 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallucination Begins Where Saliency Drops
Jan 28, 2026Recent studies have examined attention dynamics in large vision-language models (LVLMs) to detect hallucinations. However, existing approaches remain limited in reliably distinguishing hallucinated from factually grounded outputs, as they rely solely on forward-pass attention patterns and neglect gradient-based signals that reveal how token influence propagates through the network. To bridge this gap, we introduce LVLMs-Saliency, a gradient-aware diagnostic framework that quantifies the visual grounding strength of each output token by fusing attention weights with their input gradients. Our analysis uncovers a decisive pattern: hallucinations frequently arise when preceding output tokens exhibit low saliency toward the prediction of the next token, signaling a breakdown in contextual memory retention. Leveraging this insight, we propose a dual-mechanism inference-time framework to mitigate hallucinations: (1) Saliency-Guided Rejection Sampling (SGRS), which dynamically filters candidate tokens during autoregressive decoding by rejecting those whose saliency falls below a context-adaptive threshold, thereby preventing coherence-breaking tokens from entering the output sequence; and (2) Local Coherence Reinforcement (LocoRE), a lightweight, plug-and-play module that strengthens attention from the current token to its most recent predecessors, actively counteracting the contextual forgetting behavior identified by LVLMs-Saliency. Extensive experiments across multiple LVLMs demonstrate that our method significantly reduces hallucination rates while preserving fluency and task performance, offering a robust and interpretable solution for enhancing model reliability. Code is available at: https://github.com/zhangbaijin/LVLMs-Saliency
Seeing Clearly by Layer Two: Enhancing Attention Heads to Alleviate Hallucination in LVLMs
Nov 15, 2024



The hallucination problem in multimodal large language models (MLLMs) remains a common issue. Although image tokens occupy a majority of the input sequence of MLLMs, there is limited research to explore the relationship between image tokens and hallucinations. In this paper, we analyze the distribution of attention scores for image tokens across each layer and head of the model, revealing an intriguing and common phenomenon: most hallucinations are closely linked to the pattern of attention sinks in the self-attention matrix of image tokens, where shallow layers exhibit dense attention sinks and deeper layers show sparse attention sinks. We further analyze the attention heads of different layers and find that heads with high-density attention sink in the image part play a positive role in alleviating hallucinations. In this paper, we propose a training-free method named \textcolor{red}{\textbf{E}}nhancing \textcolor{red}{\textbf{A}}ttention \textcolor{red}{\textbf{H}}eads (EAH), an approach designed to enhance the convergence of image tokens attention sinks in the shallow layers. EAH identifies the attention head that shows the vision sink in a shallow layer and extracts its attention matrix. This attention map is then broadcast to other heads in the layer, thereby strengthening the layer to pay more attention to the image itself. With extensive experiments, EAH shows significant hallucination-mitigating performance on different MLLMs and metrics, proving its effectiveness and generality.
From Redundancy to Relevance: Enhancing Explainability in Multimodal Large Language Models
Jun 04, 2024



Recently, multimodal large language models have exploded with an endless variety, most of the popular Large Vision Language Models (LVLMs) depend on sequential visual representation, where images are converted into hundreds or thousands of tokens before being input into the Large Language Model (LLM) along with language prompts. The black-box design hinders the interpretability of visual-language models, especially regarding more complex reasoning tasks. To explore the interaction process between image and text in complex reasoning tasks, we introduce the information flow method to visualize the interaction mechanism. By analyzing the dynamic flow of the information flow, we find that the information flow appears to converge in the shallow layer. Further investigation revealed a redundancy of the image token in the shallow layer. Consequently, a truncation strategy was introduced to aggregate image tokens within these shallow layers. This approach has been validated through experiments across multiple models, yielding consistent improvements.
Enlighten-Your-Voice: When Multimodal Meets Zero-shot Low-light Image Enhancement
Dec 15, 2023



Low-light image enhancement is a crucial visual task, and many unsupervised methods tend to overlook the degradation of visible information in low-light scenes, which adversely affects the fusion of complementary information and hinders the generation of satisfactory results. To address this, our study introduces ``Enlighten-Your-Voice'', a multimodal enhancement framework that innovatively enriches user interaction through voice and textual commands. This approach does not merely signify a technical leap but also represents a paradigm shift in user engagement. Our model is equipped with a Dual Collaborative Attention Module (DCAM) that meticulously caters to distinct content and color discrepancies, thereby facilitating nuanced enhancements. Complementarily, we introduce a Semantic Feature Fusion (SFM) plug-and-play module that synergizes semantic context with low-light enhancement operations, sharpening the algorithm's efficacy. Crucially, ``Enlighten-Your-Voice'' showcases remarkable generalization in unsupervised zero-shot scenarios. The source code can be accessed from https://github.com/zhangbaijin/Enlighten-Your-Voice
Enlighten Anything: When Segment Anything Model Meets Low-Light Image Enhancement
Jun 22, 2023



Image restoration is a low-level visual task, and most CNN methods are designed as black boxes, lacking transparency and intrinsic aesthetics. Many unsupervised approaches ignore the degradation of visible information in low-light scenes, which will seriously affect the aggregation of complementary information and also make the fusion algorithm unable to produce satisfactory fusion results under extreme conditions. In this paper, we propose Enlighten-anything, which is able to enhance and fuse the semantic intent of SAM segmentation with low-light images to obtain fused images with good visual perception. The generalization ability of unsupervised learning is greatly improved, and experiments on LOL dataset are conducted to show that our method improves 3db in PSNR over baseline and 8 in SSIM. Zero-shot learning of SAM introduces a powerful aid for unsupervised low-light enhancement. The source code of Enlighten Anything can be obtained from https://github.com/zhangbaijin/enlighten-anything
SAM-helps-Shadow:When Segment Anything Model meet shadow removal
Jun 01, 2023



The challenges surrounding the application of image shadow removal to real-world images and not just constrained datasets like ISTD/SRD have highlighted an urgent need for zero-shot learning in this field. In this study, we innovatively adapted the SAM (Segment anything model) for shadow removal by introducing SAM-helps-Shadow, effectively integrating shadow detection and removal into a single stage. Our approach utilized the model's detection results as a potent prior for facilitating shadow detection, followed by shadow removal using a second-order deep unfolding network. The source code of SAM-helps-Shadow can be obtained from https://github.com/zhangbaijin/SAM-helps-Shadow.
Distribution Learning Based on Evolutionary Algorithm Assisted Deep Neural Networks for Imbalanced Image Classification
Jul 26, 2022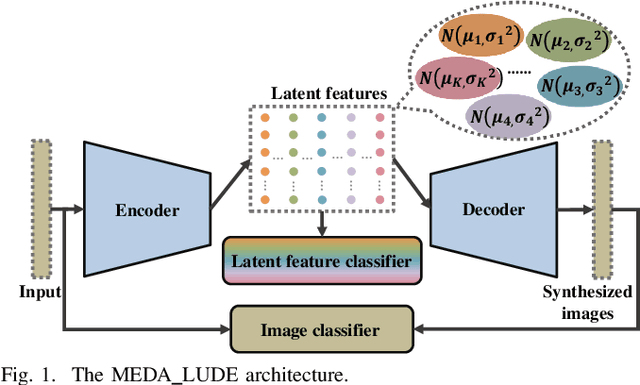
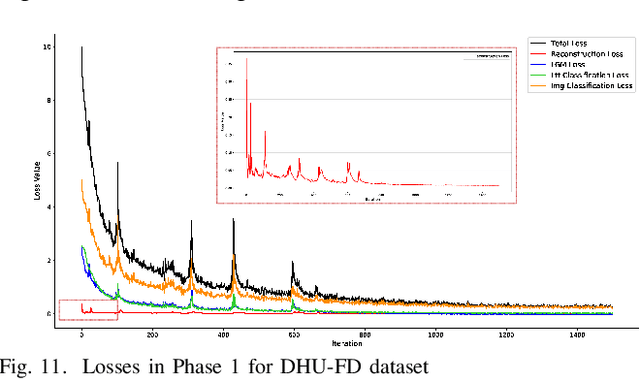
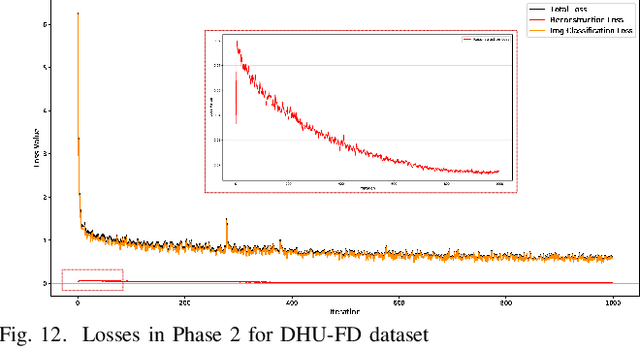
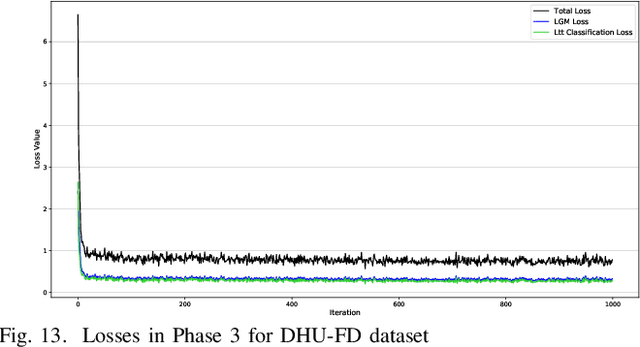
To address the trade-off problem of quality-diversity for the generated images in imbalanced classification tasks, we research on over-sampling based methods at the feature level instead of the data level and focus on searching the latent feature space for optimal distributions. On this basis, we propose an iMproved Estimation Distribution Algorithm based Latent featUre Distribution Evolution (MEDA_LUDE) algorithm, where a joint learning procedure is programmed to make the latent features both optimized and evolved by the deep neural networks and the evolutionary algorithm, respectively. We explore the effect of the Large-margin Gaussian Mixture (L-GM) loss function on distribution learning and design a specialized fitness function based on the similarities among samples to increase diversity. Extensive experiments on benchmark based imbalanced datasets validate the effectiveness of our proposed algorithm, which can generate images with both quality and diversity. Furthermore, the MEDA_LUDE algorithm is also applied to the industrial field and successfully alleviates the imbalanced issue in fabric defect classification.
A Glyph-driven Topology Enhancement Network for Scene Text Recognition
Mar 07, 2022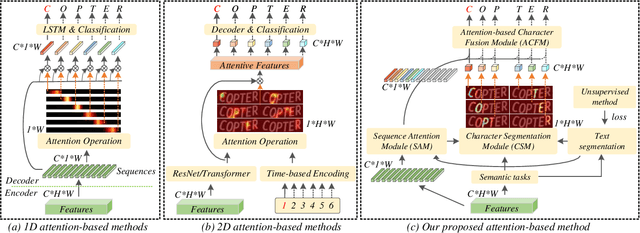
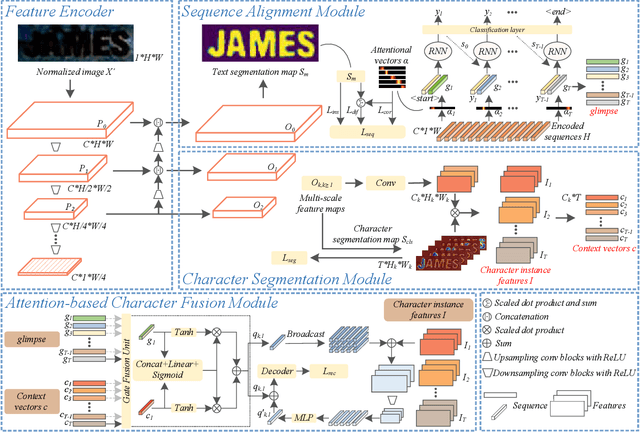
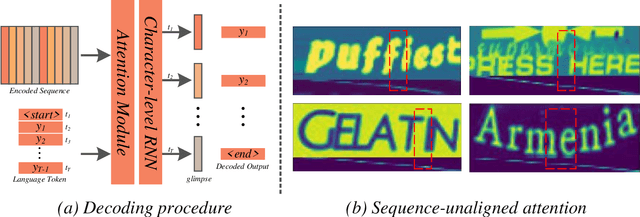

Attention-based methods by establishing one-dimensional (1D) and two-dimensional (2D) mechanisms with an encoder-decoder framework have dominated scene text recognition (STR) tasks due to their capabilities of building implicit language representations. However, 1D attention-based mechanisms suffer from alignment drift on latter characters. 2D attention-based mechanisms only roughly focus on the spatial regions of characters without excavating detailed topological structures, which reduces the visual performance. To mitigate the above issues, we propose a novel Glyph-driven Topology Enhancement Network (GTEN) to improve topological features representations in visual models for STR. Specifically, an unsupervised method is first employed to exploit 1D sequence-aligned attention weights. Second, we construct a supervised segmentation module to capture 2D ordered and pixel-wise topological information of glyphs without extra character-level annotations. Third, these resulting outputs fuse enhanced topological features to enrich semantic feature representations for STR. Experiments demonstrate that GTEN achieves competitive performance on IIIT5K-Words, Street View Text, ICDAR-series, SVT Perspective, and CUTE80 datasets.
Industrial Scene Text Detection with Refined Feature-attentive Network
Oct 25, 2021
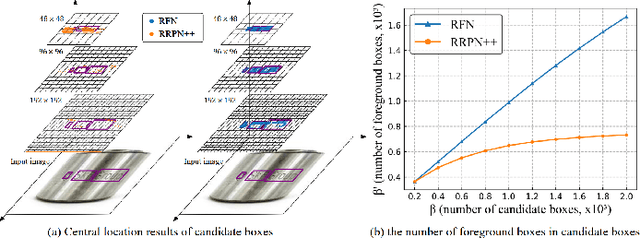


Detecting the marking characters of industrial metal parts remains challenging due to low visual contrast, uneven illumination, corroded character structures, and cluttered background of metal part images. Affected by these factors, bounding boxes generated by most existing methods locate low-contrast text areas inaccurately. In this paper, we propose a refined feature-attentive network (RFN) to solve the inaccurate localization problem. Specifically, we design a parallel feature integration mechanism to construct an adaptive feature representation from multi-resolution features, which enhances the perception of multi-scale texts at each scale-specific level to generate a high-quality attention map. Then, an attentive refinement network is developed by the attention map to rectify the location deviation of candidate boxes. In addition, a re-scoring mechanism is designed to select text boxes with the best rectified location. Moreover, we construct two industrial scene text datasets, including a total of 102156 images and 1948809 text instances with various character structures and metal parts. Extensive experiments on our dataset and four public datasets demonstrate that our proposed method achieves the state-of-the-art performance.
Complementary Patch for Weakly Supervised Semantic Segmentation
Aug 09, 2021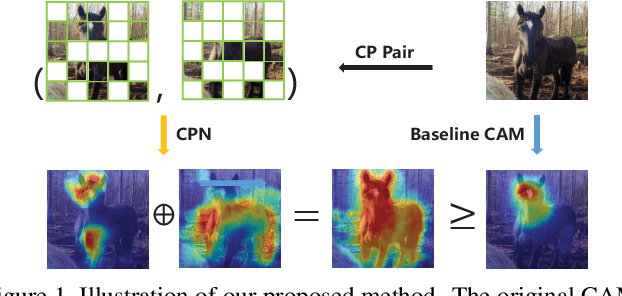
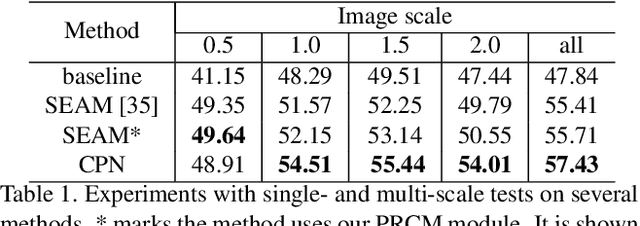
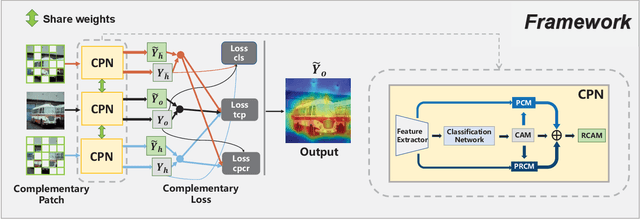

Weakly Supervised Semantic Segmentation (WSSS) based on image-level labels has been greatly advanced by exploiting the outputs of Class Activation Map (CAM) to generate the pseudo labels for semantic segmentation. However, CAM merely discovers seeds from a small number of regions, which may be insufficient to serve as pseudo masks for semantic segmentation. In this paper, we formulate the expansion of object regions in CAM as an increase in information. From the perspective of information theory, we propose a novel Complementary Patch (CP) Representation and prove that the information of the sum of the CAMs by a pair of input images with complementary hidden (patched) parts, namely CP Pair, is greater than or equal to the information of the baseline CAM. Therefore, a CAM with more information related to object seeds can be obtained by narrowing down the gap between the sum of CAMs generated by the CP Pair and the original CAM. We propose a CP Network (CPN) implemented by a triplet network and three regularization functions. To further improve the quality of the CAMs, we propose a Pixel-Region Correlation Module (PRCM) to augment the contextual information by using object-region relations between the feature maps and the CAMs. Experimental results on the PASCAL VOC 2012 datasets show that our proposed method achieves a new state-of-the-art in WSSS, validating the effectiveness of our CP Representation and CPN.