 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Framework for Provably Efficient Algorithms to Estimate Shapley Values
Jun 05, 2025Shapley values have emerged as a critical tool for explaining which features impact the decisions made by machine learning models. However, computing exact Shapley values is difficult, generally requiring an exponential (in the feature dimension) number of model evaluations. To address this, many model-agnostic randomized estimators have been developed, the most influential and widely used being the KernelSHAP method (Lundberg & Lee, 2017). While related estimators such as unbiased KernelSHAP (Covert & Lee, 2021) and LeverageSHAP (Musco & Witter, 2025) are known to satisfy theoretical guarantees, bounds for KernelSHAP have remained elusive. We describe a broad and unified framework that encompasses KernelSHAP and related estimators constructed using both with and without replacement sampling strategies. We then prove strong non-asymptotic theoretical guarantees that apply to all estimators from our framework. This provides, to the best of our knowledge, the first theoretical guarantees for KernelSHAP and sheds further light on tradeoffs between existing estimators. Through comprehensive benchmarking on small and medium dimensional datasets for Decision-Tree models, we validate our approach against exact Shapley values, consistently achieving low mean squared error with modest sample sizes. Furthermore, we make specific implementation improvements to enable scalability of our methods to high-dimensional datasets. Our methods, tested on datasets such MNIST and CIFAR10, provide consistently better results compared to the KernelSHAP library.
Prospects of Privacy Advantage in Quantum Machine Learning
May 15, 2024



Ensuring data privacy in machine learning models is critical, particularly in distributed settings where model gradients are typically shared among multiple parties to allow collaborative learning. Motivated by the increasing success of recovering input data from the gradients of classical models, this study addresses a central question: How hard is it to recover the input data from the gradients of quantum machine learning models? Focusing on variational quantum circuits (VQC) as learning models, we uncover the crucial role played by the dynamical Lie algebra (DLA) of the VQC ansatz in determining privacy vulnerabilities. While the DLA has previously been linked to the classical simulatability and trainability of VQC models, this work, for the first time, establishes its connection to the privacy of VQC models. In particular, we show that properties conducive to the trainability of VQCs, such as a polynomial-sized DLA, also facilitate the extraction of detailed snapshots of the input. We term this a weak privacy breach, as the snapshots enable training VQC models for distinct learning tasks without direct access to the original input. Further, we investigate the conditions for a strong privacy breach where the original input data can be recovered from these snapshots by classical or quantum-assisted polynomial time methods. We establish conditions on the encoding map such as classical simulatability, overlap with DLA basis, and its Fourier frequency characteristics that enable such a privacy breach of VQC models. Our findings thus play a crucial role in detailing the prospects of quantum privacy advantage by guiding the requirements for designing quantum machine learning models that balance trainability with robust privacy protection.
Privacy-preserving quantum federated learning via gradient hiding
Dec 07, 2023Distributed quantum computing, particularly distributed quantum machine learning, has gained substantial prominence for its capacity to harness the collective power of distributed quantum resources, transcending the limitations of individual quantum nodes. Meanwhile, the critical concern of privacy within distributed computing protocols remains a significant challenge, particularly in standard classical federated learning (FL) scenarios where data of participating clients is susceptible to leakage via gradient inversion attacks by the server. This paper presents innovative quantum protocols with quantum communication designed to address the FL problem, strengthen privacy measures, and optimize communication efficiency. In contrast to previous works that leverage expressive variational quantum circuits or differential privacy techniques, we consider gradient information concealment using quantum states and propose two distinct FL protocols, one based on private inner-product estimation and the other on incremental learning. These protocols offer substantial advancements in privacy preservation with low communication resources, forging a path toward efficient quantum communication-assisted FL protocols and contributing to the development of secure distributed quantum machine learning, thus addressing critical privacy concerns in the quantum computing era.
Blind quantum machine learning with quantum bipartite correlator
Oct 19, 2023



Distributed quantum computing is a promising computational paradigm for performing computations that are beyond the reach of individual quantum devices. Privacy in distributed quantum computing is critical for maintaining confidentiality and protecting the data in the presence of untrusted computing nodes. In this work, we introduce novel blind quantum machine learning protocols based on the quantum bipartite correlator algorithm. Our protocols have reduced communication overhead while preserving the privacy of data from untrusted parties. We introduce robust algorithm-specific privacy-preserving mechanisms with low computational overhead that do not require complex cryptographic techniques. We then validate the effectiveness of the proposed protocols through complexity and privacy analysis. Our findings pave the way for advancements in distributed quantum computing, opening up new possibilities for privacy-aware machine learning applications in the era of quantum technologies.
Quantum Deep Hedging
Mar 29, 2023



Quantum machine learning has the potential for a transformative impact across industry sectors and in particular in finance. In our work we look at the problem of hedging where deep reinforcement learning offers a powerful framework for real markets. We develop quantum reinforcement learning methods based on policy-search and distributional actor-critic algorithms that use quantum neural network architectures with orthogonal and compound layers for the policy and value functions. We prove that the quantum neural networks we use are trainable, and we perform extensive simulations that show that quantum models can reduce the number of trainable parameters while achieving comparable performance and that the distributional approach obtains better performance than other standard approaches, both classical and quantum. We successfully implement the proposed models on a trapped-ion quantum processor, utilizing circuits with up to $16$ qubits, and observe performance that agrees well with noiseless simulation. Our quantum techniques are general and can be applied to other reinforcement learning problems beyond hedging.
Analyzing Convergence in Quantum Neural Networks: Deviations from Neural Tangent Kernels
Mar 26, 2023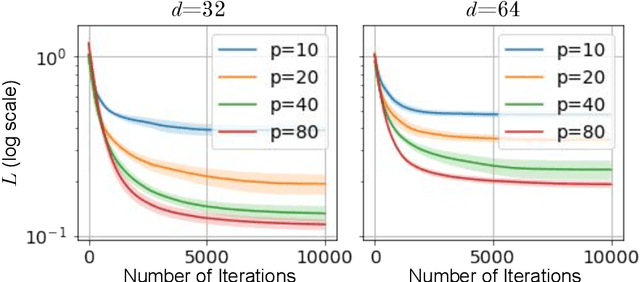
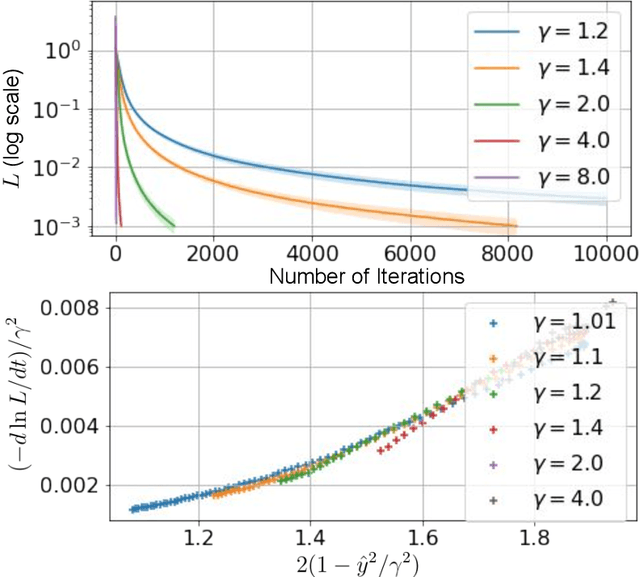
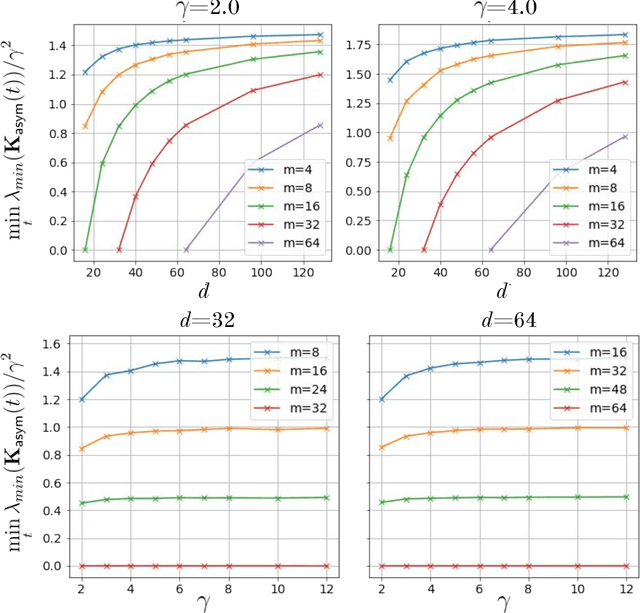
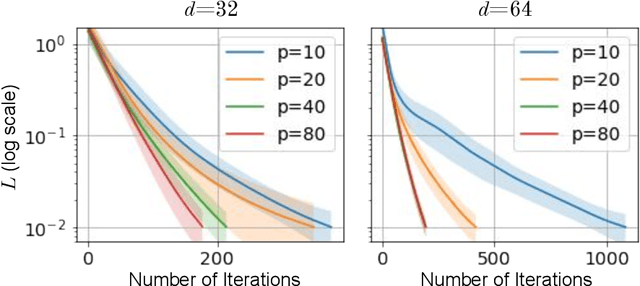
A quantum neural network (QNN) is a parameterized mapping efficiently implementable on near-term Noisy Intermediate-Scale Quantum (NISQ) computers. It can be used for supervised learning when combined with classical gradient-based optimizers. Despite the existing empirical and theoretical investigations, the convergence of QNN training is not fully understood. Inspired by the success of the neural tangent kernels (NTKs) in probing into the dynamics of classical neural networks, a recent line of works proposes to study over-parameterized QNNs by examining a quantum version of tangent kernels. In this work, we study the dynamics of QNNs and show that contrary to popular belief it is qualitatively different from that of any kernel regression: due to the unitarity of quantum operations, there is a non-negligible deviation from the tangent kernel regression derived at the random initialization. As a result of the deviation, we prove the at-most sublinear convergence for QNNs with Pauli measurements, which is beyond the explanatory power of any kernel regression dynamics. We then present the actual dynamics of QNNs in the limit of over-parameterization. The new dynamics capture the change of convergence rate during training and implies that the range of measurements is crucial to the fast QNN convergence.
Numerical evidence against advantage with quantum fidelity kernels on classical data
Nov 29, 2022



Quantum machine learning techniques are commonly considered one of the most promising candidates for demonstrating practical quantum advantage. In particular, quantum kernel methods have been demonstrated to be able to learn certain classically intractable functions efficiently if the kernel is well-aligned with the target function. In the more general case, quantum kernels are known to suffer from exponential "flattening" of the spectrum as the number of qubits grows, preventing generalization and necessitating the control of the inductive bias by hyperparameters. We show that the general-purpose hyperparameter tuning techniques proposed to improve the generalization of quantum kernels lead to the kernel becoming well-approximated by a classical kernel, removing the possibility of quantum advantage. We provide extensive numerical evidence for this phenomenon utilizing multiple previously studied quantum feature maps and both synthetic and real data. Our results show that unless novel techniques are developed to control the inductive bias of quantum kernels, they are unlikely to provide a quantum advantage on classical data.
A Convergence Theory for Over-parameterized Variational Quantum Eigensolvers
May 25, 2022
The Variational Quantum Eigensolver (VQE) is a promising candidate for quantum applications on near-term Noisy Intermediate-Scale Quantum (NISQ) computers. Despite a lot of empirical studies and recent progress in theoretical understanding of VQE's optimization landscape, the convergence for optimizing VQE is far less understood. We provide the first rigorous analysis of the convergence of VQEs in the over-parameterization regime. By connecting the training dynamics with the Riemannian Gradient Flow on the unit-sphere, we establish a threshold on the sufficient number of parameters for efficient convergence, which depends polynomially on the system dimension and the spectral ratio, a property of the problem Hamiltonian, and could be resilient to gradient noise to some extent. We further illustrate that this overparameterization threshold could be vastly reduced for specific VQE instances by establishing an ansatz-dependent threshold paralleling our main result. We showcase that our ansatz-dependent threshold could serve as a proxy of the trainability of different VQE ansatzes without performing empirical experiments, which hence leads to a principled way of evaluating ansatz design. Finally, we conclude with a comprehensive empirical study that supports our theoretical findings.
Quantum Machine Learning for Finance
Sep 09, 2021Quantum computers are expected to surpass the computational capabilities of classical computers during this decade, and achieve disruptive impact on numerous industry sectors, particularly finance. In fact, finance is estimated to be the first industry sector to benefit from Quantum Computing not only in the medium and long terms, but even in the short term. This review paper presents the state of the art of quantum algorithms for financial applications, with particular focus to those use cases that can be solved via Machine Learning.
Sublinear classical and quantum algorithms for general matrix games
Dec 11, 2020
We investigate sublinear classical and quantum algorithms for matrix games, a fundamental problem in optimization and machine learning, with provable guarantees. Given a matrix $A\in\mathbb{R}^{n\times d}$, sublinear algorithms for the matrix game $\min_{x\in\mathcal{X}}\max_{y\in\mathcal{Y}} y^{\top} Ax$ were previously known only for two special cases: (1) $\mathcal{Y}$ being the $\ell_{1}$-norm unit ball, and (2) $\mathcal{X}$ being either the $\ell_{1}$- or the $\ell_{2}$-norm unit ball. We give a sublinear classical algorithm that can interpolate smoothly between these two cases: for any fixed $q\in (1,2]$, we solve the matrix game where $\mathcal{X}$ is a $\ell_{q}$-norm unit ball within additive error $\epsilon$ in time $\tilde{O}((n+d)/{\epsilon^{2}})$. We also provide a corresponding sublinear quantum algorithm that solves the same task in time $\tilde{O}((\sqrt{n}+\sqrt{d})\textrm{poly}(1/\epsilon))$ with a quadratic improvement in both $n$ and $d$. Both our classical and quantum algorithms are optimal in the dimension parameters $n$ and $d$ up to poly-logarithmic factors. Finally, we propose sublinear classical and quantum algorithms for the approximate Carath\'eodory problem and the $\ell_{q}$-margin support vector machines as applications.