 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Than the Final Answer: Improving Visual Extraction and Logical Consistency in Vision-Language Models
Dec 13, 2025Reinforcement learning from verifiable rewards (RLVR) has recently been extended from text-only LLMs to vision-language models (VLMs) to elicit long-chain multimodal reasoning. However, RLVR-trained VLMs still exhibit two persistent failure modes: inaccurate visual extraction (missing or hallucinating details) and logically inconsistent chains-of-thought, largely because verifiable signals supervise only the final answer. We propose PeRL-VL (Perception and Reasoning Learning for Vision-Language Models), a decoupled framework that separately improves visual perception and textual reasoning on top of RLVR. For perception, PeRL-VL introduces a VLM-based description reward that scores the model's self-generated image descriptions for faithfulness and sufficiency. For reasoning, PeRL-VL adds a text-only Reasoning SFT stage on logic-rich chain-of-thought data, enhancing coherence and logical consistency independently of vision. Across diverse multimodal benchmarks, PeRL-VL improves average Pass@1 accuracy from 63.3% (base Qwen2.5-VL-7B) to 68.8%, outperforming standard RLVR, text-only reasoning SFT, and naive multimodal distillation from GPT-4o.
Rethinking the Text-Vision Reasoning Imbalance in MLLMs through the Lens of Training Recipes
Oct 26, 2025Multimodal large language models (MLLMs) have demonstrated strong capabilities on vision-and-language tasks. However, recent findings reveal an imbalance in their reasoning capabilities across visual and textual modalities. Specifically, current MLLMs often over-rely on textual cues while under-attending to visual content, resulting in suboptimal performance on tasks that require genuine visual reasoning. We refer to this phenomenon as the \textit{modality gap}, defined as the performance disparity between text-centric and vision-centric inputs. In this paper, we analyze the modality gap through the lens of training recipes. We first show that existing training recipes tend to amplify this gap. Then, we systematically explore strategies to bridge it from two complementary perspectives: data and loss design. Our findings provide insights into developing training recipes that mitigate the modality gap and promote more balanced multimodal reasoning. Our code is publicly available at https://github.com/UCSB-NLP-Chang/Bridging-Modality-Gap.
Interactive Visualization Recommendation with Hier-SUCB
Feb 06, 2025Visualization recommendation aims to enable rapid visual analysis of massive datasets. In real-world scenarios, it is essential to quickly gather and comprehend user preferences to cover users from diverse backgrounds, including varying skill levels and analytical tasks. Previous approaches to personalized visualization recommendations are non-interactive and rely on initial user data for new users. As a result, these models cannot effectively explore options or adapt to real-time feedback. To address this limitation, we propose an interactive personalized visualization recommendation (PVisRec) system that learns on user feedback from previous interactions. For more interactive and accurate recommendations, we propose Hier-SUCB, a contextual combinatorial semi-bandit in the PVisRec setting. Theoretically, we show an improved overall regret bound with the same rank of time but an improved rank of action space. We further demonstrate the effectiveness of Hier-SUCB through extensive experiments where it is comparable to offline methods and outperforms other bandit algorithms in the setting of visualization recommendation.
GUI-Bee: Align GUI Action Grounding to Novel Environments via Autonomous Exploration
Jan 27, 2025
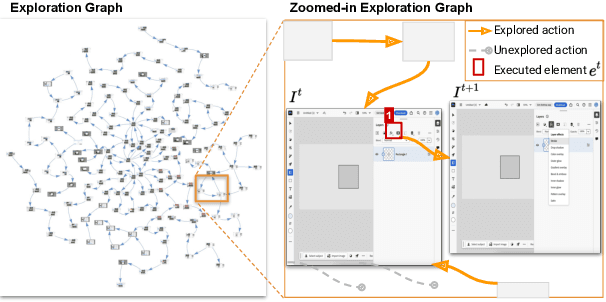
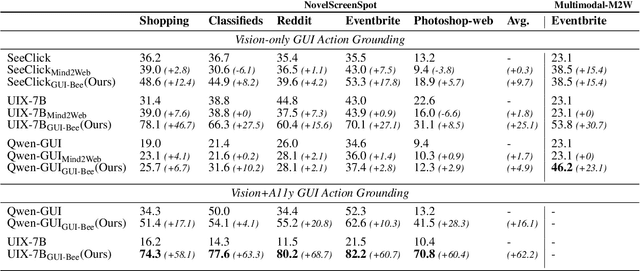
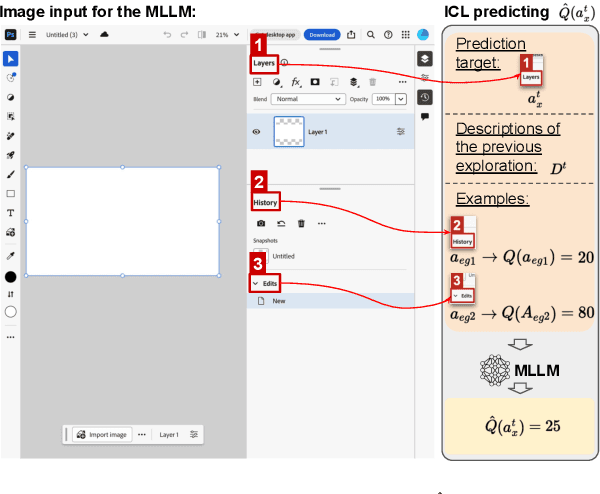
Graphical User Interface (GUI) action grounding is a critical step in GUI automation that maps language instructions to actionable elements on GUI screens. Most recent works of GUI action grounding leverage large GUI datasets to fine-tune MLLMs. However, the fine-tuning data always covers limited GUI environments, and we find the performance of the resulting model deteriorates in novel environments. We argue that the GUI grounding models should be further aligned to the novel environments to reveal their full potential, when the inference is known to involve novel environments, i.e., environments not used during the previous fine-tuning. To realize this, we first propose GUI-Bee, an MLLM-based autonomous agent, to collect high-quality, environment-specific data through exploration and then continuously fine-tune GUI grounding models with the collected data. Our agent leverages a novel Q-value-Incentive In-Context Reinforcement Learning (Q-ICRL) method to optimize exploration efficiency and data quality. Additionally, we introduce NovelScreenSpot, a benchmark for testing how well the data can help align GUI action grounding models to novel environments and demonstrate the effectiveness of data collected by GUI-Bee in the experiments. Furthermore, we conduct an ablation study to validate the Q-ICRL method in enhancing the efficiency of GUI-Bee. Project page: https://gui-bee.github.io
MAGNET: Augmenting Generative Decoders with Representation Learning and Infilling Capabilities
Jan 15, 2025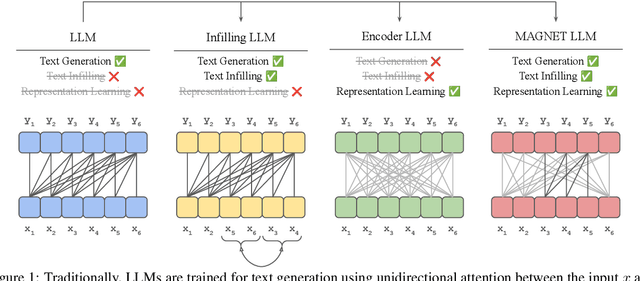
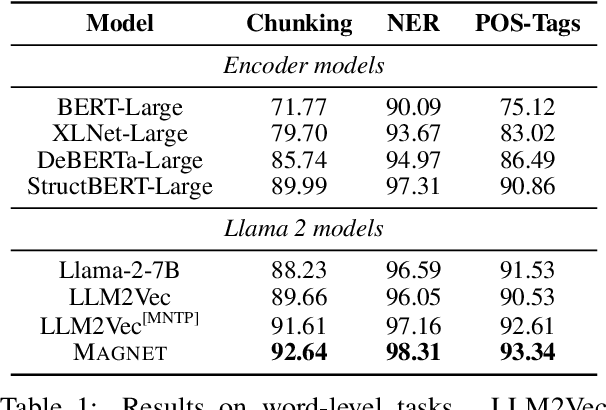
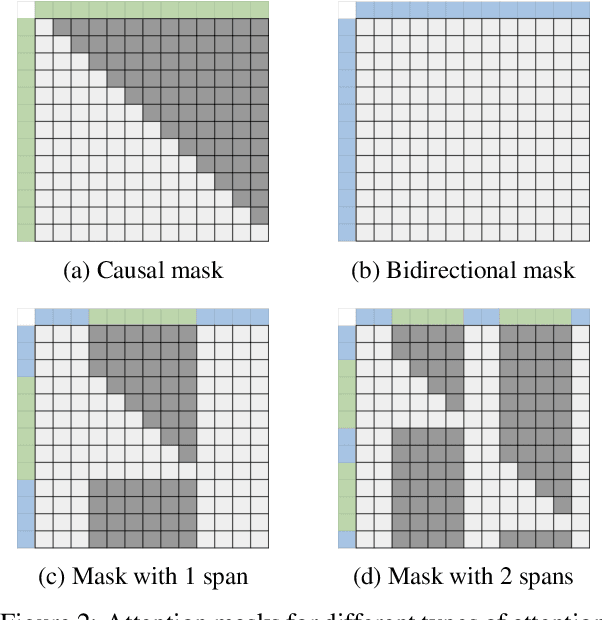
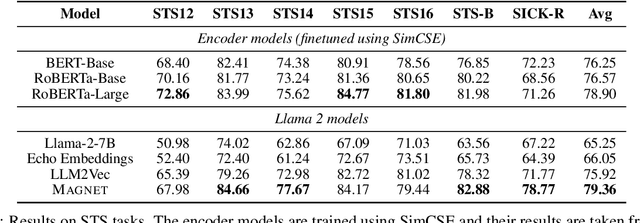
While originally designed for unidirectional generative modeling, decoder-only large language models (LLMs) are increasingly being adapted for bidirectional modeling. However, unidirectional and bidirectional models are typically trained separately with distinct objectives (generation and representation learning, respectively). This separation overlooks the opportunity for developing a more versatile language model and for these objectives to complement each other. In this work, we introduce MAGNET, an adaptation of decoder-only LLMs that enhances their ability to generate robust representations and infill missing text spans, while preserving their knowledge and text generation capabilities. MAGNET employs three self-supervised training objectives and introduces an attention mechanism that combines bidirectional and causal attention, enabling unified training across all objectives. Our results demonstrate that LLMs adapted with MAGNET (1) surpass strong text encoders on token-level and sentence-level representation learning tasks, (2) generate contextually appropriate text infills by leveraging future context, (3) retain the ability for open-ended text generation without exhibiting repetition problem, and (4) preserve the knowledge gained by the LLM during pretraining.
DynaSaur: Large Language Agents Beyond Predefined Actions
Nov 04, 2024



Existing LLM agent systems typically select actions from a fixed and predefined set at every step. While this approach is effective in closed, narrowly-scoped environments, we argue that it presents two major challenges when deploying LLM agents in real-world scenarios: (1) selecting from a fixed set of actions significantly restricts the planning and acting capabilities of LLM agents, and (2) this approach requires substantial human effort to enumerate and implement all possible actions, which becomes impractical in complex environments with a vast number of potential actions. In this work, we propose an LLM agent framework that enables the dynamic creation and composition of actions in an online manner. In this framework, the agent interacts with the environment by generating and executing programs written in a general-purpose programming language at each step. Furthermore, generated actions are accumulated over time for future reuse. Our extensive experiments on the GAIA benchmark demonstrate that this framework offers significantly greater flexibility and outperforms previous methods. Notably, it allows an LLM agent to recover in scenarios where no relevant action exists in the predefined set or when existing actions fail due to unforeseen edge cases. At the time of writing, we hold the top position on the GAIA public leaderboard. Our code can be found in \href{https://github.com/adobe-research/dynasaur}{https://github.com/adobe-research/dynasaur}.
VSP: Assessing the dual challenges of perception and reasoning in spatial planning tasks for VLMs
Jul 02, 2024



Vision language models (VLMs) are an exciting emerging class of language models (LMs) that have merged classic LM capabilities with those of image processing systems. However, the ways that these capabilities combine are not always intuitive and warrant direct investigation. One understudied capability in VLMs is visual spatial planning -- the ability to comprehend the spatial arrangements of objects and devise action plans to achieve desired outcomes in visual scenes. In our study, we introduce VSP, a benchmark that 1) evaluates the spatial planning capability in these models in general, and 2) breaks down the visual planning task into finer-grained sub-tasks, including perception and reasoning, and measure the LMs capabilities in these sub-tasks. Our evaluation shows that both open-source and private VLMs fail to generate effective plans for even simple spatial planning tasks. Evaluations on the fine-grained analytical tasks further reveal fundamental deficiencies in the models' visual perception and bottlenecks in reasoning abilities, explaining their worse performance in the general spatial planning tasks. Our work illuminates future directions for improving VLMs' abilities in spatial planning. Our benchmark is publicly available at https://github.com/UCSB-NLP-Chang/Visual-Spatial-Planning.
Reminding Multimodal Large Language Models of Object-aware Knowledge with Retrieved Tags
Jun 16, 2024Despite recent advances in the general visual instruction-following ability of Multimodal Large Language Models (MLLMs), they still struggle with critical problems when required to provide a precise and detailed response to a visual instruction: (1) failure to identify novel objects or entities, (2) mention of non-existent objects, and (3) neglect of object's attributed details. Intuitive solutions include improving the size and quality of data or using larger foundation models. They show effectiveness in mitigating these issues, but at an expensive cost of collecting a vast amount of new data and introducing a significantly larger model. Standing at the intersection of these approaches, we examine the three object-oriented problems from the perspective of the image-to-text mapping process by the multimodal connector. In this paper, we first identify the limitations of multimodal connectors stemming from insufficient training data. Driven by this, we propose to enhance the mapping with retrieval-augmented tag tokens, which contain rich object-aware information such as object names and attributes. With our Tag-grounded visual instruction tuning with retrieval Augmentation (TUNA), we outperform baselines that share the same language model and training data on 12 benchmarks. Furthermore, we show the zero-shot capability of TUNA when provided with specific datastores.
SOHES: Self-supervised Open-world Hierarchical Entity Segmentation
Apr 18, 2024Open-world entity segmentation, as an emerging computer vision task, aims at segmenting entities in images without being restricted by pre-defined classes, offering impressive generalization capabilities on unseen images and concepts. Despite its promise, existing entity segmentation methods like Segment Anything Model (SAM) rely heavily on costly expert annotators. This work presents Self-supervised Open-world Hierarchical Entity Segmentation (SOHES), a novel approach that eliminates the need for human annotations. SOHES operates in three phases: self-exploration, self-instruction, and self-correction. Given a pre-trained self-supervised representation, we produce abundant high-quality pseudo-labels through visual feature clustering. Then, we train a segmentation model on the pseudo-labels, and rectify the noises in pseudo-labels via a teacher-student mutual-learning procedure. Beyond segmenting entities, SOHES also captures their constituent parts, providing a hierarchical understanding of visual entities. Using raw images as the sole training data, our method achieves unprecedented performance in self-supervised open-world segmentation, marking a significant milestone towards high-quality open-world entity segmentation in the absence of human-annotated masks. Project page: https://SOHES.github.io.
Fine-tuning CLIP Text Encoders with Two-step Paraphrasing
Feb 23, 2024



Contrastive language-image pre-training (CLIP) models have demonstrated considerable success across various vision-language tasks, such as text-to-image retrieval, where the model is required to effectively process natural language input to produce an accurate visual output. However, current models still face limitations in dealing with linguistic variations in input queries, such as paraphrases, making it challenging to handle a broad range of user queries in real-world applications. In this study, we introduce a straightforward fine-tuning approach to enhance the representations of CLIP models for paraphrases. Our approach involves a two-step paraphrase generation process, where we automatically create two categories of paraphrases from web-scale image captions by leveraging large language models. Subsequently, we fine-tune the CLIP text encoder using these generated paraphrases while freezing the image encoder. Our resulting model, which we call ParaCLIP, exhibits significant improvements over baseline CLIP models across various tasks, including paraphrased retrieval (with rank similarity scores improved by up to 2.0% and 5.6%), Visual Genome Relation and Attribution, as well as seven semantic textual similarity tasks.