 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture of Complementary Agents for Robust LLM Ensemble
May 21, 2026Multi-AI collaboration, such as ensembling or debating large language models (LLMs), is a promising paradigm for aggregating information and boosting performance. A foundational step in these pipelines is to feed the responses of several proposer LLMs into a summarizer LLM, which synthesizes a better answer. However, choosing which proposers to include is non-trivial. Existing approaches primarily focus either on accuracy (picking the strongest models) or diversity (ensuring variety), and often overlook the interactions among proposers and with the summarizer. We reframe proposer selection as a combinatorial selection problem akin to feature selection, where the value of an LLM lies in its complementarity with others. However, directly applying standard feature-selection algorithms is impractical in the LLM setting due to prohibitive time complexity. Motivated by this limitation, we explore an extensive range of computationally feasible, greedy-style selection algorithms that assess complementarity using a small labeled set. Our experiments validate complementarity as a guiding principle for proposer selection and identify methods that achieve the best performance-cost trade-offs in practice.
A Linear Theory of Multi-Winner Voting
Mar 05, 2025We introduces a general linear framework that unifies the study of multi-winner voting rules and proportionality axioms, demonstrating that many prominent multi-winner voting rules-including Thiele methods, their sequential variants, and approval-based committee scoring rules-are linear. Similarly, key proportionality axioms such as Justified Representation (JR), Extended JR (EJR), and their strengthened variants (PJR+, EJR+), along with core stability, can fit within this linear structure as well. Leveraging PAC learning theory, we establish general and novel upper bounds on the sample complexity of learning linear mappings. Our approach yields near-optimal guarantees for diverse classes of rules, including Thiele methods and ordered weighted average rules, and can be applied to analyze the sample complexity of learning proportionality axioms such as approximate core stability. Furthermore, the linear structure allows us to leverage prior work to extend our analysis beyond worst-case scenarios to study the likelihood of various properties of linear rules and axioms. We introduce a broad class of distributions that extend Impartial Culture for approval preferences, and show that under these distributions, with high probability, any Thiele method is resolute, CORE is non-empty, and any Thiele method satisfies CORE, among other observations on the likelihood of commonly-studied properties in social choice. We believe that this linear theory offers a new perspective and powerful new tools for designing and analyzing multi-winner rules in modern social choice applications.
Average-Case Analysis of Iterative Voting
Feb 13, 2024Iterative voting is a natural model of repeated strategic decision-making in social choice when agents have the opportunity to update their votes prior to finalizing the group decision. Prior work has analyzed the efficacy of iterative plurality on the welfare of the chosen outcome at equilibrium, relative to the truthful vote profile, via an adaptation of the price of anarchy. However, prior analyses have only studied the worst-case and average-case performances when agents' preferences are distributed by the impartial culture. This work extends average-case analyses to a wider class of distributions and distinguishes when iterative plurality improves or degrades asymptotic welfare.
LLM-augmented Preference Learning from Natural Language
Oct 12, 2023



Finding preferences expressed in natural language is an important but challenging task. State-of-the-art(SotA) methods leverage transformer-based models such as BERT, RoBERTa, etc. and graph neural architectures such as graph attention networks. Since Large Language Models (LLMs) are equipped to deal with larger context lengths and have much larger model sizes than the transformer-based model, we investigate their ability to classify comparative text directly. This work aims to serve as a first step towards using LLMs for the CPC task. We design and conduct a set of experiments that format the classification task into an input prompt for the LLM and a methodology to get a fixed-format response that can be automatically evaluated. Comparing performances with existing methods, we see that pre-trained LLMs are able to outperform the previous SotA models with no fine-tuning involved. Our results show that the LLMs can consistently outperform the SotA when the target text is large -- i.e. composed of multiple sentences --, and are still comparable to the SotA performance in shorter text. We also find that few-shot learning yields better performance than zero-shot learning.
Determining Winners in Elections with Absent Votes
Oct 11, 2023An important question in elections is the determine whether a candidate can be a winner when some votes are absent. We study this determining winner with the absent votes (WAV) problem when the votes are top-truncated. We show that the WAV problem is NP-complete for the single transferable vote, Maximin, and Copeland, and propose a special case of positional scoring rule such that the problem can be computed in polynomial time. Our results in top-truncated rankings differ from the results in full rankings as their hardness results still hold when the number of candidates or the number of missing votes are bounded, while we show that the problem can be solved in polynomial time in either case.
First-Choice Maximality Meets Ex-ante and Ex-post Fairness
May 08, 2023For the assignment problem where multiple indivisible items are allocated to a group of agents given their ordinal preferences, we design randomized mechanisms that satisfy first-choice maximality (FCM), i.e., maximizing the number of agents assigned their first choices, together with Pareto efficiency (PE). Our mechanisms also provide guarantees of ex-ante and ex-post fairness. The generalized eager Boston mechanism is ex-ante envy-free, and ex-post envy-free up to one item (EF1). The generalized probabilistic Boston mechanism is also ex-post EF1, and satisfies ex-ante efficiency instead of fairness. We also show that no strategyproof mechanism satisfies ex-post PE, EF1, and FCM simultaneously. In doing so, we expand the frontiers of simultaneously providing efficiency and both ex-ante and ex-post fairness guarantees for the assignment problem.
Differentially Private Condorcet Voting
Jun 27, 2022
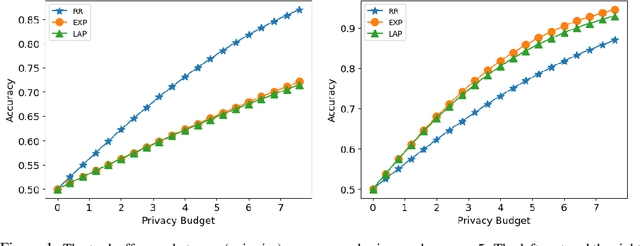
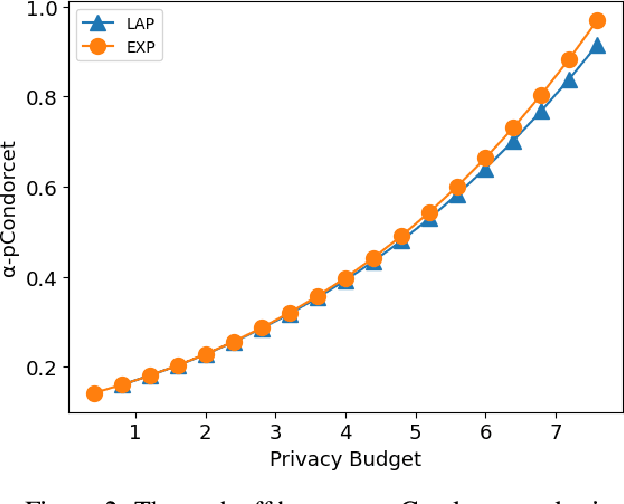
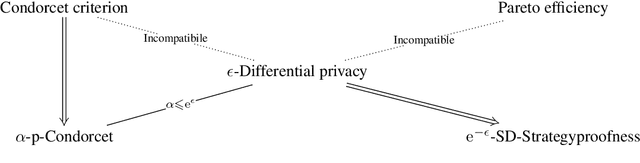
Designing private voting rules is an important and pressing problem for trustworthy democracy. In this paper, under the framework of differential privacy, we propose three classes of randomized voting rules based on the well-known Condorcet method: Laplacian Condorcet method ($CM^{LAP}_\lambda$), exponential Condorcet method ($CM^{EXP}_\lambda$), and randomized response Condorcet method ($CM^{RR}_\lambda$), where $\lambda$ represents the level of noise. By accurately estimating the errors introduced by the randomness, we show that $CM^{EXP}_\lambda$ is the most accurate mechanism in most cases. We prove that all of our rules satisfy absolute monotonicity, lexi-participation, probabilistic Pareto efficiency, approximate probabilistic Condorcet criterion, and approximate SD-strategyproofness. In addition, $CM^{RR}_\lambda$ satisfies (non-approximate) probabilistic Condorcet criterion, while $CM^{LAP}_\lambda$ and $CM^{EXP}_\lambda$ satisfy strong lexi-participation. Finally, we regard differential privacy as a voting axiom, and discuss its relations to other axioms.
Fair and Fast Tie-Breaking for Voting
May 30, 2022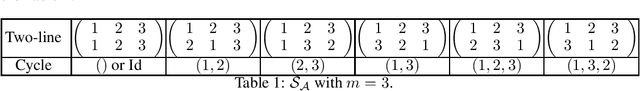
We introduce a notion of fairest tie-breaking for voting w.r.t. two widely-accepted fairness criteria: anonymity (all voters being treated equally) and neutrality (all alternatives being treated equally). We proposed a polynomial-time computable fairest tie-breaking mechanism, called most-favorable-permutation (MFP) breaking, for a wide range of decision spaces, including single winners, $k$-committees, $k$-lists, and full rankings. We characterize the semi-random fairness of commonly-studied voting rules with MFP breaking, showing that it is significantly better than existing tie-breaking mechanisms, including the commonly-used lexicographic and fixed-agent mechanisms.
Anti-Malware Sandbox Games
Feb 28, 2022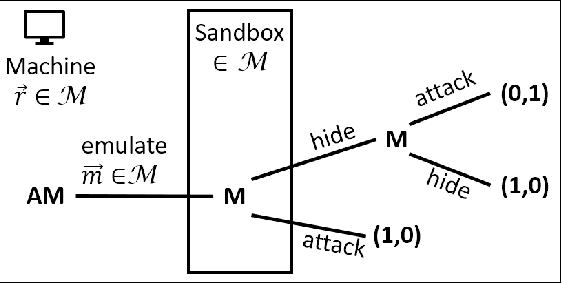


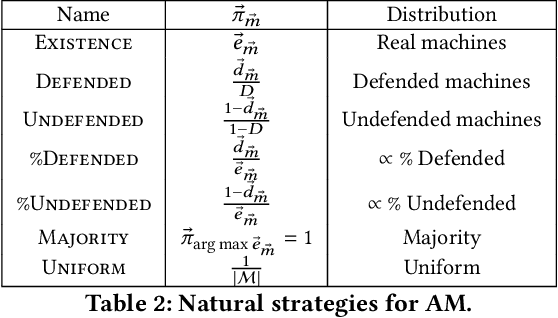
We develop a game theoretic model of malware protection using the state-of-the-art sandbox method, to characterize and compute optimal defense strategies for anti-malware. We model the strategic interaction between developers of malware (M) and anti-malware (AM) as a two player game, where AM commits to a strategy of generating sandbox environments, and M responds by choosing to either attack or hide malicious activity based on the environment it senses. We characterize the condition for AM to protect all its machines, and identify conditions under which an optimal AM strategy can be computed efficiently. For other cases, we provide a quadratically constrained quadratic program (QCQP)-based optimization framework to compute the optimal AM strategy. In addition, we identify a natural and easy to compute strategy for AM, which as we show empirically, achieves AM utility that is close to the optimal AM utility, in equilibrium.
How Likely A Coalition of Voters Can Influence A Large Election?
Feb 13, 2022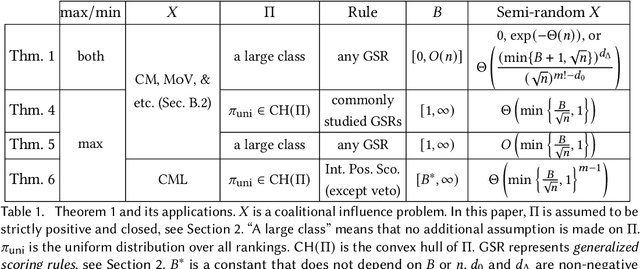
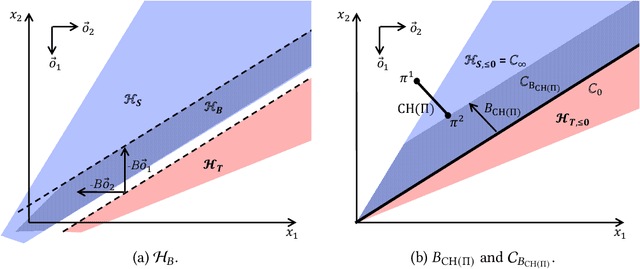
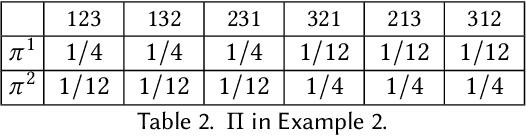
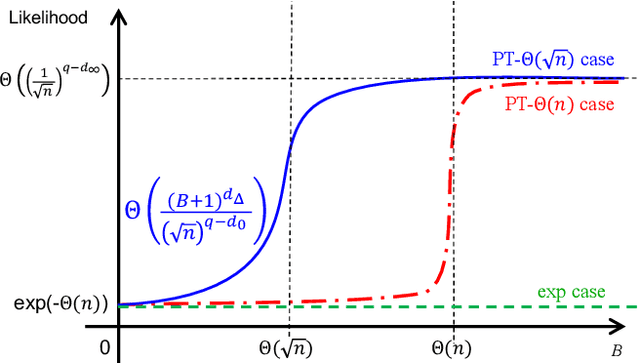
For centuries, it has been widely believed that the influence of a small coalition of voters is negligible in a large election. Consequently, there is a large body of literature on characterizing the asymptotic likelihood for an election to be influence, especially by the manipulation of a single voter, establishing an $O(\frac{1}{\sqrt n})$ upper bound and an $\Omega(\frac{1}{n^{67}})$ lower bound for many commonly studied voting rules under the i.i.d.~uniform distribution, known as Impartial Culture (IC) in social choice, where $n$ is the number is voters. In this paper, we extend previous studies in three aspects: (1) we consider a more general and realistic semi-random model that resembles the model in smoothed analysis, (2) we consider many coalitional influence problems, including coalitional manipulation, margin of victory, and various vote controls and bribery, and (3) we consider arbitrary and variable coalition size $B$. Our main theorem provides asymptotically tight bounds on the semi-random likelihood of the existence of a size-$B$ coalition that can successfully influence the election under a wide range of voting rules. Applications of the main theorem and its proof techniques resolve long-standing open questions about the likelihood of coalitional manipulability under IC, by showing that the likelihood is $\Theta\left(\min\left\{\frac{B}{\sqrt n}, 1\right\}\right)$ for many commonly studied voting rules. The main technical contribution is a characterization of the semi-random likelihood for a Poisson multinomial variable (PMV) to be unstable, which we believe to be a general and useful technique with independent interest.