 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Scientist via Synthetic Task Scaling
Mar 17, 2026With the advent of AI agents, automatic scientific discovery has become a tenable goal. Many recent works scaffold agentic systems that can perform machine learning research, but don't offer a principled way to train such agents -- and current LLMs often generate plausible-looking but ineffective ideas. To make progress on training agents that can learn from doing, we provide a novel synthetic environment generation pipeline targeting machine learning agents. Our pipeline automatically synthesizes machine learning challenges compatible with the SWE-agent framework, covering topic sampling, dataset proposal, and code generation. The resulting synthetic tasks are 1) grounded in real machine learning datasets, because the proposed datasets are verified against the Huggingface API and are 2) verified for higher quality with a self-debugging loop. To validate the effectiveness of our synthetic tasks, we tackle MLGym, a benchmark for machine learning tasks. From the synthetic tasks, we sample trajectories from a teacher model (GPT-5), then use the trajectories to train a student model (Qwen3-4B and Qwen3-8B). The student models trained with our synthetic tasks achieve improved performance on MLGym, raising the AUP metric by 9% for Qwen3-4B and 12% for Qwen3-8B.
Phi-4-reasoning Technical Report
Apr 30, 2025We introduce Phi-4-reasoning, a 14-billion parameter reasoning model that achieves strong performance on complex reasoning tasks. Trained via supervised fine-tuning of Phi-4 on carefully curated set of "teachable" prompts-selected for the right level of complexity and diversity-and reasoning demonstrations generated using o3-mini, Phi-4-reasoning generates detailed reasoning chains that effectively leverage inference-time compute. We further develop Phi-4-reasoning-plus, a variant enhanced through a short phase of outcome-based reinforcement learning that offers higher performance by generating longer reasoning traces. Across a wide range of reasoning tasks, both models outperform significantly larger open-weight models such as DeepSeek-R1-Distill-Llama-70B model and approach the performance levels of full DeepSeek-R1 model. Our comprehensive evaluations span benchmarks in math and scientific reasoning, coding, algorithmic problem solving, planning, and spatial understanding. Interestingly, we observe a non-trivial transfer of improvements to general-purpose benchmarks as well. In this report, we provide insights into our training data, our training methodologies, and our evaluations. We show that the benefit of careful data curation for supervised fine-tuning (SFT) extends to reasoning language models, and can be further amplified by reinforcement learning (RL). Finally, our evaluation points to opportunities for improving how we assess the performance and robustness of reasoning models.
Phi-4 Technical Report
Dec 12, 2024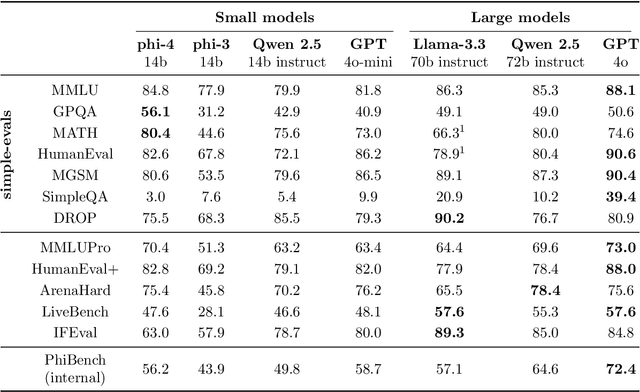
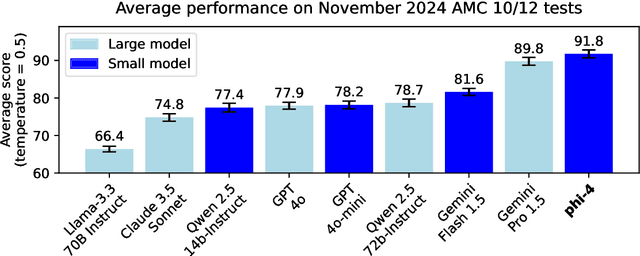

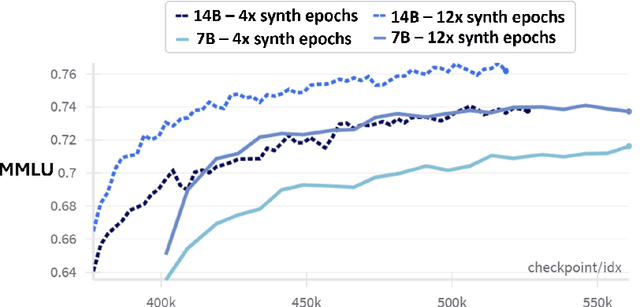
We present phi-4, a 14-billion parameter language model developed with a training recipe that is centrally focused on data quality. Unlike most language models, where pre-training is based primarily on organic data sources such as web content or code, phi-4 strategically incorporates synthetic data throughout the training process. While previous models in the Phi family largely distill the capabilities of a teacher model (specifically GPT-4), phi-4 substantially surpasses its teacher model on STEM-focused QA capabilities, giving evidence that our data-generation and post-training techniques go beyond distillation. Despite minimal changes to the phi-3 architecture, phi-4 achieves strong performance relative to its size -- especially on reasoning-focused benchmarks -- due to improved data, training curriculum, and innovations in the post-training scheme.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024



We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
PEEKABOO: Interactive Video Generation via Masked-Diffusion
Dec 12, 2023Recently there has been a lot of progress in text-to-video generation, with state-of-the-art models being capable of generating high quality, realistic videos. However, these models lack the capability for users to interactively control and generate videos, which can potentially unlock new areas of application. As a first step towards this goal, we tackle the problem of endowing diffusion-based video generation models with interactive spatio-temporal control over their output. To this end, we take inspiration from the recent advances in segmentation literature to propose a novel spatio-temporal masked attention module - Peekaboo. This module is a training-free, no-inference-overhead addition to off-the-shelf video generation models which enables spatio-temporal control. We also propose an evaluation benchmark for the interactive video generation task. Through extensive qualitative and quantitative evaluation, we establish that Peekaboo enables control video generation and even obtains a gain of upto 3.8x in mIoU over baseline models.
Unlocking Spatial Comprehension in Text-to-Image Diffusion Models
Nov 28, 2023



We propose CompFuser, an image generation pipeline that enhances spatial comprehension and attribute assignment in text-to-image generative models. Our pipeline enables the interpretation of instructions defining spatial relationships between objects in a scene, such as `An image of a gray cat on the left of an orange dog', and generate corresponding images. This is especially important in order to provide more control to the user. CompFuser overcomes the limitation of existing text-to-image diffusion models by decoding the generation of multiple objects into iterative steps: first generating a single object and then editing the image by placing additional objects in their designated positions. To create training data for spatial comprehension and attribute assignment we introduce a synthetic data generation process, that leverages a frozen large language model and a frozen layout-based diffusion model for object placement. We compare our approach to strong baselines and show that our model outperforms state-of-the-art image generation models in spatial comprehension and attribute assignment, despite being 3x to 5x smaller in parameters.
DAMEX: Dataset-aware Mixture-of-Experts for visual understanding of mixture-of-datasets
Nov 08, 2023



Construction of a universal detector poses a crucial question: How can we most effectively train a model on a large mixture of datasets? The answer lies in learning dataset-specific features and ensembling their knowledge but do all this in a single model. Previous methods achieve this by having separate detection heads on a common backbone but that results in a significant increase in parameters. In this work, we present Mixture-of-Experts as a solution, highlighting that MoEs are much more than a scalability tool. We propose Dataset-Aware Mixture-of-Experts, DAMEX where we train the experts to become an `expert' of a dataset by learning to route each dataset tokens to its mapped expert. Experiments on Universal Object-Detection Benchmark show that we outperform the existing state-of-the-art by average +10.2 AP score and improve over our non-MoE baseline by average +2.0 AP score. We also observe consistent gains while mixing datasets with (1) limited availability, (2) disparate domains and (3) divergent label sets. Further, we qualitatively show that DAMEX is robust against expert representation collapse.
Efficiently Robustify Pre-trained Models
Sep 14, 2023A recent trend in deep learning algorithms has been towards training large scale models, having high parameter count and trained on big dataset. However, robustness of such large scale models towards real-world settings is still a less-explored topic. In this work, we first benchmark the performance of these models under different perturbations and datasets thereby representing real-world shifts, and highlight their degrading performance under these shifts. We then discuss on how complete model fine-tuning based existing robustification schemes might not be a scalable option given very large scale networks and can also lead them to forget some of the desired characterstics. Finally, we propose a simple and cost-effective method to solve this problem, inspired by knowledge transfer literature. It involves robustifying smaller models, at a lower computation cost, and then use them as teachers to tune a fraction of these large scale networks, reducing the overall computational overhead. We evaluate our proposed method under various vision perturbations including ImageNet-C,R,S,A datasets and also for transfer learning, zero-shot evaluation setups on different datasets. Benchmark results show that our method is able to induce robustness to these large scale models efficiently, requiring significantly lower time and also preserves the transfer learning, zero-shot properties of the original model which none of the existing methods are able to achieve.
Generalized Decoding for Pixel, Image, and Language
Dec 21, 2022



We present X-Decoder, a generalized decoding model that can predict pixel-level segmentation and language tokens seamlessly. X-Decodert takes as input two types of queries: (i) generic non-semantic queries and (ii) semantic queries induced from text inputs, to decode different pixel-level and token-level outputs in the same semantic space. With such a novel design, X-Decoder is the first work that provides a unified way to support all types of image segmentation and a variety of vision-language (VL) tasks. Further, our design enables seamless interactions across tasks at different granularities and brings mutual benefits by learning a common and rich pixel-level visual-semantic understanding space, without any pseudo-labeling. After pretraining on a mixed set of a limited amount of segmentation data and millions of image-text pairs, X-Decoder exhibits strong transferability to a wide range of downstream tasks in both zero-shot and finetuning settings. Notably, it achieves (1) state-of-the-art results on open-vocabulary segmentation and referring segmentation on eight datasets; (2) better or competitive finetuned performance to other generalist and specialist models on segmentation and VL tasks; and (3) flexibility for efficient finetuning and novel task composition (e.g., referring captioning and image editing). Code, demo, video, and visualization are available at https://x-decoder-vl.github.io.
Neural-Sim: Learning to Generate Training Data with NeRF
Jul 22, 2022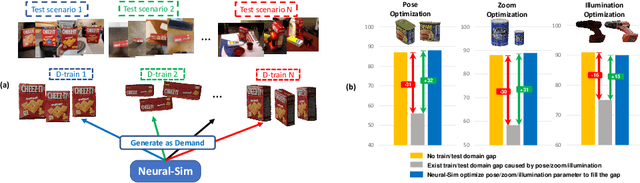
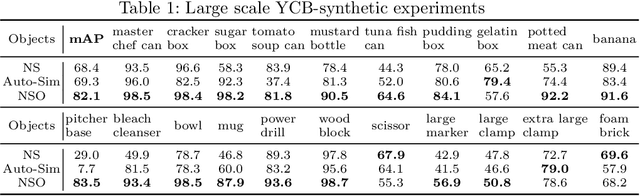

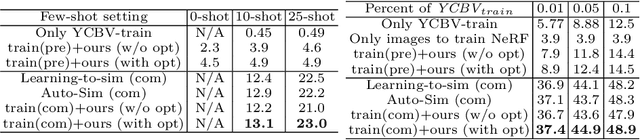
Training computer vision models usually requires collecting and labeling vast amounts of imagery under a diverse set of scene configurations and properties. This process is incredibly time-consuming, and it is challenging to ensure that the captured data distribution maps well to the target domain of an application scenario. Recently, synthetic data has emerged as a way to address both of these issues. However, existing approaches either require human experts to manually tune each scene property or use automatic methods that provide little to no control; this requires rendering large amounts of random data variations, which is slow and is often suboptimal for the target domain. We present the first fully differentiable synthetic data pipeline that uses Neural Radiance Fields (NeRFs) in a closed-loop with a target application's loss function. Our approach generates data on-demand, with no human labor, to maximize accuracy for a target task. We illustrate the effectiveness of our method on synthetic and real-world object detection tasks. We also introduce a new "YCB-in-the-Wild" dataset and benchmark that provides a test scenario for object detection with varied poses in real-world environments.