 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Harness: Online Adaptation for Self-Improving Foundation Agents
May 11, 2026Coding harnesses such as Claude Code and OpenHands wrap foundation models with tools, memory, and planning, but no equivalent exists for embodied agents' long-horizon partial-observability decision-making. We first report our Gemini Plays Pokemon (GPP) experiments. With iterative human-in-the-loop harness refinement, GPP became the first AI system to complete Pokemon Blue, Yellow Legacy on hard mode, and Crystal without a lost battle. In the hardest stages, the agent itself began iterating on its strategy through long-context memory, surfacing emergent self-improvement signals alongside human-in-the-loop refinement. Continual Harness removes the human fully from this loop: a reset-free self-improving harness for embodied agents that formalizes and automates what we observed. Starting from only a minimal environment interface, the agent alternates between acting and refining its own prompt, sub-agents, skills, and memory, drawing on any past trajectory data. Prompt-optimization methods require episode resets; Continual Harness adapts online within a single run. On Pokemon Red and Emerald across frontier models, Continual Harness starting from scratch substantially reduces button-press cost relative to the minimalist baseline and recovers a majority of the gap to a hand-engineered expert harness, with capability-dependent gains, despite starting from the same raw interface with no curated knowledge, no hand-crafted tools, and no domain scaffolding. We then close the loop with the model itself: an online process-reward co-learning loop, in which an open-source agent's rollouts through the refining harness are relabeled by a frontier teacher and used to update the model, drives sustained in-game milestone progress on Pokemon Red without resetting the environment between training iterations.
MUSIC: MUlti-Step Instruction Contrast for Multi-Turn Reward Models
Dec 31, 2025Evaluating the quality of multi-turn conversations is crucial for developing capable Large Language Models (LLMs), yet remains a significant challenge, often requiring costly human evaluation. Multi-turn reward models (RMs) offer a scalable alternative and can provide valuable signals for guiding LLM training. While recent work has advanced multi-turn \textit{training} techniques, effective automated \textit{evaluation} specifically for multi-turn interactions lags behind. We observe that standard preference datasets, typically contrasting responses based only on the final conversational turn, provide insufficient signal to capture the nuances of multi-turn interactions. Instead, we find that incorporating contrasts spanning \textit{multiple} turns is critical for building robust multi-turn RMs. Motivated by this finding, we propose \textbf{MU}lti-\textbf{S}tep \textbf{I}nstruction \textbf{C}ontrast (MUSIC), an unsupervised data augmentation strategy that synthesizes contrastive conversation pairs exhibiting differences across multiple turns. Leveraging MUSIC on the Skywork preference dataset, we train a multi-turn RM based on the Gemma-2-9B-Instruct model. Empirical results demonstrate that our MUSIC-augmented RM outperforms baseline methods, achieving higher alignment with judgments from advanced proprietary LLM judges on multi-turn conversations, crucially, without compromising performance on standard single-turn RM benchmarks.
Rubric-Based Benchmarking and Reinforcement Learning for Advancing LLM Instruction Following
Nov 13, 2025Recent progress in large language models (LLMs) has led to impressive performance on a range of tasks, yet advanced instruction following (IF)-especially for complex, multi-turn, and system-prompted instructions-remains a significant challenge. Rigorous evaluation and effective training for such capabilities are hindered by the lack of high-quality, human-annotated benchmarks and reliable, interpretable reward signals. In this work, we introduce AdvancedIF (we will release this benchmark soon), a comprehensive benchmark featuring over 1,600 prompts and expert-curated rubrics that assess LLMs ability to follow complex, multi-turn, and system-level instructions. We further propose RIFL (Rubric-based Instruction-Following Learning), a novel post-training pipeline that leverages rubric generation, a finetuned rubric verifier, and reward shaping to enable effective reinforcement learning for instruction following. Extensive experiments demonstrate that RIFL substantially improves the instruction-following abilities of LLMs, achieving a 6.7% absolute gain on AdvancedIF and strong results on public benchmarks. Our ablation studies confirm the effectiveness of each component in RIFL. This work establishes rubrics as a powerful tool for both training and evaluating advanced IF in LLMs, paving the way for more capable and reliable AI systems.
The Ever-Evolving Science Exam
Jul 22, 2025



As foundation models grow rapidly in capability and deployment, evaluating their scientific understanding becomes increasingly critical. Existing science benchmarks have made progress towards broad **Range**, wide **Reach**, and high **Rigor**, yet they often face two major challenges: **data leakage risks** that compromise benchmarking validity, and **evaluation inefficiency** due to large-scale testing. To address these issues, we introduce the **Ever-Evolving Science Exam (EESE)**, a dynamic benchmark designed to reliably assess scientific capabilities in foundation models. Our approach consists of two components: 1) a non-public **EESE-Pool** with over 100K expertly constructed science instances (question-answer pairs) across 5 disciplines and 500+ subfields, built through a multi-stage pipeline ensuring **Range**, **Reach**, and **Rigor**, 2) a periodically updated 500-instance subset **EESE**, sampled and validated to enable leakage-resilient, low-overhead evaluations. Experiments on 32 open- and closed-source models demonstrate that EESE effectively differentiates the strengths and weaknesses of models in scientific fields and cognitive dimensions. Overall, EESE provides a robust, scalable, and forward-compatible solution for science benchmark design, offering a realistic measure of how well foundation models handle science questions. The project page is at: https://github.com/aiben-ch/EESE.
MATH-Perturb: Benchmarking LLMs' Math Reasoning Abilities against Hard Perturbations
Feb 10, 2025



Large language models have demonstrated impressive performance on challenging mathematical reasoning tasks, which has triggered the discussion of whether the performance is achieved by true reasoning capability or memorization. To investigate this question, prior work has constructed mathematical benchmarks when questions undergo simple perturbations -- modifications that still preserve the underlying reasoning patterns of the solutions. However, no work has explored hard perturbations, which fundamentally change the nature of the problem so that the original solution steps do not apply. To bridge the gap, we construct MATH-P-Simple and MATH-P-Hard via simple perturbation and hard perturbation, respectively. Each consists of 279 perturbed math problems derived from level-5 (hardest) problems in the MATH dataset (Hendrycksmath et. al., 2021). We observe significant performance drops on MATH-P-Hard across various models, including o1-mini (-16.49%) and gemini-2.0-flash-thinking (-12.9%). We also raise concerns about a novel form of memorization where models blindly apply learned problem-solving skills without assessing their applicability to modified contexts. This issue is amplified when using original problems for in-context learning. We call for research efforts to address this challenge, which is critical for developing more robust and reliable reasoning models.
Towards Principled Superhuman AI for Multiplayer Symmetric Games
Jun 06, 2024

Multiplayer games, when the number of players exceeds two, present unique challenges that fundamentally distinguish them from the extensively studied two-player zero-sum games. These challenges arise from the non-uniqueness of equilibria and the risk of agents performing highly suboptimally when adopting equilibrium strategies. While a line of recent works developed learning systems successfully achieving human-level or even superhuman performance in popular multiplayer games such as Mahjong, Poker, and Diplomacy, two critical questions remain unaddressed: (1) What is the correct solution concept that AI agents should find? and (2) What is the general algorithmic framework that provably solves all games within this class? This paper takes the first step towards solving these unique challenges of multiplayer games by provably addressing both questions in multiplayer symmetric normal-form games. We also demonstrate that many meta-algorithms developed in prior practical systems for multiplayer games can fail to achieve even the basic goal of obtaining agent's equal share of the total reward.
FightLadder: A Benchmark for Competitive Multi-Agent Reinforcement Learning
Jun 04, 2024



Recent advances in reinforcement learning (RL) heavily rely on a variety of well-designed benchmarks, which provide environmental platforms and consistent criteria to evaluate existing and novel algorithms. Specifically, in multi-agent RL (MARL), a plethora of benchmarks based on cooperative games have spurred the development of algorithms that improve the scalability of cooperative multi-agent systems. However, for the competitive setting, a lightweight and open-sourced benchmark with challenging gaming dynamics and visual inputs has not yet been established. In this work, we present FightLadder, a real-time fighting game platform, to empower competitive MARL research. Along with the platform, we provide implementations of state-of-the-art MARL algorithms for competitive games, as well as a set of evaluation metrics to characterize the performance and exploitability of agents. We demonstrate the feasibility of this platform by training a general agent that consistently defeats 12 built-in characters in single-player mode, and expose the difficulty of training a non-exploitable agent without human knowledge and demonstrations in two-player mode. FightLadder provides meticulously designed environments to address critical challenges in competitive MARL research, aiming to catalyze a new era of discovery and advancement in the field. Videos and code at https://sites.google.com/view/fightladder/home.
A Survey on Transformers in Reinforcement Learning
Jan 08, 2023Transformer has been considered the dominating neural architecture in NLP and CV, mostly under a supervised setting. Recently, a similar surge of using Transformers has appeared in the domain of reinforcement learning (RL), but it is faced with unique design choices and challenges brought by the nature of RL. However, the evolution of Transformers in RL has not yet been well unraveled. Hence, in this paper, we seek to systematically review motivations and progress on using Transformers in RL, provide a taxonomy on existing works, discuss each sub-field, and summarize future prospects.
Flow to Control: Offline Reinforcement Learning with Lossless Primitive Discovery
Dec 02, 2022



Offline reinforcement learning (RL) enables the agent to effectively learn from logged data, which significantly extends the applicability of RL algorithms in real-world scenarios where exploration can be expensive or unsafe. Previous works have shown that extracting primitive skills from the recurring and temporally extended structures in the logged data yields better learning. However, these methods suffer greatly when the primitives have limited representation ability to recover the original policy space, especially in offline settings. In this paper, we give a quantitative characterization of the performance of offline hierarchical learning and highlight the importance of learning lossless primitives. To this end, we propose to use a \emph{flow}-based structure as the representation for low-level policies. This allows us to represent the behaviors in the dataset faithfully while keeping the expression ability to recover the whole policy space. We show that such lossless primitives can drastically improve the performance of hierarchical policies. The experimental results and extensive ablation studies on the standard D4RL benchmark show that our method has a good representation ability for policies and achieves superior performance in most tasks.
* 13pages
Improving Graph-Based Text Representations with Character and Word Level N-grams
Oct 12, 2022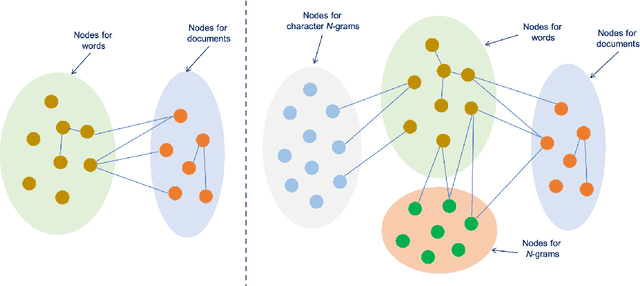
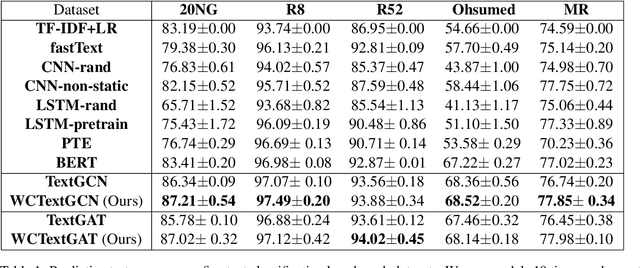


Graph-based text representation focuses on how text documents are represented as graphs for exploiting dependency information between tokens and documents within a corpus. Despite the increasing interest in graph representation learning, there is limited research in exploring new ways for graph-based text representation, which is important in downstream natural language processing tasks. In this paper, we first propose a new heterogeneous word-character text graph that combines word and character n-gram nodes together with document nodes, allowing us to better learn dependencies among these entities. Additionally, we propose two new graph-based neural models, WCTextGCN and WCTextGAT, for modeling our proposed text graph. Extensive experiments in text classification and automatic text summarization benchmarks demonstrate that our proposed models consistently outperform competitive baselines and state-of-the-art graph-based models.