 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-VLA: Adding Contact Audio Perception to Vision-Language-Action Model for Robotic Manipulation
Nov 13, 2025The Vision-Language-Action models (VLA) have achieved significant advances in robotic manipulation recently. However, vision-only VLA models create fundamental limitations, particularly in perceiving interactive and manipulation dynamic processes. This paper proposes Audio-VLA, a multimodal manipulation policy that leverages contact audio to perceive contact events and dynamic process feedback. Audio-VLA overcomes the vision-only constraints of VLA models. Additionally, this paper introduces the Task Completion Rate (TCR) metric to systematically evaluate dynamic operational processes. Audio-VLA employs pre-trained DINOv2 and SigLIP as visual encoders, AudioCLIP as the audio encoder, and Llama2 as the large language model backbone. We apply LoRA fine-tuning to these pre-trained modules to achieve robust cross-modal understanding of both visual and acoustic inputs. A multimodal projection layer aligns features from different modalities into the same feature space. Moreover RLBench and LIBERO simulation environments are enhanced by adding collision-based audio generation to provide realistic sound feedback during object interactions. Since current robotic manipulation evaluations focus on final outcomes rather than providing systematic assessment of dynamic operational processes, the proposed TCR metric measures how well robots perceive dynamic processes during manipulation, creating a more comprehensive evaluation metric. Extensive experiments on LIBERO, RLBench, and two real-world tasks demonstrate Audio-VLA's superior performance over vision-only comparative methods, while the TCR metric effectively quantifies dynamic process perception capabilities.
SWE-Compass: Towards Unified Evaluation of Agentic Coding Abilities for Large Language Models
Nov 07, 2025Evaluating large language models (LLMs) for software engineering has been limited by narrow task coverage, language bias, and insufficient alignment with real-world developer workflows. Existing benchmarks often focus on algorithmic problems or Python-centric bug fixing, leaving critical dimensions of software engineering underexplored. To address these gaps, we introduce SWE-Compass1, a comprehensive benchmark that unifies heterogeneous code-related evaluations into a structured and production-aligned framework. SWE-Compass spans 8 task types, 8 programming scenarios, and 10 programming languages, with 2000 high-quality instances curated from authentic GitHub pull requests and refined through systematic filtering and validation. We benchmark ten state-of-the-art LLMs under two agentic frameworks, SWE-Agent and Claude Code, revealing a clear hierarchy of difficulty across task types, languages, and scenarios. Moreover, by aligning evaluation with real-world developer practices, SWE-Compass provides a rigorous and reproducible foundation for diagnosing and advancing agentic coding capabilities in large language models.
Tiny-WiFo: A Lightweight Wireless Foundation Model for Channel Prediction via Multi-Component Adaptive Knowledge Distillation
Nov 06, 2025The massive scale of Wireless Foundation Models (FMs) hinders their real-time deployment on edge devices. This letter moves beyond standard knowledge distillation by introducing a novel Multi-Component Adaptive Knowledge Distillation (MCAKD) framework. Key innovations include a Cross-Attention-Based Knowledge Selection (CA-KS) module that selectively identifies critical features from the teacher model, and an Autonomous Learning-Passive Learning (AL-PL) strategy that balances knowledge transfer with independent learning to achieve high training efficiency at a manageable computational cost. When applied to the WiFo FM, the distilled Tiny-WiFo model, with only 5.5M parameters, achieves a 1.6 ms inference time on edge hardware while retaining over 98% of WiFo's performance and its crucial zero-shot generalization capability, making real-time FM deployment viable.
Ferret-UI Lite: Lessons from Building Small On-Device GUI Agents
Sep 30, 2025



Developing autonomous agents that effectively interact with Graphic User Interfaces (GUIs) remains a challenging open problem, especially for small on-device models. In this paper, we present Ferret-UI Lite, a compact, end-to-end GUI agent that operates across diverse platforms, including mobile, web, and desktop. Utilizing techniques optimized for developing small models, we build our 3B Ferret-UI Lite agent through curating a diverse GUI data mixture from real and synthetic sources, strengthening inference-time performance through chain-of-thought reasoning and visual tool-use, and reinforcement learning with designed rewards. Ferret-UI Lite achieves competitive performance with other small-scale GUI agents. In GUI grounding, Ferret-UI Lite attains scores of $91.6\%$, $53.3\%$, and $61.2\%$ on the ScreenSpot-V2, ScreenSpot-Pro, and OSWorld-G benchmarks, respectively. For GUI navigation, Ferret-UI Lite achieves success rates of $28.0\%$ on AndroidWorld and $19.8\%$ on OSWorld. We share our methods and lessons learned from developing compact, on-device GUI agents.
MANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer
Sep 19, 2025
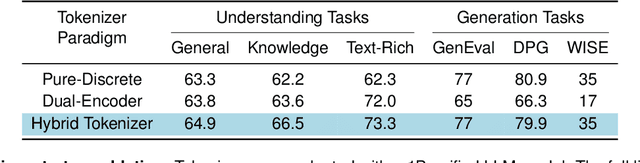
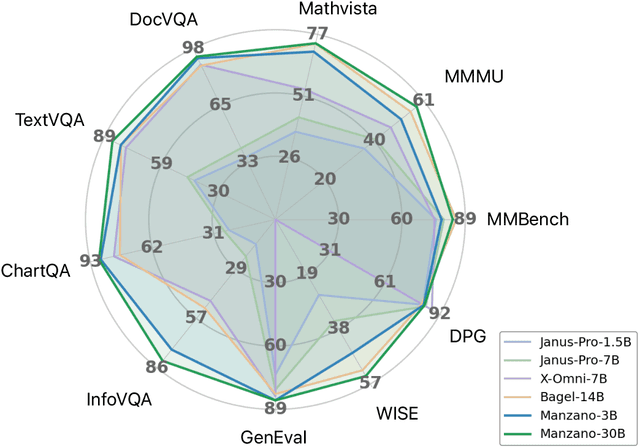
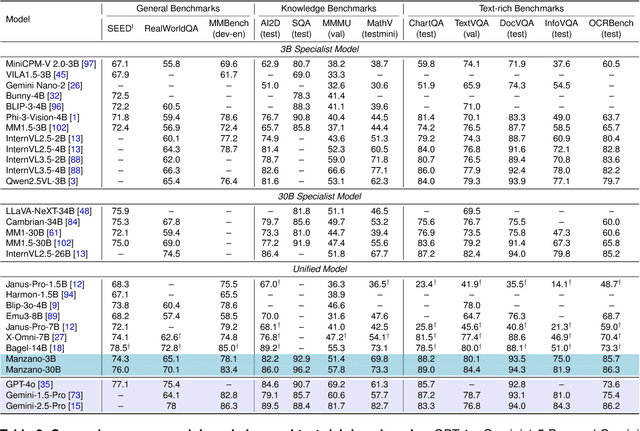
Unified multimodal Large Language Models (LLMs) that can both understand and generate visual content hold immense potential. However, existing open-source models often suffer from a performance trade-off between these capabilities. We present Manzano, a simple and scalable unified framework that substantially reduces this tension by coupling a hybrid image tokenizer with a well-curated training recipe. A single shared vision encoder feeds two lightweight adapters that produce continuous embeddings for image-to-text understanding and discrete tokens for text-to-image generation within a common semantic space. A unified autoregressive LLM predicts high-level semantics in the form of text and image tokens, with an auxiliary diffusion decoder subsequently translating the image tokens into pixels. The architecture, together with a unified training recipe over understanding and generation data, enables scalable joint learning of both capabilities. Manzano achieves state-of-the-art results among unified models, and is competitive with specialist models, particularly on text-rich evaluation. Our studies show minimal task conflicts and consistent gains from scaling model size, validating our design choice of a hybrid tokenizer.
FoBa: A Foreground-Background co-Guided Method and New Benchmark for Remote Sensing Semantic Change Detection
Sep 19, 2025



Despite the remarkable progress achieved in remote sensing semantic change detection (SCD), two major challenges remain. At the data level, existing SCD datasets suffer from limited change categories, insufficient change types, and a lack of fine-grained class definitions, making them inadequate to fully support practical applications. At the methodological level, most current approaches underutilize change information, typically treating it as a post-processing step to enhance spatial consistency, which constrains further improvements in model performance. To address these issues, we construct a new benchmark for remote sensing SCD, LevirSCD. Focused on the Beijing area, the dataset covers 16 change categories and 210 specific change types, with more fine-grained class definitions (e.g., roads are divided into unpaved and paved roads). Furthermore, we propose a foreground-background co-guided SCD (FoBa) method, which leverages foregrounds that focus on regions of interest and backgrounds enriched with contextual information to guide the model collaboratively, thereby alleviating semantic ambiguity while enhancing its ability to detect subtle changes. Considering the requirements of bi-temporal interaction and spatial consistency in SCD, we introduce a Gated Interaction Fusion (GIF) module along with a simple consistency loss to further enhance the model's detection performance. Extensive experiments on three datasets (SECOND, JL1, and the proposed LevirSCD) demonstrate that FoBa achieves competitive results compared to current SOTA methods, with improvements of 1.48%, 3.61%, and 2.81% in the SeK metric, respectively. Our code and dataset are available at https://github.com/zmoka-zht/FoBa.
Scaling Learned Image Compression Models up to 1 Billion
Aug 12, 2025Recent advances in large language models (LLMs) highlight a strong connection between intelligence and compression. Learned image compression, a fundamental task in modern data compression, has made significant progress in recent years. However, current models remain limited in scale, restricting their representation capacity, and how scaling model size influences compression performance remains unexplored. In this work, we present a pioneering study on scaling up learned image compression models and revealing the performance trends through scaling laws. Using the recent state-of-the-art HPCM model as baseline, we scale model parameters from 68.5 millions to 1 billion and fit power-law relations between test loss and key scaling variables, including model size and optimal training compute. The results reveal a scaling trend, enabling extrapolation to larger scale models. Experimental results demonstrate that the scaled-up HPCM-1B model achieves state-of-the-art rate-distortion performance. We hope this work inspires future exploration of large-scale compression models and deeper investigations into the connection between compression and intelligence.
LARGO: Low-Rank Regulated Gradient Projection for Robust Parameter Efficient Fine-Tuning
Jun 14, 2025



The advent of parameter-efficient fine-tuning methods has significantly reduced the computational burden of adapting large-scale pretrained models to diverse downstream tasks. However, existing approaches often struggle to achieve robust performance under domain shifts while maintaining computational efficiency. To address this challenge, we propose Low-rAnk Regulated Gradient Projection (LARGO) algorithm that integrates dynamic constraints into low-rank adaptation methods. Specifically, LARGO incorporates parallel trainable gradient projections to dynamically regulate layer-wise updates, retaining the Out-Of-Distribution robustness of pretrained model while preserving inter-layer independence. Additionally, it ensures computational efficiency by mitigating the influence of gradient dependencies across layers during weight updates. Besides, through leveraging singular value decomposition of pretrained weights for structured initialization, we incorporate an SVD-based initialization strategy that minimizing deviation from pretrained knowledge. Through extensive experiments on diverse benchmarks, LARGO achieves state-of-the-art performance across in-domain and out-of-distribution scenarios, demonstrating improved robustness under domain shifts with significantly lower computational overhead compared to existing PEFT methods. The source code will be released soon.
Synesthesia of Machines (SoM)-Aided Online FDD Precoding via Heterogeneous Multi-Modal Sensing: A Vertical Federated Learning Approach
Jun 09, 2025This paper investigates a heterogeneous multi-vehicle, multi-modal sensing (H-MVMM) aided online precoding problem. The proposed H-MVMM scheme utilizes a vertical federated learning (VFL) framework to minimize pilot sequence length and optimize the sum rate. This offers a promising solution for reducing latency in frequency division duplexing systems. To achieve this, three preprocessing modules are designed to transform raw sensory data into informative representations relevant to precoding. The approach effectively addresses local data heterogeneity arising from diverse on-board sensor configurations through a well-structured VFL training procedure. Additionally, a label-free online model updating strategy is introduced, enabling the H-MVMM scheme to adapt its weights flexibly. This strategy features a pseudo downlink channel state information label simulator (PCSI-Simulator), which is trained using a semi-supervised learning (SSL) approach alongside an online loss function. Numerical results show that the proposed method can closely approximate the performance of traditional optimization techniques with perfect channel state information, achieving a significant 90.6\% reduction in pilot sequence length.
SIGMA: Refining Large Language Model Reasoning via Sibling-Guided Monte Carlo Augmentation
Jun 06, 2025



Enhancing large language models by simply scaling up datasets has begun to yield diminishing returns, shifting the spotlight to data quality. Monte Carlo Tree Search (MCTS) has emerged as a powerful technique for generating high-quality chain-of-thought data, yet conventional approaches typically retain only the top-scoring trajectory from the search tree, discarding sibling nodes that often contain valuable partial insights, recurrent error patterns, and alternative reasoning strategies. This unconditional rejection of non-optimal reasoning branches may waste vast amounts of informative data in the whole search tree. We propose SIGMA (Sibling Guided Monte Carlo Augmentation), a novel framework that reintegrates these discarded sibling nodes to refine LLM reasoning. SIGMA forges semantic links among sibling nodes along each search path and applies a two-stage refinement: a critique model identifies overlooked strengths and weaknesses across the sibling set, and a revision model conducts text-based backpropagation to refine the top-scoring trajectory in light of this comparative feedback. By recovering and amplifying the underutilized but valuable signals from non-optimal reasoning branches, SIGMA substantially improves reasoning trajectories. On the challenging MATH benchmark, our SIGMA-tuned 7B model achieves 54.92% accuracy using only 30K samples, outperforming state-of-the-art models trained on 590K samples. This result highlights that our sibling-guided optimization not only significantly reduces data usage but also significantly boosts LLM reasoning.