 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCGHair: Compact Gaussian Hair Reconstruction with Card Clustering
Apr 04, 2026We present a compact pipeline for high-fidelity hair reconstruction from multi-view images. While recent 3D Gaussian Splatting (3DGS) methods achieve realistic results, they often require millions of primitives, leading to high storage and rendering costs. Observing that hair exhibits structural and visual similarities across a hairstyle, we cluster strands into representative hair cards and group these into shared texture codebooks. Our approach integrates this structure with 3DGS rendering, significantly reducing reconstruction time and storage while maintaining comparable visual quality. In addition, we propose a generative prior accelerated method to reconstruct the initial strand geometry from a set of images. Our experiments demonstrate a 4-fold reduction in strand reconstruction time and achieve comparable rendering performance with over 200x lower memory footprint.
From Blurry to Believable: Enhancing Low-quality Talking Heads with 3D Generative Priors
Feb 05, 2026Creating high-fidelity, animatable 3D talking heads is crucial for immersive applications, yet often hindered by the prevalence of low-quality image or video sources, which yield poor 3D reconstructions. In this paper, we introduce SuperHead, a novel framework for enhancing low-resolution, animatable 3D head avatars. The core challenge lies in synthesizing high-quality geometry and textures, while ensuring both 3D and temporal consistency during animation and preserving subject identity. Despite recent progress in image, video and 3D-based super-resolution (SR), existing SR techniques are ill-equipped to handle dynamic 3D inputs. To address this, SuperHead leverages the rich priors from pre-trained 3D generative models via a novel dynamics-aware 3D inversion scheme. This process optimizes the latent representation of the generative model to produce a super-resolved 3D Gaussian Splatting (3DGS) head model, which is subsequently rigged to an underlying parametric head model (e.g., FLAME) for animation. The inversion is jointly supervised using a sparse collection of upscaled 2D face renderings and corresponding depth maps, captured from diverse facial expressions and camera viewpoints, to ensure realism under dynamic facial motions. Experiments demonstrate that SuperHead generates avatars with fine-grained facial details under dynamic motions, significantly outperforming baseline methods in visual quality.
A Cartesian Encoding Graph Neural Network for Crystal Structures Property Prediction: Application to Thermal Ellipsoid Estimation
Jan 30, 2025



In diffraction-based crystal structure analysis, thermal ellipsoids, quantified via Anisotropic Displacement Parameters (ADPs), are critical yet challenging to determine. ADPs capture atomic vibrations, reflecting thermal and structural properties, but traditional computation is often expensive. This paper introduces CartNet, a novel graph neural network (GNN) for efficiently predicting crystal properties by encoding atomic geometry into Cartesian coordinates alongside the crystal temperature. CartNet integrates a neighbour equalization technique to emphasize covalent and contact interactions, and a Cholesky-based head to ensure valid ADP predictions. We also propose a rotational SO(3) data augmentation strategy during training to handle unseen orientations. An ADP dataset with over 200,000 experimental crystal structures from the Cambridge Structural Database (CSD) was curated to validate the approach. CartNet significantly reduces computational costs and outperforms existing methods in ADP prediction by 10.87%, while delivering a 34.77% improvement over theoretical approaches. We further evaluated CartNet on other datasets covering formation energy, band gap, total energy, energy above the convex hull, bulk moduli, and shear moduli, achieving 7.71% better results on the Jarvis Dataset and 13.16% on the Materials Project Dataset. These gains establish CartNet as a state-of-the-art solution for diverse crystal property predictions. Project website and online demo: https://www.ee.ub.edu/cartnet
Generalizable Human Gaussians for Sparse View Synthesis
Jul 17, 2024



Recent progress in neural rendering has brought forth pioneering methods, such as NeRF and Gaussian Splatting, which revolutionize view rendering across various domains like AR/VR, gaming, and content creation. While these methods excel at interpolating {\em within the training data}, the challenge of generalizing to new scenes and objects from very sparse views persists. Specifically, modeling 3D humans from sparse views presents formidable hurdles due to the inherent complexity of human geometry, resulting in inaccurate reconstructions of geometry and textures. To tackle this challenge, this paper leverages recent advancements in Gaussian Splatting and introduces a new method to learn generalizable human Gaussians that allows photorealistic and accurate view-rendering of a new human subject from a limited set of sparse views in a feed-forward manner. A pivotal innovation of our approach involves reformulating the learning of 3D Gaussian parameters into a regression process defined on the 2D UV space of a human template, which allows leveraging the strong geometry prior and the advantages of 2D convolutions. In addition, a multi-scaffold is proposed to effectively represent the offset details. Our method outperforms recent methods on both within-dataset generalization as well as cross-dataset generalization settings.
SkinningNet: Two-Stream Graph Convolutional Neural Network for Skinning Prediction of Synthetic Characters
Apr 06, 2022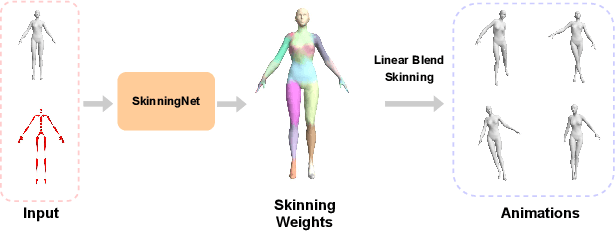
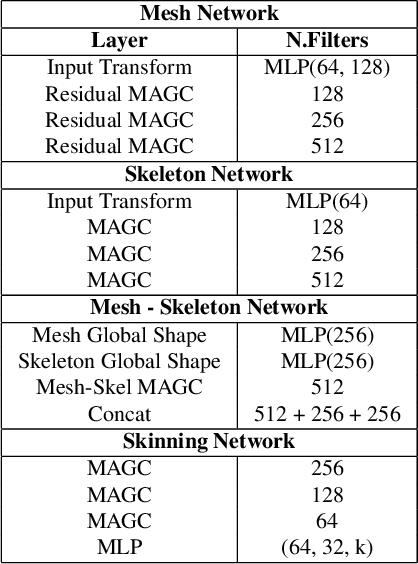
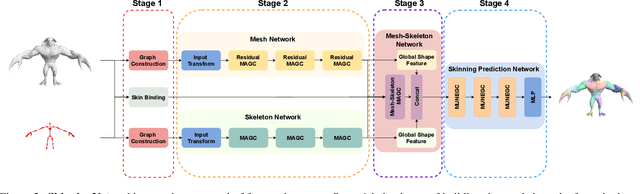
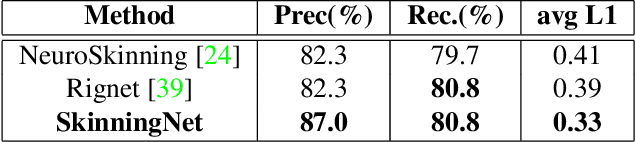
This work presents SkinningNet, an end-to-end Two-Stream Graph Neural Network architecture that computes skinning weights from an input mesh and its associated skeleton, without making any assumptions on shape class and structure of the provided mesh. Whereas previous methods pre-compute handcrafted features that relate the mesh and the skeleton or assume a fixed topology of the skeleton, the proposed method extracts this information in an end-to-end learnable fashion by jointly learning the best relationship between mesh vertices and skeleton joints. The proposed method exploits the benefits of the novel Multi-Aggregator Graph Convolution that combines the results of different aggregators during the summarizing step of the Message-Passing scheme, helping the operation to generalize for unseen topologies. Experimental results demonstrate the effectiveness of the contributions of our novel architecture, with SkinningNet outperforming current state-of-the-art alternatives.
2D-3D Geometric Fusion Network using Multi-Neighbourhood Graph Convolution for RGB-D Indoor Scene Classification
Sep 23, 2020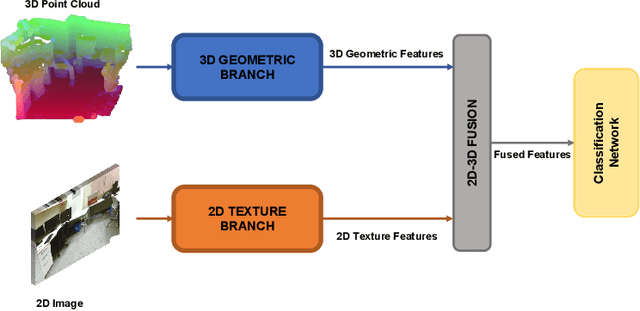
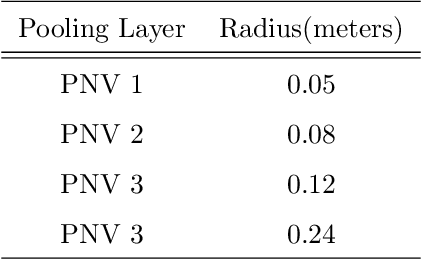
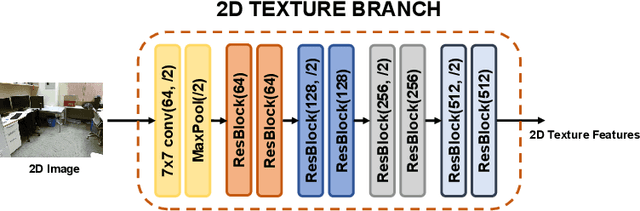
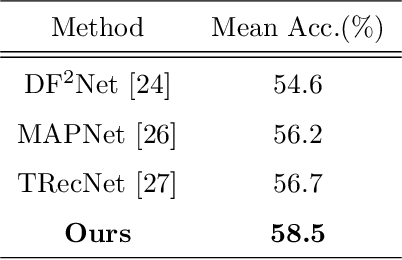
Multi-modal fusion has been proved to help enhance the performance of scene classification tasks. This paper presents a 2D-3D fusion stage that combines 3D Geometric features with 2D Texture features obtained by 2D Convolutional Neural Networks. To get a robust 3D Geometric embedding, a network that uses two novel layers is proposed. The first layer, Multi-Neighbourhood Graph Convolution, aims to learn a more robust geometric descriptor of the scene combining two different neighbourhoods: one in the Euclidean space and the other in the Feature space. The second proposed layer, Nearest Voxel Pooling, improves the performance of the well-known Voxel Pooling. Experimental results, using NYU-Depth-v2 and SUN RGB-D datasets, show that the proposed method outperforms the current state-of-the-art in RGB-D indoor scene classification tasks.
Residual Attention Graph Convolutional Network for Geometric 3D Scene Classification
Sep 30, 2019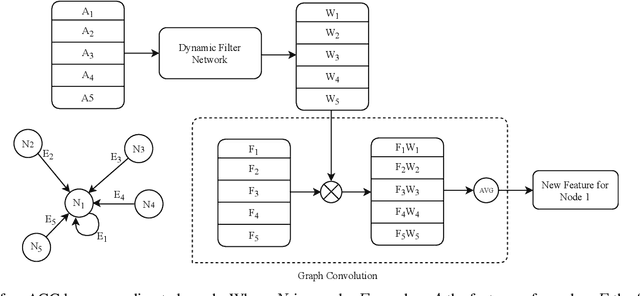
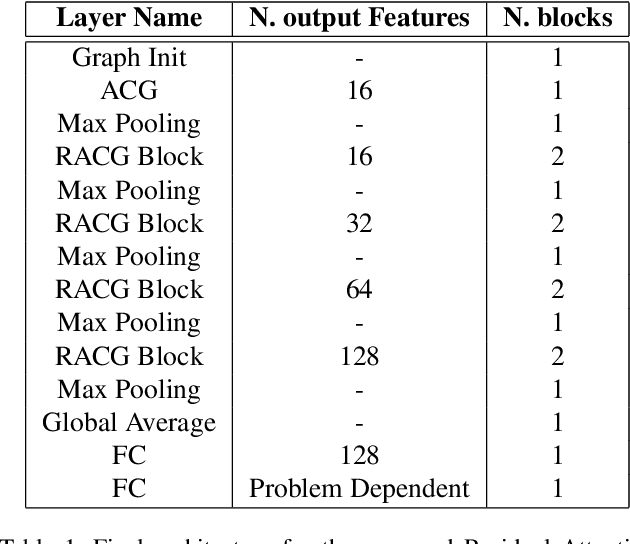
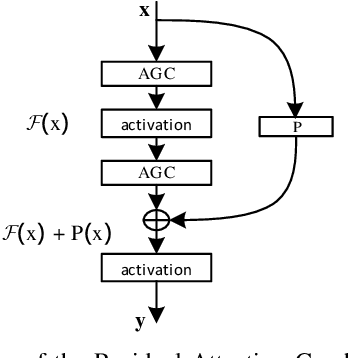
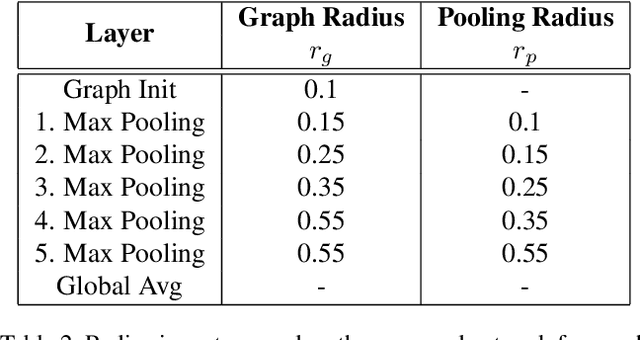
Geometric 3D scene classification is a very challenging task. Current methodologies extract the geometric information using only a depth channel provided by an RGB-D sensor. These kinds of methodologies introduce possible errors due to missing local geometric context in the depth channel. This work proposes a novel Residual Attention Graph Convolutional Network that exploits the intrinsic geometric context inside a 3D space without using any kind of point features, allowing the use of organized or unorganized 3D data. Experiments are done in NYU Depth v1 and SUN-RGBD datasets to study the different configurations and to demonstrate the effectiveness of the proposed method. Experimental results show that the proposed method outperforms current state-of-the-art in geometric 3D scene classification tasks.
Hybrid Cosine Based Convolutional Neural Networks
Apr 03, 2019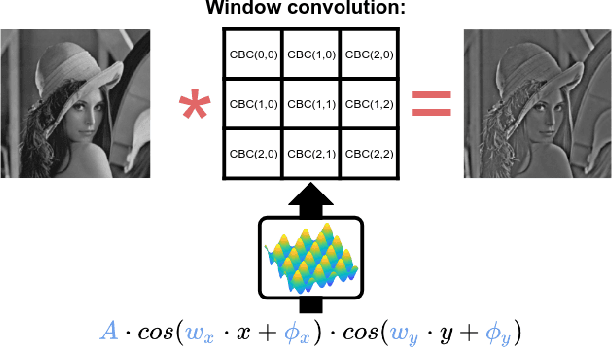

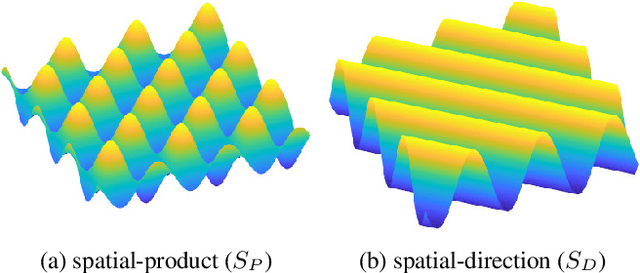
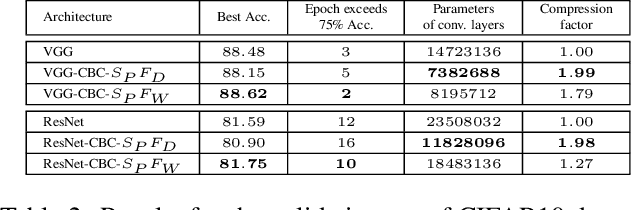
Convolutional neural networks (CNNs) have demonstrated their capability to solve different kind of problems in a very huge number of applications. However, CNNs are limited for their computational and storage requirements. These limitations make difficult to implement these kind of neural networks on embedded devices such as mobile phones, smart cameras or advanced driving assistance systems. In this paper, we present a novel layer named Hybrid Cosine Based Convolution that replaces standard convolutional layers using cosine basis to generate filter weights. The proposed layers provide several advantages: faster convergence in training, the receptive field can be increased at no cost and substantially reduce the number of parameters. We evaluate our proposed layers on three competitive classification tasks where our proposed layers can achieve similar (and in some cases better) performances than VGG and ResNet architectures.