 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Scaling in Multimodal Foundation Models: A Comprehensive Survey of Generation and Reasoning
Jun 06, 2026Test-time Scaling (TTS) has emerged as a pivotal research direction for enhancing model performance by dynamically allocating computational resources during inference. Recent advancements have adapted this paradigm to Multimodal Foundation Models (MFMs), unlocking their potential in multimodal reasoning and generation. Despite rapid progress, the field lacks a systematic survey and unified theoretical framework to delineate the developmental landscape of multimodal TTS. To bridge this gap, we present the first comprehensive review of TTS research for MFMs, proposing a unified taxonomic framework that categorizes existing methodologies into three distinct strategies: sampling-based, feedback-based, and search-based approaches. We further summarize representative applications and benchmarks commonly utilized to evaluate multimodal TTS capabilities in generation and reasoning tasks. Finally, this survey discusses open challenges and outlines future research directions, providing a systematic roadmap for subsequent studies in this rapidly evolving field.
Collaborative Multi-Agent Scripts Generation for Enhancing Imperfect-Information Reasoning in Murder Mystery Games
Apr 13, 2026Vision-language models (VLMs) have shown impressive capabilities in perceptual tasks, yet they degrade in complex multi-hop reasoning under multiplayer game settings with imperfect and deceptive information. In this paper, we study a representative multiplayer task, Murder Mystery Games, which require inferring hidden truths based on partial clues provided by roles with different intentions. To address this challenge, we propose a collaborative multi-agent framework for evaluating and synthesizing high-quality, role-driven multiplayer game scripts, enabling fine-grained interaction patterns tailored to character identities (i.e., murderer vs. innocent). Our system generates rich multimodal contexts, including character backstories, visual and textual clues, and multi-hop reasoning chains, through coordinated agent interactions. We design a two-stage agent-monitored training strategy to enhance the reasoning ability of VLMs: (1) chain-of-thought based fine-tuning on curated and synthetic datasets that model uncertainty and deception; (2) GRPO-based reinforcement learning with agent-monitored reward shaping, encouraging the model to develop character-specific reasoning behaviors and effective multimodal multi-hop inference. Extensive experiments demonstrate that our method significantly boosts the performance of VLMs in narrative reasoning, hidden fact extraction, and deception-resilient understanding. Our contributions offer a scalable solution for training and evaluating VLMs under uncertain, adversarial, and socially complex conditions, laying the groundwork for future benchmarks in multimodal multi-hop reasoning under imperfect information.
AtomicVLA: Unlocking the Potential of Atomic Skill Learning in Robots
Mar 08, 2026Recent advances in Visual-Language-Action (VLA) models have shown promising potential for robotic manipulation tasks. However, real-world robotic tasks often involve long-horizon, multi-step problem-solving and require generalization for continual skill acquisition, extending beyond single actions or skills. These challenges present significant barriers for existing VLA models, which use monolithic action decoders trained on aggregated data, resulting in poor scalability. To address these challenges, we propose AtomicVLA, a unified planning-and-execution framework that jointly generates task-level plans, atomic skill abstractions, and fine-grained actions. AtomicVLA constructs a scalable atomic skill library through a Skill-Guided Mixture-of-Experts (SG-MoE), where each expert specializes in mastering generic yet precise atomic skills. Furthermore, we introduce a flexible routing encoder that automatically assigns dedicated atomic experts to new skills, enabling continual learning. We validate our approach through extensive experiments. In simulation, AtomicVLA outperforms $π_{0}$ by 2.4\% on LIBERO, 10\% on LIBERO-LONG, and outperforms $π_{0}$ and $π_{0.5}$ by 0.22 and 0.25 in average task length on CALVIN. Additionally, our AtomicVLA consistently surpasses baselines by 18.3\% and 21\% in real-world long-horizon tasks and continual learning. These results highlight the effectiveness of atomic skill abstraction and dynamic expert composition for long-horizon and lifelong robotic tasks. The project page is \href{https://zhanglk9.github.io/atomicvla-web/}{here}.
Neural Chain-of-Thought Search: Searching the Optimal Reasoning Path to Enhance Large Language Models
Jan 16, 2026Chain-of-Thought reasoning has significantly enhanced the problem-solving capabilities of Large Language Models. Unfortunately, current models generate reasoning steps sequentially without foresight, often becoming trapped in suboptimal reasoning paths with redundant steps. In contrast, we introduce Neural Chain-of-Thought Search (NCoTS), a framework that reformulates reasoning as a dynamic search for the optimal thinking strategy. By quantitatively characterizing the solution space, we reveal the existence of sparse superior reasoning paths that are simultaneously more accurate and concise than standard outputs. Our method actively navigates towards these paths by evaluating candidate reasoning operators using a dual-factor heuristic that optimizes for both correctness and computational cost. Consequently, NCoTS achieves a Pareto improvement across diverse reasoning benchmarks, boosting accuracy by over 3.5% while reducing generation length by over 22%. Our code and data are available at https://github.com/MilkThink-Lab/Neural-CoT-Search.
Robust Egocentric Referring Video Object Segmentation via Dual-Modal Causal Intervention
Dec 30, 2025Egocentric Referring Video Object Segmentation (Ego-RVOS) aims to segment the specific object actively involved in a human action, as described by a language query, within first-person videos. This task is critical for understanding egocentric human behavior. However, achieving such segmentation robustly is challenging due to ambiguities inherent in egocentric videos and biases present in training data. Consequently, existing methods often struggle, learning spurious correlations from skewed object-action pairings in datasets and fundamental visual confounding factors of the egocentric perspective, such as rapid motion and frequent occlusions. To address these limitations, we introduce Causal Ego-REferring Segmentation (CERES), a plug-in causal framework that adapts strong, pre-trained RVOS backbones to the egocentric domain. CERES implements dual-modal causal intervention: applying backdoor adjustment principles to counteract language representation biases learned from dataset statistics, and leveraging front-door adjustment concepts to address visual confounding by intelligently integrating semantic visual features with geometric depth information guided by causal principles, creating representations more robust to egocentric distortions. Extensive experiments demonstrate that CERES achieves state-of-the-art performance on Ego-RVOS benchmarks, highlighting the potential of applying causal reasoning to build more reliable models for broader egocentric video understanding.
Massive Editing for Large Language Models Based on Dynamic Weight Generation
Dec 17, 2025Knowledge Editing (KE) is a field that studies how to modify some knowledge in Large Language Models (LLMs) at a low cost (compared to pre-training). Currently, performing large-scale edits on LLMs while ensuring the Reliability, Generality, and Locality metrics of the edits remain a challenge. This paper proposes a Massive editing approach for LLMs based on dynamic weight Generation (MeG). Our MeG involves attaching a dynamic weight neuron to specific layers of the LLMs and using a diffusion model to conditionally generate the weights of this neuron based on the input query required for the knowledge. This allows the use of adding a single dynamic weight neuron to achieve the goal of large-scale knowledge editing. Experiments show that our MeG can significantly improve the performance of large-scale KE in terms of Reliability, Generality, and Locality metrics compared to existing knowledge editing methods, particularly with a high percentage point increase in the absolute value index for the Locality metric, demonstrating the advantages of our proposed method.
DART: Dual Adaptive Refinement Transfer for Open-Vocabulary Multi-Label Recognition
Aug 07, 2025Open-Vocabulary Multi-Label Recognition (OV-MLR) aims to identify multiple seen and unseen object categories within an image, requiring both precise intra-class localization to pinpoint objects and effective inter-class reasoning to model complex category dependencies. While Vision-Language Pre-training (VLP) models offer a strong open-vocabulary foundation, they often struggle with fine-grained localization under weak supervision and typically fail to explicitly leverage structured relational knowledge beyond basic semantics, limiting performance especially for unseen classes. To overcome these limitations, we propose the Dual Adaptive Refinement Transfer (DART) framework. DART enhances a frozen VLP backbone via two synergistic adaptive modules. For intra-class refinement, an Adaptive Refinement Module (ARM) refines patch features adaptively, coupled with a novel Weakly Supervised Patch Selecting (WPS) loss that enables discriminative localization using only image-level labels. Concurrently, for inter-class transfer, an Adaptive Transfer Module (ATM) leverages a Class Relationship Graph (CRG), constructed using structured knowledge mined from a Large Language Model (LLM), and employs graph attention network to adaptively transfer relational information between class representations. DART is the first framework, to our knowledge, to explicitly integrate external LLM-derived relational knowledge for adaptive inter-class transfer while simultaneously performing adaptive intra-class refinement under weak supervision for OV-MLR. Extensive experiments on challenging benchmarks demonstrate that our DART achieves new state-of-the-art performance, validating its effectiveness.
MiniLongBench: The Low-cost Long Context Understanding Benchmark for Large Language Models
May 26, 2025



Long Context Understanding (LCU) is a critical area for exploration in current large language models (LLMs). However, due to the inherently lengthy nature of long-text data, existing LCU benchmarks for LLMs often result in prohibitively high evaluation costs, like testing time and inference expenses. Through extensive experimentation, we discover that existing LCU benchmarks exhibit significant redundancy, which means the inefficiency in evaluation. In this paper, we propose a concise data compression method tailored for long-text data with sparse information characteristics. By pruning the well-known LCU benchmark LongBench, we create MiniLongBench. This benchmark includes only 237 test samples across six major task categories and 21 distinct tasks. Through empirical analysis of over 60 LLMs, MiniLongBench achieves an average evaluation cost reduced to only 4.5% of the original while maintaining an average rank correlation coefficient of 0.97 with LongBench results. Therefore, our MiniLongBench, as a low-cost benchmark, holds great potential to substantially drive future research into the LCU capabilities of LLMs. See https://github.com/MilkThink-Lab/MiniLongBench for our code, data and tutorial.
RoBridge: A Hierarchical Architecture Bridging Cognition and Execution for General Robotic Manipulation
May 03, 2025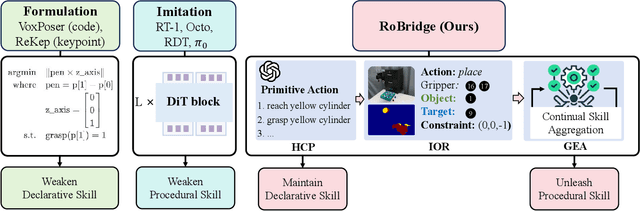
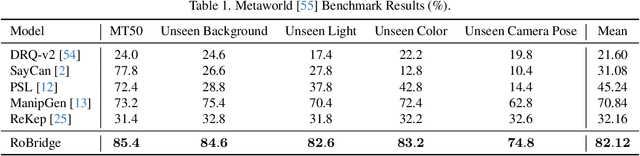
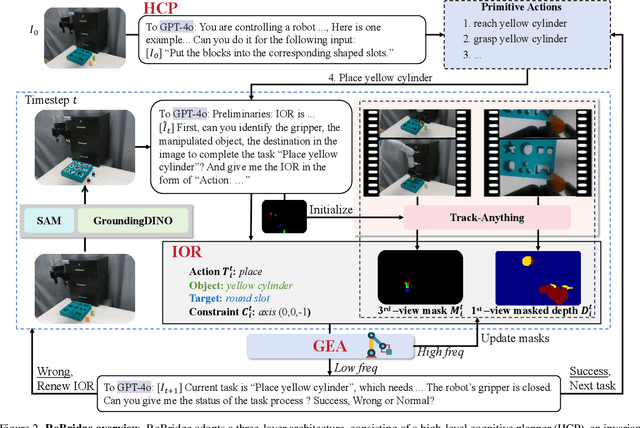
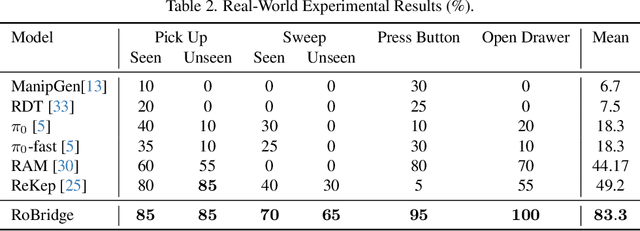
Operating robots in open-ended scenarios with diverse tasks is a crucial research and application direction in robotics. While recent progress in natural language processing and large multimodal models has enhanced robots' ability to understand complex instructions, robot manipulation still faces the procedural skill dilemma and the declarative skill dilemma in open environments. Existing methods often compromise cognitive and executive capabilities. To address these challenges, in this paper, we propose RoBridge, a hierarchical intelligent architecture for general robotic manipulation. It consists of a high-level cognitive planner (HCP) based on a large-scale pre-trained vision-language model (VLM), an invariant operable representation (IOR) serving as a symbolic bridge, and a generalist embodied agent (GEA). RoBridge maintains the declarative skill of VLM and unleashes the procedural skill of reinforcement learning, effectively bridging the gap between cognition and execution. RoBridge demonstrates significant performance improvements over existing baselines, achieving a 75% success rate on new tasks and an 83% average success rate in sim-to-real generalization using only five real-world data samples per task. This work represents a significant step towards integrating cognitive reasoning with physical execution in robotic systems, offering a new paradigm for general robotic manipulation.
Category-Adaptive Cross-Modal Semantic Refinement and Transfer for Open-Vocabulary Multi-Label Recognition
Dec 09, 2024



Benefiting from the generalization capability of CLIP, recent vision language pre-training (VLP) models have demonstrated an impressive ability to capture virtually any visual concept in daily images. However, due to the presence of unseen categories in open-vocabulary settings, existing algorithms struggle to effectively capture strong semantic correlations between categories, resulting in sub-optimal performance on the open-vocabulary multi-label recognition (OV-MLR). Furthermore, the substantial variation in the number of discriminative areas across diverse object categories is misaligned with the fixed-number patch matching used in current methods, introducing noisy visual cues that hinder the accurate capture of target semantics. To tackle these challenges, we propose a novel category-adaptive cross-modal semantic refinement and transfer (C$^2$SRT) framework to explore the semantic correlation both within each category and across different categories, in a category-adaptive manner. The proposed framework consists of two complementary modules, i.e., intra-category semantic refinement (ISR) module and inter-category semantic transfer (IST) module. Specifically, the ISR module leverages the cross-modal knowledge of the VLP model to adaptively find a set of local discriminative regions that best represent the semantics of the target category. The IST module adaptively discovers a set of most correlated categories for a target category by utilizing the commonsense capabilities of LLMs to construct a category-adaptive correlation graph and transfers semantic knowledge from the correlated seen categories to unseen ones. Extensive experiments on OV-MLR benchmarks clearly demonstrate that the proposed C$^2$SRT framework outperforms current state-of-the-art algorithms.