 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFerret-UI Lite: Lessons from Building Small On-Device GUI Agents
Sep 30, 2025



Developing autonomous agents that effectively interact with Graphic User Interfaces (GUIs) remains a challenging open problem, especially for small on-device models. In this paper, we present Ferret-UI Lite, a compact, end-to-end GUI agent that operates across diverse platforms, including mobile, web, and desktop. Utilizing techniques optimized for developing small models, we build our 3B Ferret-UI Lite agent through curating a diverse GUI data mixture from real and synthetic sources, strengthening inference-time performance through chain-of-thought reasoning and visual tool-use, and reinforcement learning with designed rewards. Ferret-UI Lite achieves competitive performance with other small-scale GUI agents. In GUI grounding, Ferret-UI Lite attains scores of $91.6\%$, $53.3\%$, and $61.2\%$ on the ScreenSpot-V2, ScreenSpot-Pro, and OSWorld-G benchmarks, respectively. For GUI navigation, Ferret-UI Lite achieves success rates of $28.0\%$ on AndroidWorld and $19.8\%$ on OSWorld. We share our methods and lessons learned from developing compact, on-device GUI agents.
MM1.5: Methods, Analysis & Insights from Multimodal LLM Fine-tuning
Sep 30, 2024



We present MM1.5, a new family of multimodal large language models (MLLMs) designed to enhance capabilities in text-rich image understanding, visual referring and grounding, and multi-image reasoning. Building upon the MM1 architecture, MM1.5 adopts a data-centric approach to model training, systematically exploring the impact of diverse data mixtures across the entire model training lifecycle. This includes high-quality OCR data and synthetic captions for continual pre-training, as well as an optimized visual instruction-tuning data mixture for supervised fine-tuning. Our models range from 1B to 30B parameters, encompassing both dense and mixture-of-experts (MoE) variants, and demonstrate that careful data curation and training strategies can yield strong performance even at small scales (1B and 3B). Additionally, we introduce two specialized variants: MM1.5-Video, designed for video understanding, and MM1.5-UI, tailored for mobile UI understanding. Through extensive empirical studies and ablations, we provide detailed insights into the training processes and decisions that inform our final designs, offering valuable guidance for future research in MLLM development.
CoLay: Controllable Layout Generation through Multi-conditional Latent Diffusion
May 18, 2024



Layout design generation has recently gained significant attention due to its potential applications in various fields, including UI, graphic, and floor plan design. However, existing models face two main challenges that limits their adoption in practice. Firstly, the limited expressiveness of individual condition types used in previous works restricts designers' ability to convey complex design intentions and constraints. Secondly, most existing models focus on generating labels and coordinates, while real layouts contain a range of style properties. To address these limitations, we propose a novel framework, CoLay, that integrates multiple condition types and generates complex layouts with diverse style properties. Our approach outperforms prior works in terms of generation quality and condition satisfaction while empowering users to express their design intents using a flexible combination of modalities, including natural language prompts, layout guidelines, element types, and partially completed designs.
Leveraging Human Revisions for Improving Text-to-Layout Models
May 16, 2024



Learning from human feedback has shown success in aligning large, pretrained models with human values. Prior works have mostly focused on learning from high-level labels, such as preferences between pairs of model outputs. On the other hand, many domains could benefit from more involved, detailed feedback, such as revisions, explanations, and reasoning of human users. Our work proposes using nuanced feedback through the form of human revisions for stronger alignment. In this paper, we ask expert designers to fix layouts generated from a generative layout model that is pretrained on a large-scale dataset of mobile screens. Then, we train a reward model based on how human designers revise these generated layouts. With the learned reward model, we optimize our model with reinforcement learning from human feedback (RLHF). Our method, Revision-Aware Reward Models ($\method$), allows a generative text-to-layout model to produce more modern, designer-aligned layouts, showing the potential for utilizing human revisions and stronger forms of feedback in improving generative models.
Automatic Macro Mining from Interaction Traces at Scale
Oct 10, 2023



Macros are building block tasks of our everyday smartphone activity (e.g., "login", or "booking a flight"). Effectively extracting macros is important for understanding mobile interaction and enabling task automation. These macros are however difficult to extract at scale as they can be comprised of multiple steps yet hidden within programmatic components of the app. In this paper, we introduce a novel approach based on Large Language Models (LLMs) to automatically extract semantically meaningful macros from both random and user-curated mobile interaction traces. The macros produced by our approach are automatically tagged with natural language descriptions and are fully executable. To examine the quality of extraction, we conduct multiple studies, including user evaluation, comparative analysis against human-curated tasks, and automatic execution of these macros. These experiments and analyses show the effectiveness of our approach and the usefulness of extracted macros in various downstream applications.
PLay: Parametrically Conditioned Layout Generation using Latent Diffusion
Jan 27, 2023



Layout design is an important task in various design fields, including user interfaces, document, and graphic design. As this task requires tedious manual effort by designers, prior works have attempted to automate this process using generative models, but commonly fell short of providing intuitive user controls and achieving design objectives. In this paper, we build a conditional latent diffusion model, PLay, that generates parametrically conditioned layouts in vector graphic space from user-specified guidelines, which are commonly used by designers for representing their design intents in current practices. Our method outperforms prior works across three datasets on metrics including FID and FD-VG, and in user test. Moreover, it brings a novel and interactive experience to professional layout design processes.
Sketch-based Creativity Support Tools using Deep Learning
Nov 19, 2021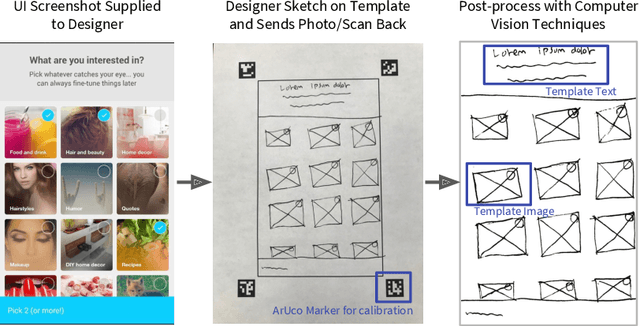

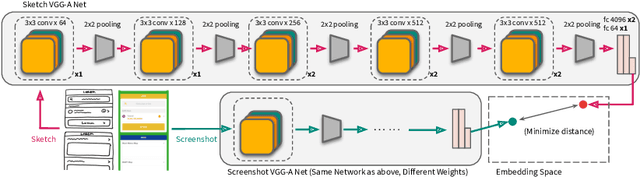
Sketching is a natural and effective visual communication medium commonly used in creative processes. Recent developments in deep-learning models drastically improved machines' ability in understanding and generating visual content. An exciting area of development explores deep-learning approaches used to model human sketches, opening opportunities for creative applications. This chapter describes three fundamental steps in developing deep-learning-driven creativity support tools that consumes and generates sketches: 1) a data collection effort that generated a new paired dataset between sketches and mobile user interfaces; 2) a sketch-based user interface retrieval system adapted from state-of-the-art computer vision techniques; and, 3) a conversational sketching system that supports the novel interaction of a natural-language-based sketch/critique authoring process. In this chapter, we survey relevant prior work in both the deep-learning and human-computer-interaction communities, document the data collection process and the systems' architectures in detail, present qualitative and quantitative results, and paint the landscape of several future research directions in this exciting area.
Creating User Interface Mock-ups from High-Level Text Descriptions with Deep-Learning Models
Oct 14, 2021

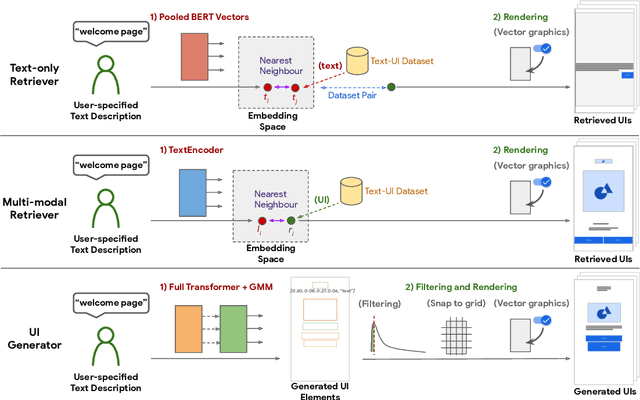
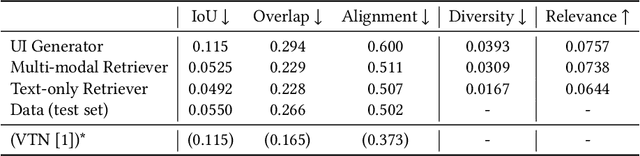
The design process of user interfaces (UIs) often begins with articulating high-level design goals. Translating these high-level design goals into concrete design mock-ups, however, requires extensive effort and UI design expertise. To facilitate this process for app designers and developers, we introduce three deep-learning techniques to create low-fidelity UI mock-ups from a natural language phrase that describes the high-level design goal (e.g. "pop up displaying an image and other options"). In particular, we contribute two retrieval-based methods and one generative method, as well as pre-processing and post-processing techniques to ensure the quality of the created UI mock-ups. We quantitatively and qualitatively compare and contrast each method's ability in suggesting coherent, diverse and relevant UI design mock-ups. We further evaluate these methods with 15 professional UI designers and practitioners to understand each method's advantages and disadvantages. The designers responded positively to the potential of these methods for assisting the design process.
Scones: Towards Conversational Authoring of Sketches
May 12, 2020

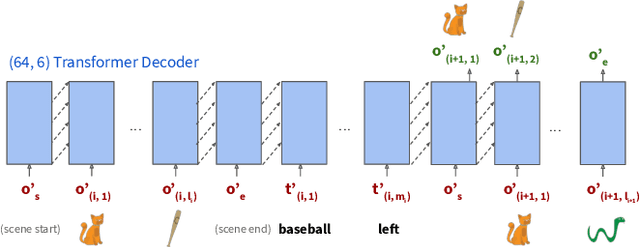
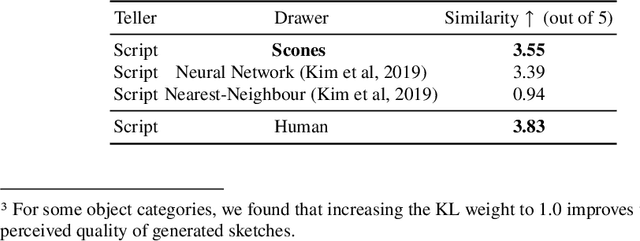
Iteratively refining and critiquing sketches are crucial steps to developing effective designs. We introduce Scones, a mixed-initiative, machine-learning-driven system that enables users to iteratively author sketches from text instructions. Scones is a novel deep-learning-based system that iteratively generates scenes of sketched objects composed with semantic specifications from natural language. Scones exceeds state-of-the-art performance on a text-based scene modification task, and introduces a mask-conditioned sketching model that can generate sketches with poses specified by high-level scene information. In an exploratory user evaluation of Scones, participants reported enjoying an iterative drawing task with Scones, and suggested additional features for further applications. We believe Scones is an early step towards automated, intelligent systems that support human-in-the-loop applications for communicating ideas through sketching in art and design.
Sketchforme: Composing Sketched Scenes from Text Descriptions for Interactive Applications
Apr 08, 2019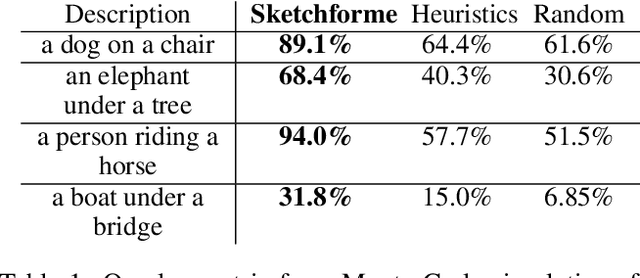
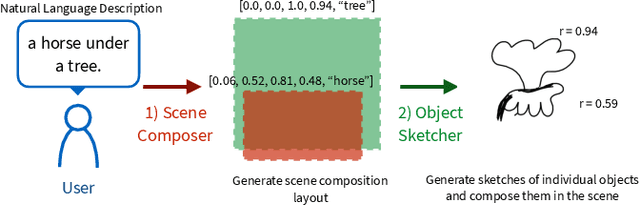
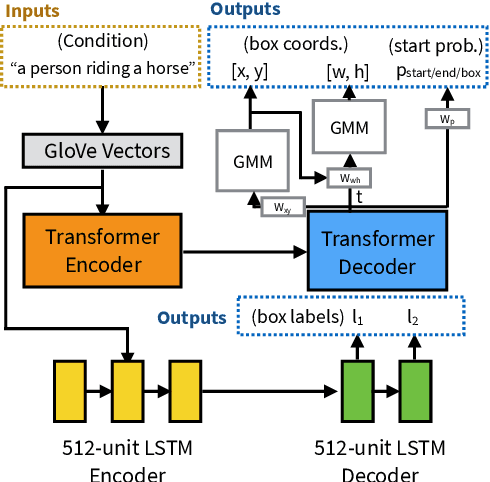
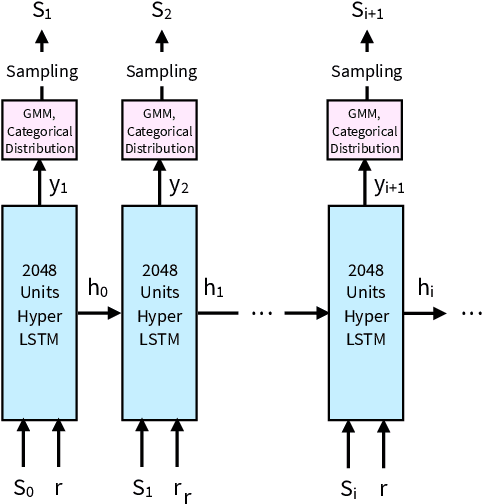
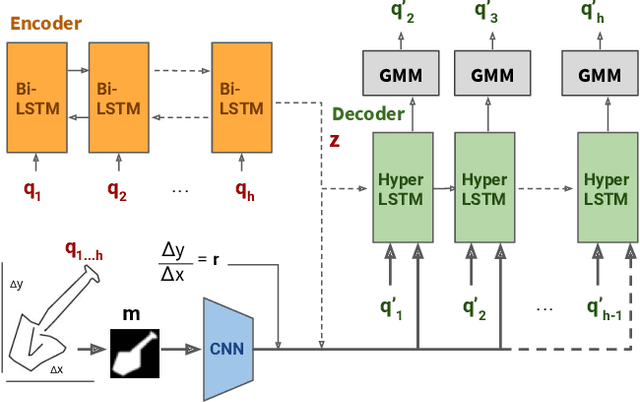
Sketching and natural languages are effective communication media for interactive applications. We introduce Sketchforme, the first neural-network-based system that can generate sketches based on text descriptions specified by users. Sketchforme is capable of gaining high-level and low-level understanding of multi-object sketched scenes without being trained on sketched scene datasets annotated with text descriptions. The sketches composed by Sketchforme are expressive and realistic: we show in our user study that these sketches convey descriptions better than human-generated sketches in multiple cases, and 36.5% of those sketches are considered to be human-generated. We develop multiple interactive applications using these generated sketches, and show that Sketchforme can significantly improve language learning applications and support intelligent language-based sketching assistants.