 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffFNO: Diffusion Fourier Neural Operator
Nov 15, 2024We introduce DiffFNO, a novel diffusion framework for arbitrary-scale super-resolution strengthened by a Weighted Fourier Neural Operator (WFNO). Mode Re-balancing in WFNO effectively captures critical frequency components, significantly improving the reconstruction of high-frequency image details that are crucial for super-resolution tasks. Gated Fusion Mechanism (GFM) adaptively complements WFNO's spectral features with spatial features from an Attention-based Neural Operator (AttnNO). This enhances the network's capability to capture both global structures and local details. Adaptive Time-Step (ATS) ODE solver, a deterministic sampling strategy, accelerates inference without sacrificing output quality by dynamically adjusting integration step sizes ATS. Extensive experiments demonstrate that DiffFNO achieves state-of-the-art (SOTA) results, outperforming existing methods across various scaling factors by a margin of 2 to 4 dB in PSNR, including those beyond the training distribution. It also achieves this at lower inference time. Our approach sets a new standard in super-resolution, delivering both superior accuracy and computational efficiency.
Layer-Wise Feature Metric of Semantic-Pixel Matching for Few-Shot Learning
Nov 10, 2024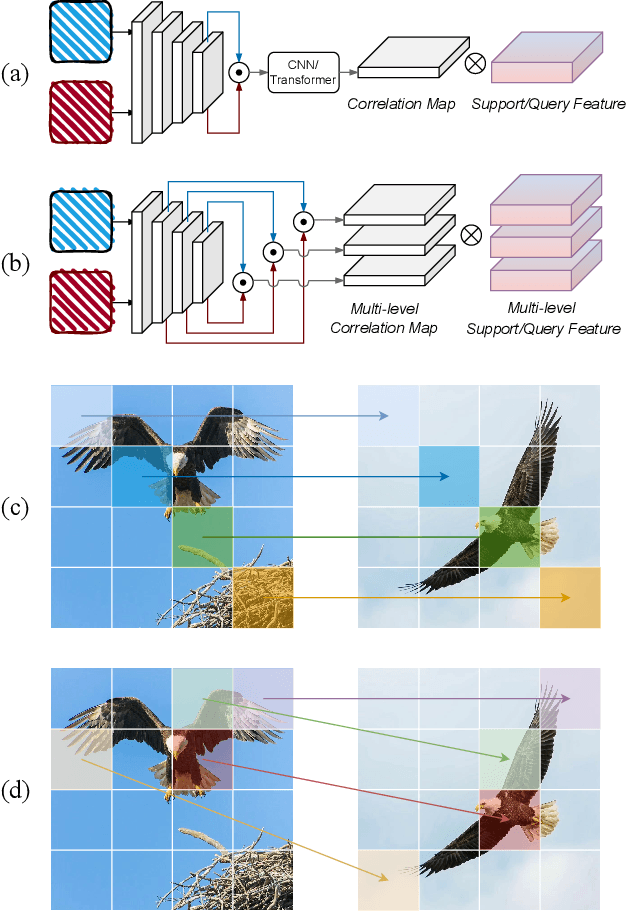
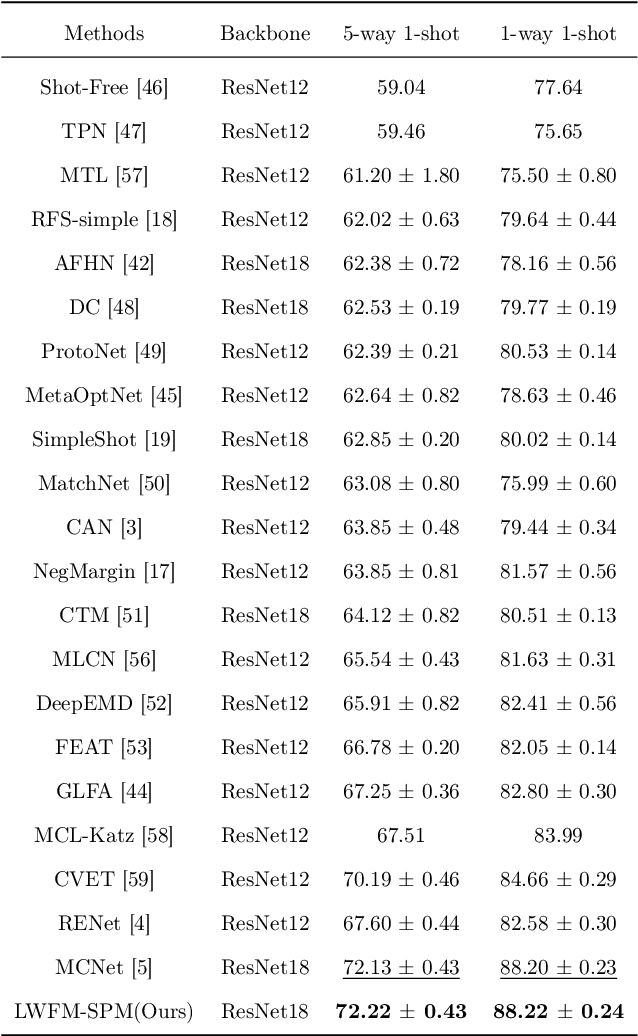
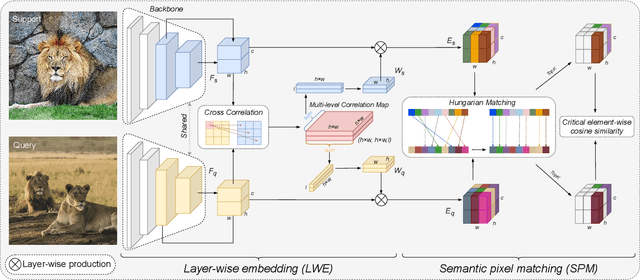
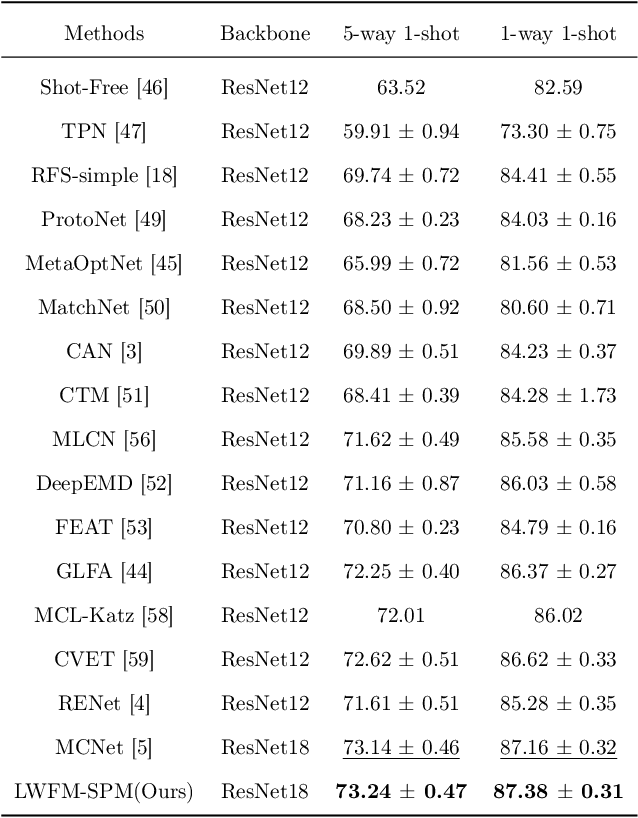
In Few-Shot Learning (FSL), traditional metric-based approaches often rely on global metrics to compute similarity. However, in natural scenes, the spatial arrangement of key instances is often inconsistent across images. This spatial misalignment can result in mismatched semantic pixels, leading to inaccurate similarity measurements. To address this issue, we propose a novel method called the Layer-Wise Features Metric of Semantic-Pixel Matching (LWFM-SPM) to make finer comparisons. Our method enhances model performance through two key modules: (1) the Layer-Wise Embedding (LWE) Module, which refines the cross-correlation of image pairs to generate well-focused feature maps for each layer; (2)the Semantic-Pixel Matching (SPM) Module, which aligns critical pixels based on semantic embeddings using an assignment algorithm. We conducted extensive experiments to evaluate our method on four widely used few-shot classification benchmarks: miniImageNet, tieredImageNet, CUB-200-2011, and CIFAR-FS. The results indicate that LWFM-SPM achieves competitive performance across these benchmarks. Our code will be publicly available on https://github.com/Halo2Tang/Code-for-LWFM-SPM.
KMM: Key Frame Mask Mamba for Extended Motion Generation
Nov 10, 2024Human motion generation is a cut-edge area of research in generative computer vision, with promising applications in video creation, game development, and robotic manipulation. The recent Mamba architecture shows promising results in efficiently modeling long and complex sequences, yet two significant challenges remain: Firstly, directly applying Mamba to extended motion generation is ineffective, as the limited capacity of the implicit memory leads to memory decay. Secondly, Mamba struggles with multimodal fusion compared to Transformers, and lack alignment with textual queries, often confusing directions (left or right) or omitting parts of longer text queries. To address these challenges, our paper presents three key contributions: Firstly, we introduce KMM, a novel architecture featuring Key frame Masking Modeling, designed to enhance Mamba's focus on key actions in motion segments. This approach addresses the memory decay problem and represents a pioneering method in customizing strategic frame-level masking in SSMs. Additionally, we designed a contrastive learning paradigm for addressing the multimodal fusion problem in Mamba and improving the motion-text alignment. Finally, we conducted extensive experiments on the go-to dataset, BABEL, achieving state-of-the-art performance with a reduction of more than 57% in FID and 70% parameters compared to previous state-of-the-art methods. See project website: https://steve-zeyu-zhang.github.io/KMM
Combining Induction and Transduction for Abstract Reasoning
Nov 04, 2024When learning an input-output mapping from very few examples, is it better to first infer a latent function that explains the examples, or is it better to directly predict new test outputs, e.g. using a neural network? We study this question on ARC, a highly diverse dataset of abstract reasoning tasks. We train neural models for induction (inferring latent functions) and transduction (directly predicting the test output for a given test input). Our models are trained on synthetic data generated by prompting LLMs to produce Python code specifying a function to be inferred, plus a stochastic subroutine for generating inputs to that function. We find inductive and transductive models solve very different problems, despite training on the same problems, and despite sharing the same neural architecture.
GWQ: Gradient-Aware Weight Quantization for Large Language Models
Oct 30, 2024



Large language models (LLMs) show impressive performance in solving complex languagetasks. However, its large number of parameterspresent significant challenges for the deployment and application of the model on edge devices. Compressing large language models to low bits can enable them to run on resource-constrained devices, often leading to performance degradation. To address this problem, we propose gradient-aware weight quantization (GWQ), the first quantization approach for low-bit weight quantization that leverages gradients to localize outliers, requiring only a minimal amount of calibration data for outlier detection. GWQ retains the weights corresponding to the top 1% outliers preferentially at FP16 precision, while the remaining non-outlier weights are stored in a low-bit format. GWQ found experimentally that utilizing the sensitive weights in the gradient localization model is more scientific compared to utilizing the sensitive weights in the Hessian matrix localization model. Compared to current quantization methods, GWQ can be applied to multiple language models and achieves lower PPL on the WikiText2 and C4 dataset. In the zero-shot task, GWQ quantized models have higher accuracy compared to other quantization methods.GWQ is also suitable for multimodal model quantization, and the quantized Qwen-VL family model is more accurate than other methods. zero-shot target detection task dataset RefCOCO outperforms the current stat-of-the-arts method SPQR. GWQ achieves 1.2x inference speedup in comparison to the original model, and effectively reduces the inference memory.
VisualPredicator: Learning Abstract World Models with Neuro-Symbolic Predicates for Robot Planning
Oct 30, 2024



Broadly intelligent agents should form task-specific abstractions that selectively expose the essential elements of a task, while abstracting away the complexity of the raw sensorimotor space. In this work, we present Neuro-Symbolic Predicates, a first-order abstraction language that combines the strengths of symbolic and neural knowledge representations. We outline an online algorithm for inventing such predicates and learning abstract world models. We compare our approach to hierarchical reinforcement learning, vision-language model planning, and symbolic predicate invention approaches, on both in- and out-of-distribution tasks across five simulated robotic domains. Results show that our approach offers better sample complexity, stronger out-of-distribution generalization, and improved interpretability.
MobA: A Two-Level Agent System for Efficient Mobile Task Automation
Oct 17, 2024



Current mobile assistants are limited by dependence on system APIs or struggle with complex user instructions and diverse interfaces due to restricted comprehension and decision-making abilities. To address these challenges, we propose MobA, a novel Mobile phone Agent powered by multimodal large language models that enhances comprehension and planning capabilities through a sophisticated two-level agent architecture. The high-level Global Agent (GA) is responsible for understanding user commands, tracking history memories, and planning tasks. The low-level Local Agent (LA) predicts detailed actions in the form of function calls, guided by sub-tasks and memory from the GA. Integrating a Reflection Module allows for efficient task completion and enables the system to handle previously unseen complex tasks. MobA demonstrates significant improvements in task execution efficiency and completion rate in real-life evaluations, underscoring the potential of MLLM-empowered mobile assistants.
Cavia: Camera-controllable Multi-view Video Diffusion with View-Integrated Attention
Oct 14, 2024In recent years there have been remarkable breakthroughs in image-to-video generation. However, the 3D consistency and camera controllability of generated frames have remained unsolved. Recent studies have attempted to incorporate camera control into the generation process, but their results are often limited to simple trajectories or lack the ability to generate consistent videos from multiple distinct camera paths for the same scene. To address these limitations, we introduce Cavia, a novel framework for camera-controllable, multi-view video generation, capable of converting an input image into multiple spatiotemporally consistent videos. Our framework extends the spatial and temporal attention modules into view-integrated attention modules, improving both viewpoint and temporal consistency. This flexible design allows for joint training with diverse curated data sources, including scene-level static videos, object-level synthetic multi-view dynamic videos, and real-world monocular dynamic videos. To our best knowledge, Cavia is the first of its kind that allows the user to precisely specify camera motion while obtaining object motion. Extensive experiments demonstrate that Cavia surpasses state-of-the-art methods in terms of geometric consistency and perceptual quality. Project Page: https://ir1d.github.io/Cavia/
VerifierQ: Enhancing LLM Test Time Compute with Q-Learning-based Verifiers
Oct 10, 2024



Recent advancements in test time compute, particularly through the use of verifier models, have significantly enhanced the reasoning capabilities of Large Language Models (LLMs). This generator-verifier approach closely resembles the actor-critic framework in reinforcement learning (RL). However, current verifier models in LLMs often rely on supervised fine-tuning without temporal difference learning such as Q-learning. This paper introduces VerifierQ, a novel approach that integrates Offline Q-learning into LLM verifier models. We address three key challenges in applying Q-learning to LLMs: (1) handling utterance-level Markov Decision Processes (MDPs), (2) managing large action spaces, and (3) mitigating overestimation bias. VerifierQ introduces a modified Bellman update for bounded Q-values, incorporates Implicit Q-learning (IQL) for efficient action space management, and integrates a novel Conservative Q-learning (CQL) formulation for balanced Q-value estimation. Our method enables parallel Q-value computation and improving training efficiency. While recent work has explored RL techniques like MCTS for generators, VerifierQ is among the first to investigate the verifier (critic) aspect in LLMs through Q-learning. This integration of RL principles into verifier models complements existing advancements in generator techniques, potentially enabling more robust and adaptive reasoning in LLMs. Experimental results on mathematical reasoning tasks demonstrate VerifierQ's superior performance compared to traditional supervised fine-tuning approaches, with improvements in efficiency, accuracy and robustness. By enhancing the synergy between generation and evaluation capabilities, VerifierQ contributes to the ongoing evolution of AI systems in addressing complex cognitive tasks across various domains.
OmniPose6D: Towards Short-Term Object Pose Tracking in Dynamic Scenes from Monocular RGB
Oct 09, 2024



To address the challenge of short-term object pose tracking in dynamic environments with monocular RGB input, we introduce a large-scale synthetic dataset OmniPose6D, crafted to mirror the diversity of real-world conditions. We additionally present a benchmarking framework for a comprehensive comparison of pose tracking algorithms. We propose a pipeline featuring an uncertainty-aware keypoint refinement network, employing probabilistic modeling to refine pose estimation. Comparative evaluations demonstrate that our approach achieves performance superior to existing baselines on real datasets, underscoring the effectiveness of our synthetic dataset and refinement technique in enhancing tracking precision in dynamic contexts. Our contributions set a new precedent for the development and assessment of object pose tracking methodologies in complex scenes.