 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexRepNet: Learning Dexterous Robotic Grasping Network with Geometric and Spatial Hand-Object Representations
Mar 20, 2023



Robotic dexterous grasping is a challenging problem due to the high degree of freedom (DoF) and complex contacts of multi-fingered robotic hands. Existing deep reinforcement learning (DRL) based methods leverage human demonstrations to reduce sample complexity due to the high dimensional action space with dexterous grasping. However, less attention has been paid to hand-object interaction representations for high-level generalization. In this paper, we propose a novel geometric and spatial hand-object interaction representation, named DexRep, to capture dynamic object shape features and the spatial relations between hands and objects during grasping. DexRep comprises Occupancy Feature for rough shapes within sensing range by moving hands, Surface Feature for changing hand-object surface distances, and Local-Geo Feature for local geometric surface features most related to potential contacts. Based on the new representation, we propose a dexterous deep reinforcement learning method to learn a generalizable grasping policy DexRepNet. Experimental results show that our method outperforms baselines using existing representations for robotic grasping dramatically both in grasp success rate and convergence speed. It achieves a 93% grasping success rate on seen objects and higher than 80% grasping success rates on diverse objects of unseen categories in both simulation and real-world experiments.
Learning Object Affordance with Contact and Grasp Generation
Oct 17, 2022
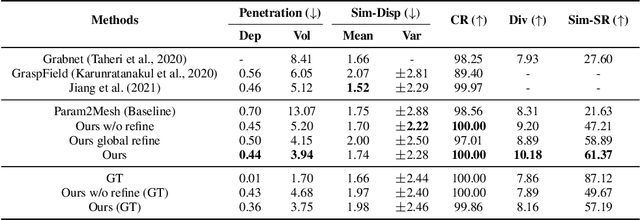
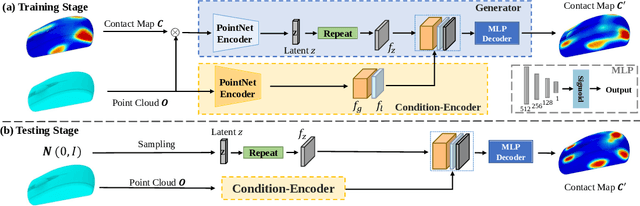
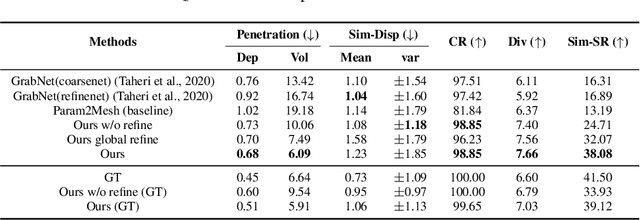
Understanding object affordance can help in designing better and more robust robotic grasping. Existing work in the computer vision community formulates the object affordance understanding as a grasping pose generation problem, which treats the problem as a black box by learning a mapping between objects and the distributions of possible grasping poses for the objects. On the other hand, in the robotics community, estimating object affordance represented by contact maps is of the most importance as localizing the positions of the possible affordance can help the planning of grasping actions. In this paper, we propose to formulate the object affordance understanding as both contacts and grasp poses generation. we factorize the learning task into two sequential stages, rather than the black-box strategy: (1) we first reason the contact maps by allowing multi-modal contact generation; (2) assuming that grasping poses are fully constrained given contact maps, we learn a one-to-one mapping from the contact maps to the grasping poses. Further, we propose a penetration-aware partial optimization from the intermediate contacts. It combines local and global optimization for the refinement of the partial poses of the generated grasps exhibiting penetration. Extensive validations on two public datasets show our method outperforms state-of-the-art methods regarding grasp generation on various metrics.
Sketch guided and progressive growing GAN for realistic and editable ultrasound image synthesis
Apr 19, 2022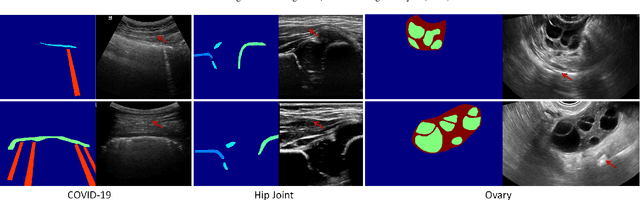
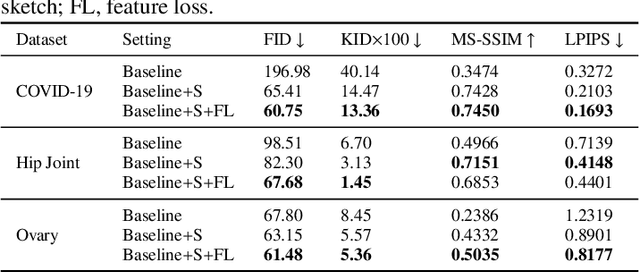
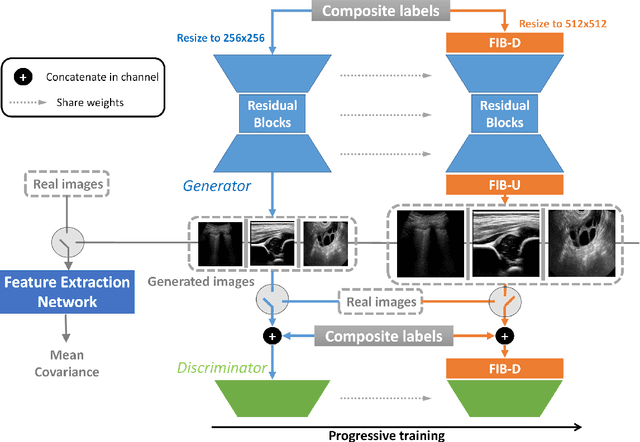

Ultrasound (US) imaging is widely used for anatomical structure inspection in clinical diagnosis. The training of new sonographers and deep learning based algorithms for US image analysis usually requires a large amount of data. However, obtaining and labeling large-scale US imaging data are not easy tasks, especially for diseases with low incidence. Realistic US image synthesis can alleviate this problem to a great extent. In this paper, we propose a generative adversarial network (GAN) based image synthesis framework. Our main contributions include: 1) we present the first work that can synthesize realistic B-mode US images with high-resolution and customized texture editing features; 2) to enhance structural details of generated images, we propose to introduce auxiliary sketch guidance into a conditional GAN. We superpose the edge sketch onto the object mask and use the composite mask as the network input; 3) to generate high-resolution US images, we adopt a progressive training strategy to gradually generate high-resolution images from low-resolution images. In addition, a feature loss is proposed to minimize the difference of high-level features between the generated and real images, which further improves the quality of generated images; 4) the proposed US image synthesis method is quite universal and can also be generalized to the US images of other anatomical structures besides the three ones tested in our study (lung, hip joint, and ovary); 5) extensive experiments on three large US image datasets are conducted to validate our method. Ablation studies, customized texture editing, user studies, and segmentation tests demonstrate promising results of our method in synthesizing realistic US images.
Follow the Prophet: Accurate Online Conversion Rate Prediction in the Face of Delayed Feedback
Aug 13, 2021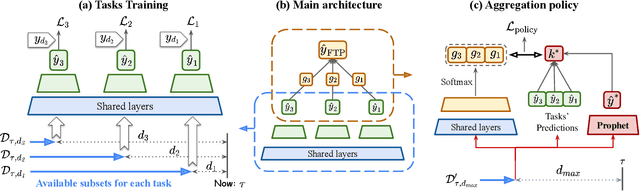
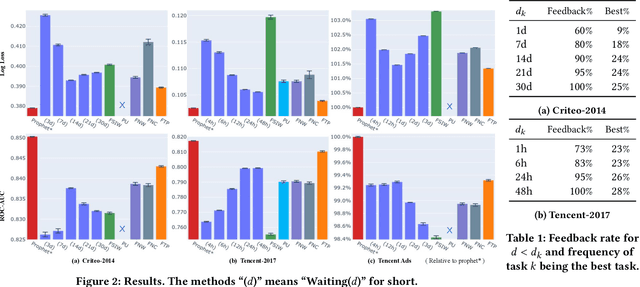
The delayed feedback problem is one of the imperative challenges in online advertising, which is caused by the highly diversified feedback delay of a conversion varying from a few minutes to several days. It is hard to design an appropriate online learning system under these non-identical delay for different types of ads and users. In this paper, we propose to tackle the delayed feedback problem in online advertising by "Following the Prophet" (FTP for short). The key insight is that, if the feedback came instantly for all the logged samples, we could get a model without delayed feedback, namely the "prophet". Although the prophet cannot be obtained during online learning, we show that we could predict the prophet's predictions by an aggregation policy on top of a set of multi-task predictions, where each task captures the feedback patterns of different periods. We propose the objective and optimization approach for the policy, and use the logged data to imitate the prophet. Extensive experiments on three real-world advertising datasets show that our method outperforms the previous state-of-the-art baselines.
GuideBoot: Guided Bootstrap for Deep Contextual Bandits
Jul 18, 2021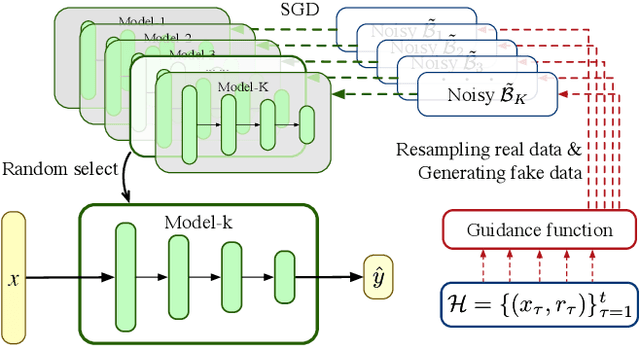
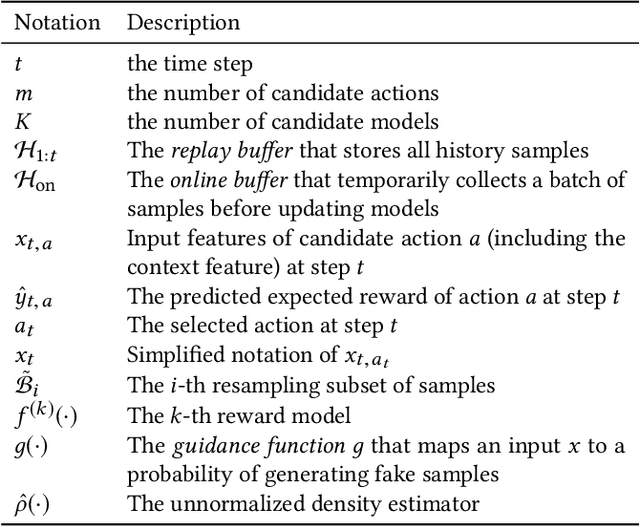
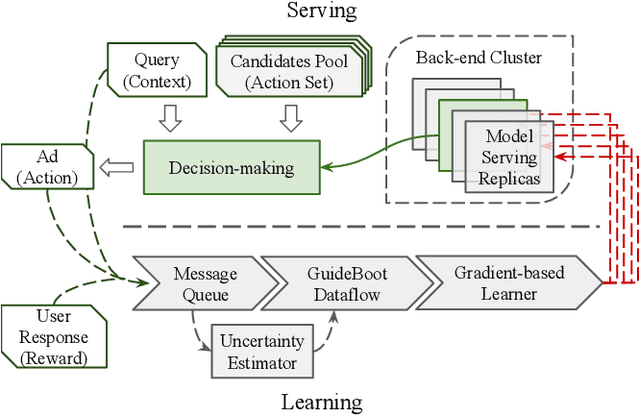
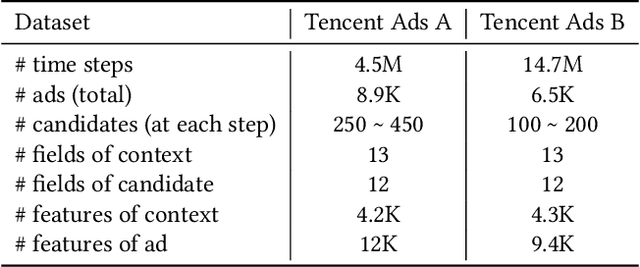
The exploration/exploitation (E&E) dilemma lies at the core of interactive systems such as online advertising, for which contextual bandit algorithms have been proposed. Bayesian approaches provide guided exploration with principled uncertainty estimation, but the applicability is often limited due to over-simplified assumptions. Non-Bayesian bootstrap methods, on the other hand, can apply to complex problems by using deep reward models, but lacks clear guidance to the exploration behavior. It still remains largely unsolved to develop a practical method for complex deep contextual bandits. In this paper, we introduce Guided Bootstrap (GuideBoot for short), combining the best of both worlds. GuideBoot provides explicit guidance to the exploration behavior by training multiple models over both real samples and noisy samples with fake labels, where the noise is added according to the predictive uncertainty. The proposed method is efficient as it can make decisions on-the-fly by utilizing only one randomly chosen model, but is also effective as we show that it can be viewed as a non-Bayesian approximation of Thompson sampling. Moreover, we extend it to an online version that can learn solely from streaming data, which is favored in real applications. Extensive experiments on both synthetic task and large-scale advertising environments show that GuideBoot achieves significant improvements against previous state-of-the-art methods.
Classification with Strategically Withheld Data
Jan 14, 2021
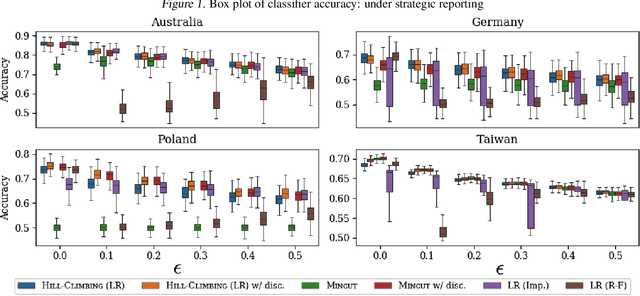

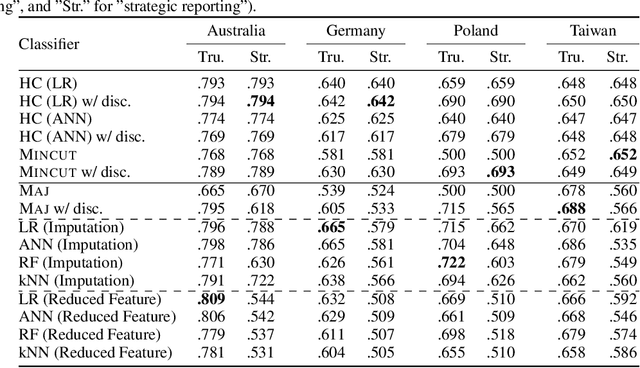
Machine learning techniques can be useful in applications such as credit approval and college admission. However, to be classified more favorably in such contexts, an agent may decide to strategically withhold some of her features, such as bad test scores. This is a missing data problem with a twist: which data is missing {\em depends on the chosen classifier}, because the specific classifier is what may create the incentive to withhold certain feature values. We address the problem of training classifiers that are robust to this behavior. We design three classification methods: {\sc Mincut}, {\sc Hill-Climbing} ({\sc HC}) and Incentive-Compatible Logistic Regression ({\sc IC-LR}). We show that {\sc Mincut} is optimal when the true distribution of data is fully known. However, it can produce complex decision boundaries, and hence be prone to overfitting in some cases. Based on a characterization of truthful classifiers (i.e., those that give no incentive to strategically hide features), we devise a simpler alternative called {\sc HC} which consists of a hierarchical ensemble of out-of-the-box classifiers, trained using a specialized hill-climbing procedure which we show to be convergent. For several reasons, {\sc Mincut} and {\sc HC} are not effective in utilizing a large number of complementarily informative features. To this end, we present {\sc IC-LR}, a modification of Logistic Regression that removes the incentive to strategically drop features. We also show that our algorithms perform well in experiments on real-world data sets, and present insights into their relative performance in different settings.
Contrastive Rendering for Ultrasound Image Segmentation
Oct 10, 2020
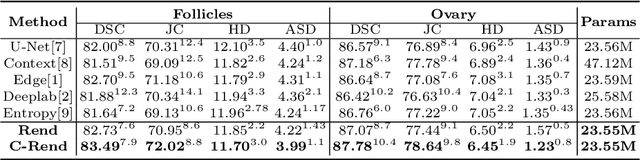
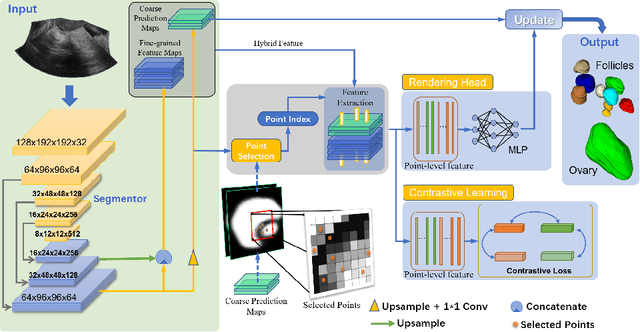
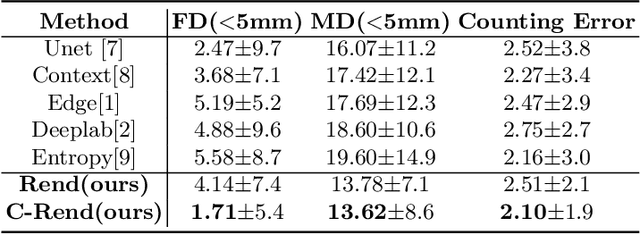
Ultrasound (US) image segmentation embraced its significant improvement in deep learning era. However, the lack of sharp boundaries in US images still remains an inherent challenge for segmentation. Previous methods often resort to global context, multi-scale cues or auxiliary guidance to estimate the boundaries. It is hard for these methods to approach pixel-level learning for fine-grained boundary generating. In this paper, we propose a novel and effective framework to improve boundary estimation in US images. Our work has three highlights. First, we propose to formulate the boundary estimation as a rendering task, which can recognize ambiguous points (pixels/voxels) and calibrate the boundary prediction via enriched feature representation learning. Second, we introduce point-wise contrastive learning to enhance the similarity of points from the same class and contrastively decrease the similarity of points from different classes. Boundary ambiguities are therefore further addressed. Third, both rendering and contrastive learning tasks contribute to consistent improvement while reducing network parameters. As a proof-of-concept, we performed validation experiments on a challenging dataset of 86 ovarian US volumes. Results show that our proposed method outperforms state-of-the-art methods and has the potential to be used in clinical practice.
Synthesis and Edition of Ultrasound Images via Sketch Guided Progressive Growing GANs
Apr 01, 2020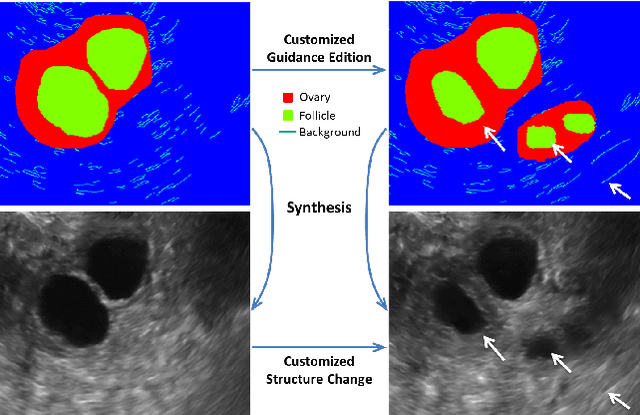
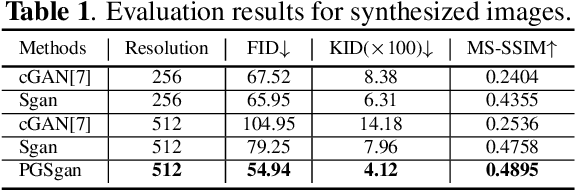
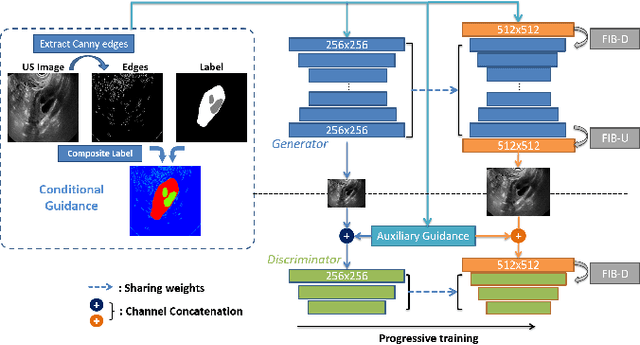
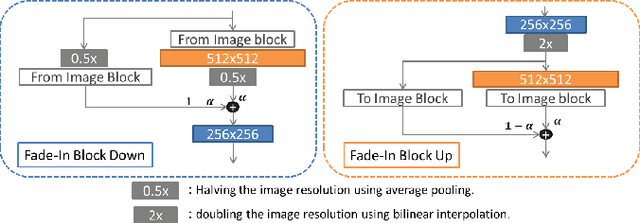
Ultrasound (US) is widely accepted in clinic for anatomical structure inspection. However, lacking in resources to practice US scan, novices often struggle to learn the operation skills. Also, in the deep learning era, automated US image analysis is limited by the lack of annotated samples. Efficiently synthesizing realistic, editable and high resolution US images can solve the problems. The task is challenging and previous methods can only partially complete it. In this paper, we devise a new framework for US image synthesis. Particularly, we firstly adopt a sketch generative adversarial networks (Sgan) to introduce background sketch upon object mask in a conditioned generative adversarial network. With enriched sketch cues, Sgan can generate realistic US images with editable and fine-grained structure details. Although effective, Sgan is hard to generate high resolution US images. To achieve this, we further implant the Sgan into a progressive growing scheme (PGSgan). By smoothly growing both generator and discriminator, PGSgan can gradually synthesize US images from low to high resolution. By synthesizing ovary and follicle US images, our extensive perceptual evaluation, user study and segmentation results prove the promising efficacy and efficiency of the proposed PGSgan.
Minimizing Time-to-Rank: A Learning and Recommendation Approach
May 27, 2019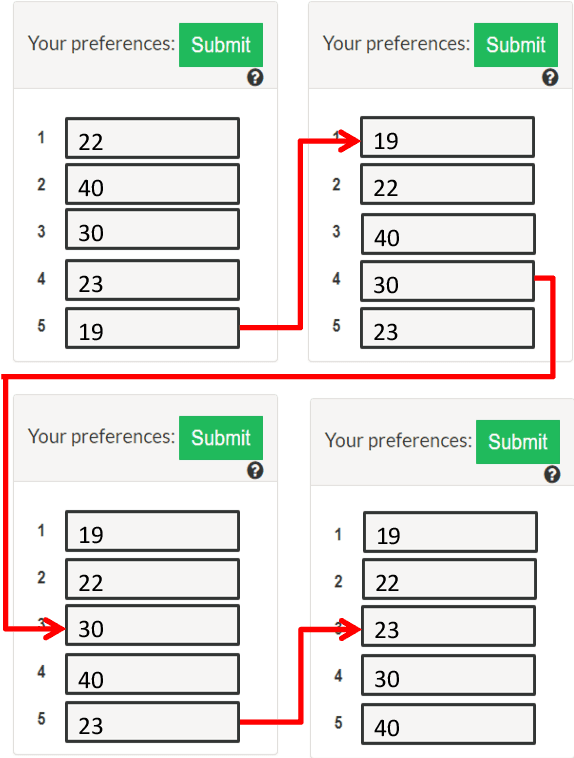


Consider the following problem faced by an online voting platform: A user is provided with a list of alternatives, and is asked to rank them in order of preference using only drag-and-drop operations. The platform's goal is to recommend an initial ranking that minimizes the time spent by the user in arriving at her desired ranking. We develop the first optimization framework to address this problem, and make theoretical as well as practical contributions. On the practical side, our experiments on Amazon Mechanical Turk provide two interesting insights about user behavior: First, that users' ranking strategies closely resemble selection or insertion sort, and second, that the time taken for a drag-and-drop operation depends linearly on the number of positions moved. These insights directly motivate our theoretical model of the optimization problem. We show that computing an optimal recommendation is NP-hard, and provide exact and approximation algorithms for a variety of special cases of the problem. Experimental evaluation on MTurk shows that, compared to a random recommendation strategy, the proposed approach reduces the (average) time-to-rank by up to 50%.
A Cost-Effective Framework for Preference Elicitation and Aggregation
Jul 07, 2018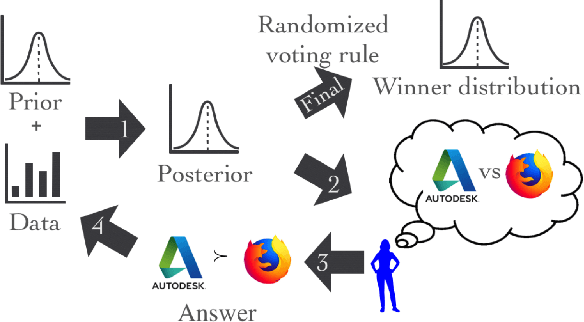
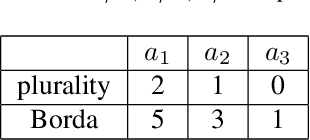
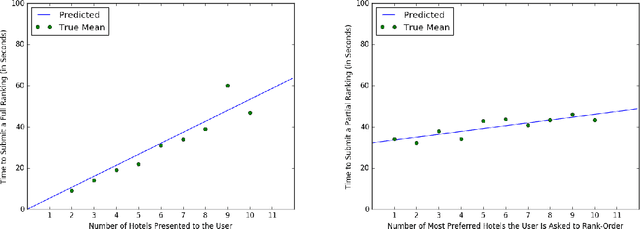
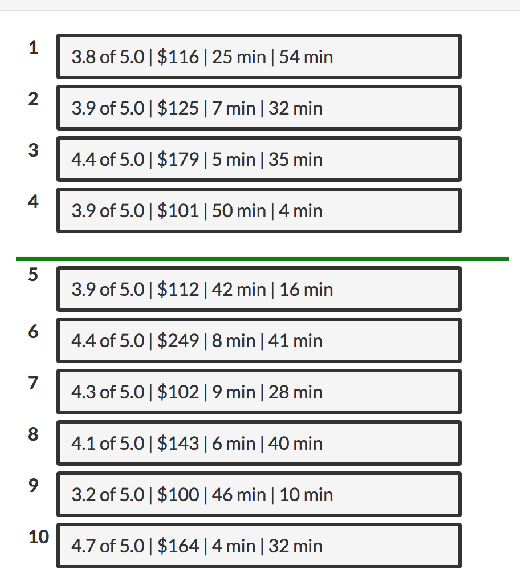
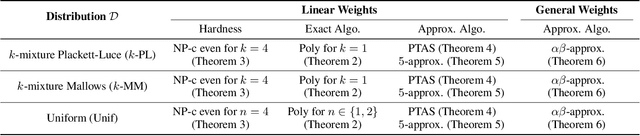
We propose a cost-effective framework for preference elicitation and aggregation under the Plackett-Luce model with features. Given a budget, our framework iteratively computes the most cost-effective elicitation questions in order to help the agents make a better group decision. We illustrate the viability of the framework with experiments on Amazon Mechanical Turk, which we use to estimate the cost of answering different types of elicitation questions. We compare the prediction accuracy of our framework when adopting various information criteria that evaluate the expected information gain from a question. Our experiments show carefully designed information criteria are much more efficient, i.e., they arrive at the correct answer using fewer queries, than randomly asking questions given the budget constraint.