 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePokerSkill: LLMs Can Play Expert-Level Poker without Training or Solvers
May 28, 2026Poker is a landmark challenge for artificial intelligence. The dominant approach relies on equilibrium solvers built on counterfactual regret minimization, requiring millions of core-hours of training. Large Language Models (LLMs) possess extensive poker knowledge but perform far below solver-based agents when asked to play directly. Traditional rule-based poker agents are interpretable and training-free, but their strategic ceiling remains far below equilibrium play. We introduce \textbf{PokerSkill}, a training-free and solver-free framework that bridges this gap by using detailed rule-based poker skills as a structured action-grounding interface for LLMs. A deterministic context engine analyzes the current state and retrieves only the relevant fragments from a layered skill library, which is entirely designed by human poker experts, constraining the LLM's choice to reasonable actions. Against GTOWizard, a state-of-the-art GTO benchmark, GPT-5.5 XHigh with PokerSkill achieves $-57 \pm 21$ mbb/hand, Claude Opus 4.6 achieves $-80 \pm 29$ mbb/hand and Claude Opus 4.7 achieves $-87\pm 64$ mbb/hand, reducing losses by 49--61\% compared to default-prompt baselines and outperforming the strong bot Slumbot. Our key finding is that rule-based skills alone do not constitute a strong strategy, and LLMs alone cannot play well, but their combination yields an agent that requires neither training nor solver access yet competes with systems built on millions of core-hours of computation. To our knowledge, this is the first demonstration of an LLM achieving competitive performance in a complex imperfect-information game without game-specific training or solver queries. Code is available at https://github.com/lbn187/PokerSkill.
Real-Time Parallel Counterfactual Regret Minimization
May 19, 2026Counterfactual Regret Minimization (CFR) is the dominant algorithmic family for solving large imperfect-information games, underpinning breakthroughs such as Libratus and Pluribus in No-Limit Texas Hold'em poker. In real-time game-playing systems, the solver must compute a near-equilibrium strategy within a strict time budget of only a few seconds per decision, and the number of CFR iterations completed in this window directly determines play strength. We present \textbf{Parallel CFR}, the first parallelization framework for real-time depth-limited CFR solving that seamlessly integrates pruning, abstraction, and advanced CFR variants. We decompose each CFR iteration into a pipeline of seven stages and identify two orthogonal dimensions of parallelism: \emph{by information set} and \emph{by tree node}. Leaf node evaluation is offloaded to GPUs via batched neural network inference, creating a heterogeneous CPU--GPU pipeline. Experiments on Heads-Up No-Limit Texas Hold'em demonstrate that Parallel CFR achieves $3.3$--$3.4\times$ speedup over the single-threaded baseline on postflop streets, with per-iteration time of ${\sim}47$--$54$~ms on a depth-limited game tree with over $1$ billion histories. All experiments run on a single desktop-class device (NVIDIA DGX Spark), enabling hundreds of CFR iterations within a typical real-time decision budget without requiring datacenter-scale infrastructure.
RL-CFR: Improving Action Abstraction for Imperfect Information Extensive-Form Games with Reinforcement Learning
Mar 07, 2024Effective action abstraction is crucial in tackling challenges associated with large action spaces in Imperfect Information Extensive-Form Games (IIEFGs). However, due to the vast state space and computational complexity in IIEFGs, existing methods often rely on fixed abstractions, resulting in sub-optimal performance. In response, we introduce RL-CFR, a novel reinforcement learning (RL) approach for dynamic action abstraction. RL-CFR builds upon our innovative Markov Decision Process (MDP) formulation, with states corresponding to public information and actions represented as feature vectors indicating specific action abstractions. The reward is defined as the expected payoff difference between the selected and default action abstractions. RL-CFR constructs a game tree with RL-guided action abstractions and utilizes counterfactual regret minimization (CFR) for strategy derivation. Impressively, it can be trained from scratch, achieving higher expected payoff without increased CFR solving time. In experiments on Heads-up No-limit Texas Hold'em, RL-CFR outperforms ReBeL's replication and Slumbot, demonstrating significant win-rate margins of $64\pm 11$ and $84\pm 17$ mbb/hand, respectively.
Blind quantum machine learning with quantum bipartite correlator
Oct 19, 2023



Distributed quantum computing is a promising computational paradigm for performing computations that are beyond the reach of individual quantum devices. Privacy in distributed quantum computing is critical for maintaining confidentiality and protecting the data in the presence of untrusted computing nodes. In this work, we introduce novel blind quantum machine learning protocols based on the quantum bipartite correlator algorithm. Our protocols have reduced communication overhead while preserving the privacy of data from untrusted parties. We introduce robust algorithm-specific privacy-preserving mechanisms with low computational overhead that do not require complex cryptographic techniques. We then validate the effectiveness of the proposed protocols through complexity and privacy analysis. Our findings pave the way for advancements in distributed quantum computing, opening up new possibilities for privacy-aware machine learning applications in the era of quantum technologies.
Deep Demixing: Reconstructing the Evolution of Network Epidemics
Jun 11, 2023We propose the deep demixing (DDmix) model, a graph autoencoder that can reconstruct epidemics evolving over networks from partial or aggregated temporal information. Assuming knowledge of the network topology but not of the epidemic model, our goal is to estimate the complete propagation path of a disease spread. A data-driven approach is leveraged to overcome the lack of model awareness. To solve this inverse problem, DDmix is proposed as a graph conditional variational autoencoder that is trained from past epidemic spreads. DDmix seeks to capture key aspects of the underlying (unknown) spreading dynamics in its latent space. Using epidemic spreads simulated in synthetic and real-world networks, we demonstrate the accuracy of DDmix by comparing it with multiple (non-graph-aware) learning algorithms. The generalizability of DDmix is highlighted across different types of networks. Finally, we showcase that a simple post-processing extension of our proposed method can help identify super-spreaders in the reconstructed propagation path.
Learnable Digital Twin for Efficient Wireless Network Evaluation
Jun 11, 2023Network digital twins (NDTs) facilitate the estimation of key performance indicators (KPIs) before physically implementing a network, thereby enabling efficient optimization of the network configuration. In this paper, we propose a learning-based NDT for network simulators. The proposed method offers a holistic representation of information flow in a wireless network by integrating node, edge, and path embeddings. Through this approach, the model is trained to map the network configuration to KPIs in a single forward pass. Hence, it offers a more efficient alternative to traditional simulation-based methods, thus allowing for rapid experimentation and optimization. Our proposed method has been extensively tested through comprehensive experimentation in various scenarios, including wired and wireless networks. Results show that it outperforms baseline learning models in terms of accuracy and robustness. Moreover, our approach achieves comparable performance to simulators but with significantly higher computational efficiency.
Hypergraphs with Edge-Dependent Vertex Weights: Spectral Clustering based on the 1-Laplacian
Apr 30, 2023We propose a flexible framework for defining the 1-Laplacian of a hypergraph that incorporates edge-dependent vertex weights. These weights are able to reflect varying importance of vertices within a hyperedge, thus conferring the hypergraph model higher expressivity than homogeneous hypergraphs. We then utilize the eigenvector associated with the second smallest eigenvalue of the hypergraph 1-Laplacian to cluster the vertices. From a theoretical standpoint based on an adequately defined normalized Cheeger cut, this procedure is expected to achieve higher clustering accuracy than that based on the traditional Laplacian. Indeed, we confirm that this is the case using real-world datasets to demonstrate the effectiveness of the proposed spectral clustering approach. Moreover, we show that for a special case within our framework, the corresponding hypergraph 1-Laplacian is equivalent to the 1-Laplacian of a related graph, whose eigenvectors can be computed more efficiently, facilitating the adoption on larger datasets.
Learning to Transmit with Provable Guarantees in Wireless Federated Learning
Apr 18, 2023We propose a novel data-driven approach to allocate transmit power for federated learning (FL) over interference-limited wireless networks. The proposed method is useful in challenging scenarios where the wireless channel is changing during the FL training process and when the training data are not independent and identically distributed (non-i.i.d.) on the local devices. Intuitively, the power policy is designed to optimize the information received at the server end during the FL process under communication constraints. Ultimately, our goal is to improve the accuracy and efficiency of the global FL model being trained. The proposed power allocation policy is parameterized using a graph convolutional network and the associated constrained optimization problem is solved through a primal-dual (PD) algorithm. Theoretically, we show that the formulated problem has zero duality gap and, once the power policy is parameterized, optimality depends on how expressive this parameterization is. Numerically, we demonstrate that the proposed method outperforms existing baselines under different wireless channel settings and varying degrees of data heterogeneity.
Graph-based Algorithm Unfolding for Energy-aware Power Allocation in Wireless Networks
Jan 27, 2022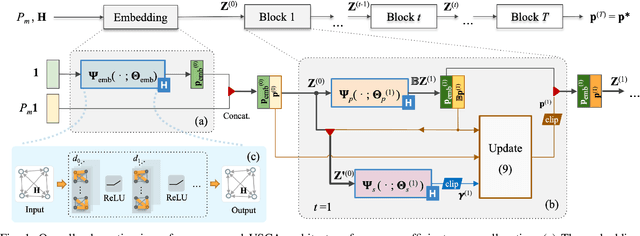
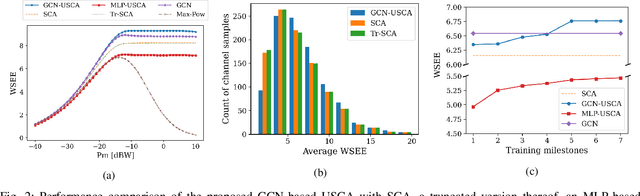
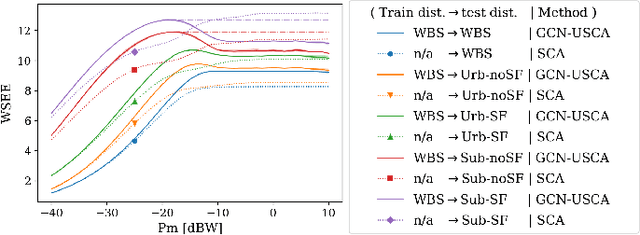
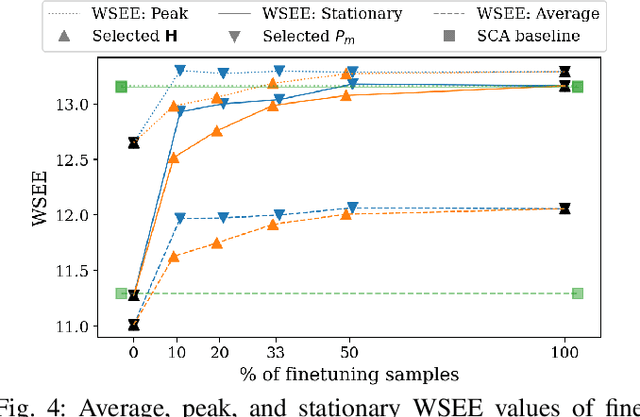
We develop a novel graph-based trainable framework to maximize the weighted sum energy efficiency (WSEE) for power allocation in wireless communication networks. To address the non-convex nature of the problem, the proposed method consists of modular structures inspired by a classical iterative suboptimal approach and enhanced with learnable components. More precisely, we propose a deep unfolding of the successive concave approximation (SCA) method. In our unfolded SCA (USCA) framework, the originally preset parameters are now learnable via graph convolutional neural networks (GCNs) that directly exploit multi-user channel state information as the underlying graph adjacency matrix. We show the permutation equivariance of the proposed architecture, which promotes generalizability across different network topologies of varying size, density, and channel distribution. The USCA framework is trained through a stochastic gradient descent approach using a progressive training strategy. The unsupervised loss is carefully devised to feature the monotonic property of the objective under maximum power constraints. Comprehensive numerical results demonstrate outstanding performance and robustness of USCA over state-of-the-art benchmarks.
Power Allocation for Wireless Federated Learning using Graph Neural Networks
Nov 15, 2021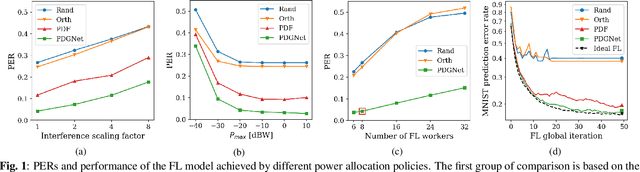
We propose a data-driven approach for power allocation in the context of federated learning (FL) over interference-limited wireless networks. The power policy is designed to maximize the transmitted information during the FL process under communication constraints, with the ultimate objective of improving the accuracy and efficiency of the global FL model being trained. The proposed power allocation policy is parameterized using a graph convolutional network and the associated constrained optimization problem is solved through a primal-dual algorithm. Numerical experiments show that the proposed method outperforms three baseline methods in both transmission success rate and FL global performance.