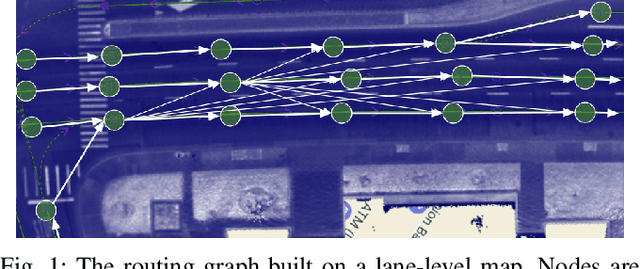
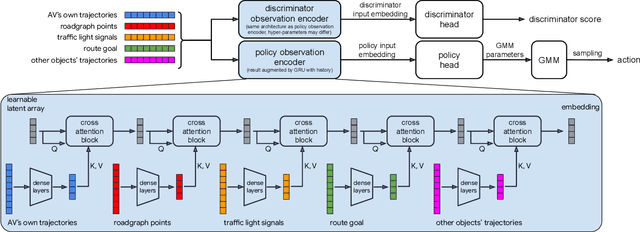
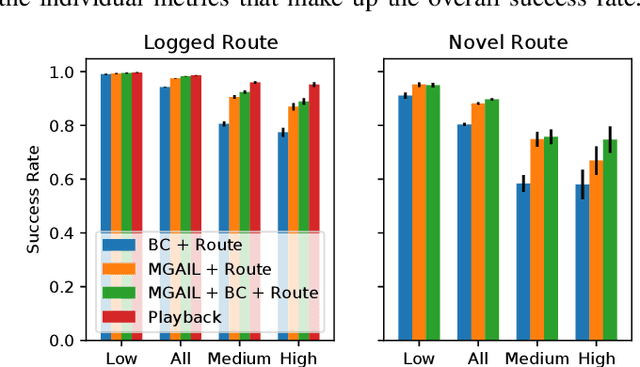
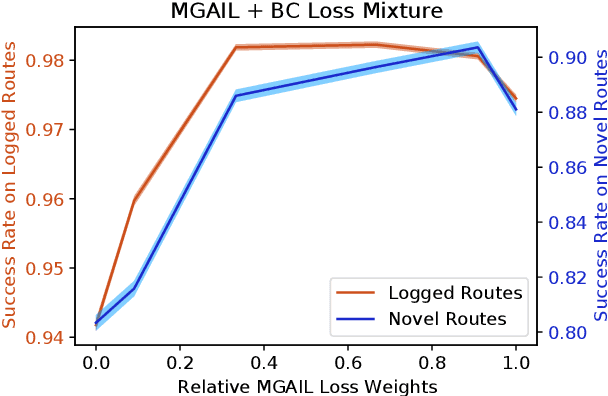
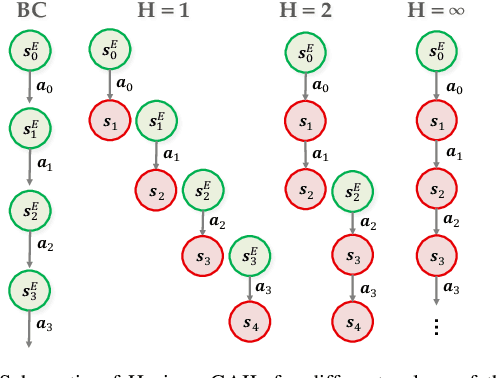
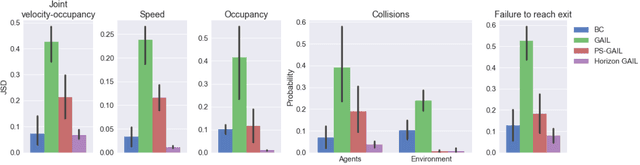
We demonstrate the first large-scale application of model-based generative adversarial imitation learning (MGAIL) to the task of dense urban self-driving. We augment standard MGAIL using a hierarchical model to enable generalization to arbitrary goal routes, and measure performance using a closed-loop evaluation framework with simulated interactive agents. We train policies from expert trajectories collected from real vehicles driving over 100,000 miles in San Francisco, and demonstrate a steerable policy that can navigate robustly even in a zero-shot setting, generalizing to synthetic scenarios with novel goals that never occurred in real-world driving. We also demonstrate the importance of mixing closed-loop MGAIL losses with open-loop behavior cloning losses, and show our best policy approaches the performance of the expert. We evaluate our imitative model in both average and challenging scenarios, and show how it can serve as a useful prior to plan successful trajectories.
Fast Efficient Hyperparameter Tuning for Policy Gradients
Feb 18, 2019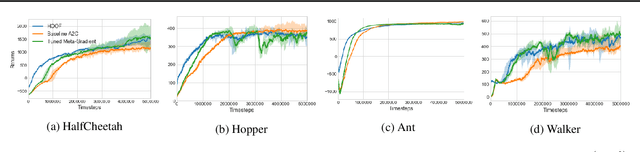
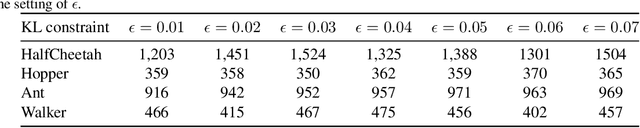
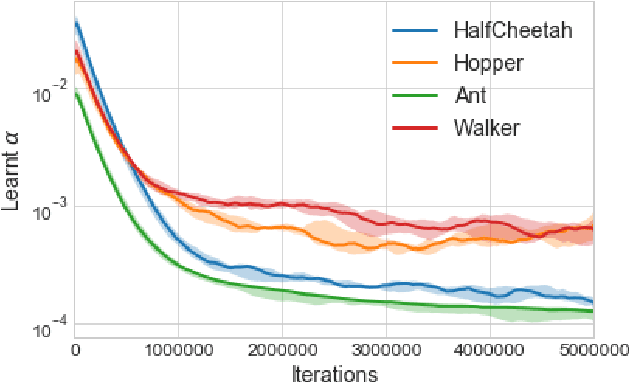
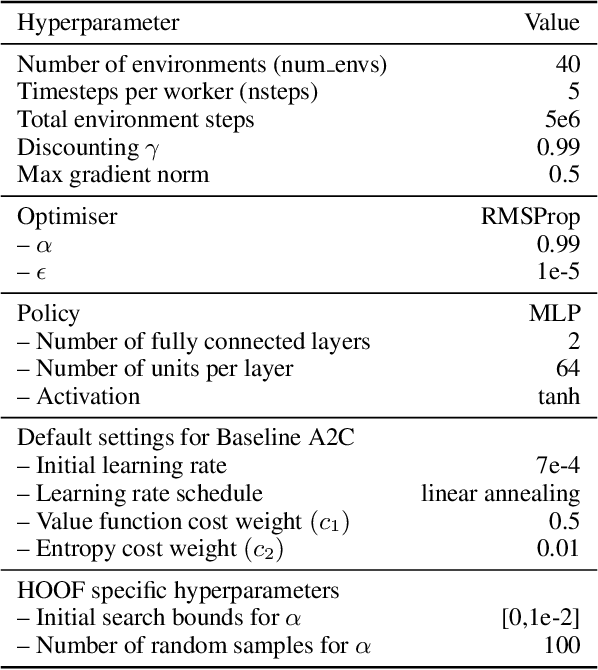
The performance of policy gradient methods is sensitive to hyperparameter settings that must be tuned for any new application. Widely used grid search methods for tuning hyperparameters are sample inefficient and computationally expensive. More advanced methods like Population Based Training that learn optimal schedules for hyperparameters instead of fixed settings can yield better results, but are also sample inefficient and computationally expensive. In this paper, we propose Hyperparameter Optimisation on the Fly (HOOF), a gradient-free meta-learning algorithm that can automatically learn an optimal schedule for hyperparameters that affect the policy update directly through the gradient. The main idea is to use existing trajectories sampled by the policy gradient method to optimise a one-step improvement objective, yielding a sample and computationally efficient algorithm that is easy to implement. Our experimental results across multiple domains and algorithms show that using HOOF to learn these hyperparameter schedules leads to faster learning with improved performance.
Learning from Demonstration in the Wild
Nov 08, 2018
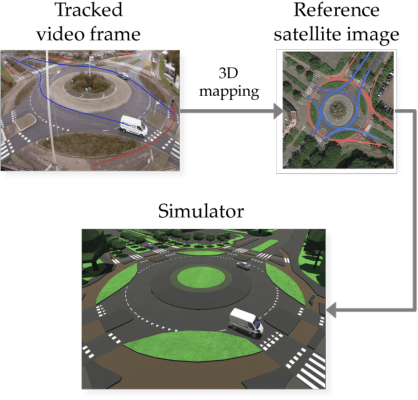
Learning from demonstration (LfD) is useful in settings where hand-coding behaviour or a reward function is impractical. It has succeeded in a wide range of problems but typically relies on artificially generated demonstrations or specially deployed sensors and has not generally been able to leverage the copious demonstrations available in the wild: those that capture behaviour that was occurring anyway using sensors that were already deployed for another purpose, e.g., traffic camera footage capturing demonstrations of natural behaviour of vehicles, cyclists, and pedestrians. We propose video to behaviour (ViBe), a new approach to learning models of road user behaviour that requires as input only unlabelled raw video data of a traffic scene collected from a single, monocular, uncalibrated camera with ordinary resolution. Our approach calibrates the camera, detects relevant objects, tracks them through time, and uses the resulting trajectories to perform LfD, yielding models of naturalistic behaviour. We apply ViBe to raw videos of a traffic intersection and show that it can learn purely from videos, without additional expert knowledge.
Fingerprint Policy Optimisation for Robust Reinforcement Learning
Sep 15, 2018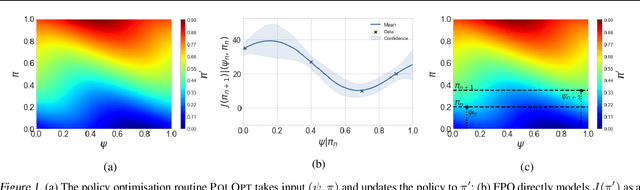
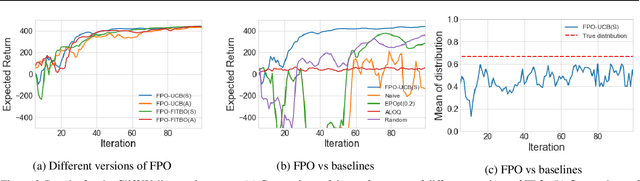
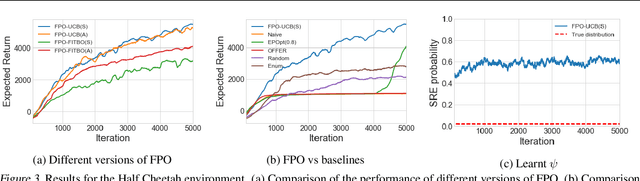
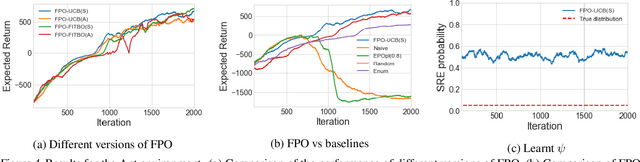
Policy gradient methods have been successfully applied to a variety of reinforcement learning tasks. However, while learning in a simulator, these methods do not utilise the opportunity to improve learning by adjusting certain environment variables: unobservable state features that are randomly determined by the environment in a physical setting, but that are controllable in a simulator. This can lead to slow learning or convergence to highly suboptimal policies if the environment variable has a large impact on the transition dynamics. In this paper, we present fingerprint policy optimisation (FPO) which finds a policy that is optimal in expectation across the distribution of environment variables. The central idea is to use Bayesian optimisation (BO) to actively select the distribution of the environment variable that maximises the improvement generated by each iteration of the policy gradient method. To make this BO practical, we contribute two easy-to-compute low-dimensional fingerprints of the current policy. We apply FPO to a number of continuous control tasks of varying difficulty and show that FPO can efficiently learn policies that are robust to significant rare events, which are unlikely to be observable under random sampling but are key to learning good policies.
Alternating Optimisation and Quadrature for Robust Control
Dec 18, 2017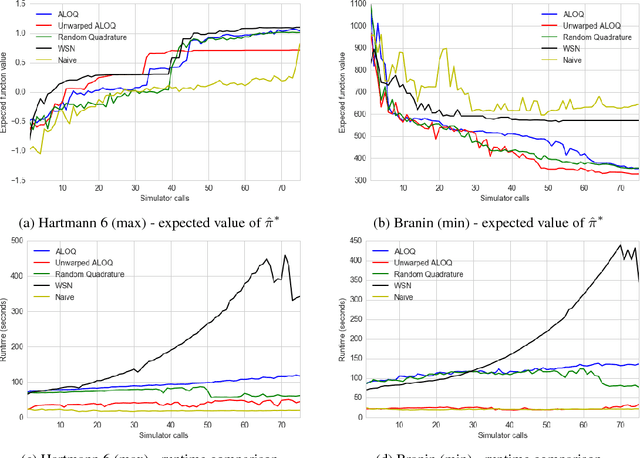
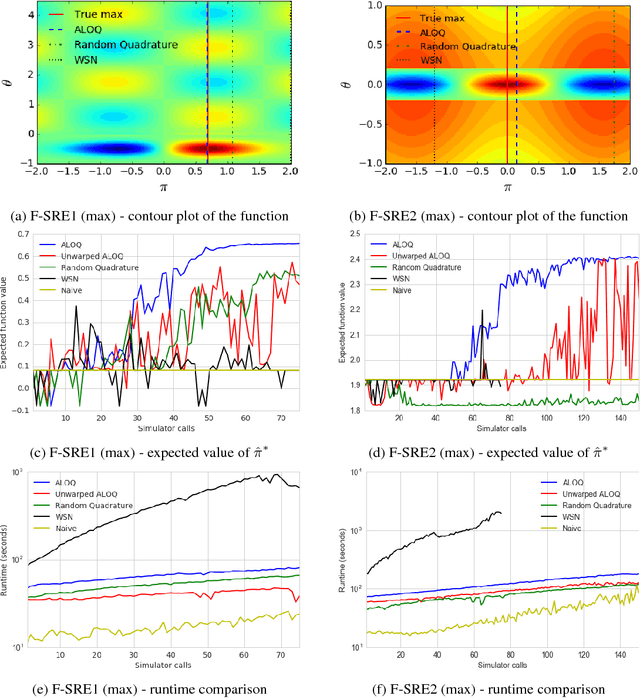
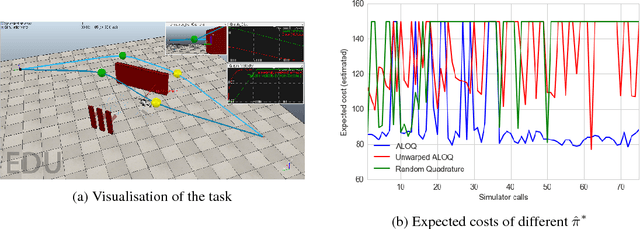
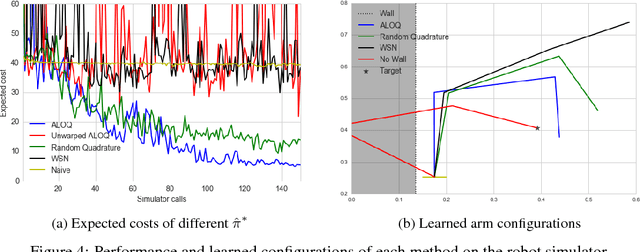
Bayesian optimisation has been successfully applied to a variety of reinforcement learning problems. However, the traditional approach for learning optimal policies in simulators does not utilise the opportunity to improve learning by adjusting certain environment variables: state features that are unobservable and randomly determined by the environment in a physical setting but are controllable in a simulator. This paper considers the problem of finding a robust policy while taking into account the impact of environment variables. We present Alternating Optimisation and Quadrature (ALOQ), which uses Bayesian optimisation and Bayesian quadrature to address such settings. ALOQ is robust to the presence of significant rare events, which may not be observable under random sampling, but play a substantial role in determining the optimal policy. Experimental results across different domains show that ALOQ can learn more efficiently and robustly than existing methods.