 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvantageFlow: Advantage-Weighted Least Squares for RL in Flow Models
May 25, 2026We introduce AdvantageFlow, a forward-process reinforcement learning algorithm for rectified flow models. Unlike Flow-GRPO, which optimizes the reverse process, we optimize an advantage-weighted forward-process prediction loss. This optimization problem is unstable when advantages are negative and the loss becomes non-convex. We stabilize it by rollout policy regularization, which reduces variance and arises from fitting a local reward-improving target distribution. We evaluate AdvantageFlow on image generation tasks with Stable Diffusion 3.5 Medium. It outperforms both Flow-GRPO and a state-of-the-art forward-process RL baseline based on negative-aware fine-tuning.
When Attention Closes: How LLMs Lose the Thread in Multi-Turn Interaction
May 13, 2026Large language models can follow complex instructions in a single turn, yet over long multi-turn interactions they often lose the thread of instructions, persona, and rules. This degradation has been measured behaviorally but not mechanistically explained. We propose a channel-transition account: goal-defining tokens become less accessible through attention, while goal-related information may persist in residual representations. We introduce the Goal Accessibility Ratio (GAR), measuring attention from generated tokens to task-defining goal tokens, and combine it with sliding-window ablations and residual-stream probes. When attention to instructions closes, what survives reveals architecture. Across architectures, the transition yields qualitatively distinct failure modes: some models preserve goal-conditioned behavior at vanishing attention, others fail despite decodable residual goal information, and the layer at which this encoding emerges varies from 2 to 27. A within-model causal ablation that force-closes the attention channel in Mistral collapses recall from near-perfect to 11% on a 20-fact retention task and raises persona-constraint violations above an adversarial-pressure baseline without user pressure, with both effects emerging at the predictable crossover turn. Linear probes recover per-episode recall outcomes from residual representations with AUC up to 0.99 across all four primary architectures, while input embeddings remain at chance. Across architectures and model scales, the gap between attention loss and residual decodability predicts whether goal-conditioned behavior survives channel closure. We contribute GAR as a diagnostic, the channel-transition framework as a controlled mechanistic account, and a parametric prediction of failure timing under windowed attention closure.
ViT-AdaLA: Adapting Vision Transformers with Linear Attention
Mar 17, 2026Vision Transformers (ViTs) based vision foundation models (VFMs) have achieved remarkable performance across diverse vision tasks, but suffer from quadratic complexity that limits scalability to long sequences. Existing linear attention approaches for ViTs are typically trained from scratch, requiring substantial computational resources, while linearization-based methods developed for large language model decoders do not transfer well to ViTs. To address these challenges, we propose ViT-AdaLA, a novel framework for effectively adapting and transferring prior knowledge from VFMs to linear attention ViTs. ViT-AdaLA consists of three stages: attention alignment, feature alignment, and supervised fine-tuning. In the attention alignment stage, we align vanilla linear attention with the original softmax-based attention in each block to approximate the behavior of softmax attention. However, residual approximation errors inevitably accumulate across layers. We mitigate this by fine-tuning the linearized ViT to align its final-layer features with a frozen softmax VFM teacher. Finally, the adapted prior knowledge is transferred to downstream tasks through supervised fine-tuning. Extensive experiments on classification and segmentation tasks demonstrate the effectiveness and generality of ViT-AdaLA over various state-of-the-art linear attention counterpart.
InfinityStory: Unlimited Video Generation with World Consistency and Character-Aware Shot Transitions
Mar 04, 2026Generating long-form storytelling videos with consistent visual narratives remains a significant challenge in video synthesis. We present a novel framework, dataset, and a model that address three critical limitations: background consistency across shots, seamless multi-subject shot-to-shot transitions, and scalability to hour-long narratives. Our approach introduces a background-consistent generation pipeline that maintains visual coherence across scenes while preserving character identity and spatial relationships. We further propose a transition-aware video synthesis module that generates smooth shot transitions for complex scenarios involving multiple subjects entering or exiting frames, going beyond the single-subject limitations of prior work. To support this, we contribute with a synthetic dataset of 10,000 multi-subject transition sequences covering underrepresented dynamic scene compositions. On VBench, InfinityStory achieves the highest Background Consistency (88.94), highest Subject Consistency (82.11), and the best overall average rank (2.80), showing improved stability, smoother transitions, and better temporal coherence.
Drift No More? Context Equilibria in Multi-Turn LLM Interactions
Oct 09, 2025Large Language Models (LLMs) excel at single-turn tasks such as instruction following and summarization, yet real-world deployments require sustained multi-turn interactions where user goals and conversational context persist and evolve. A recurring challenge in this setting is context drift: the gradual divergence of a model's outputs from goal-consistent behavior across turns. Unlike single-turn errors, drift unfolds temporally and is poorly captured by static evaluation metrics. In this work, we present a study of context drift in multi-turn interactions and propose a simple dynamical framework to interpret its behavior. We formalize drift as the turn-wise KL divergence between the token-level predictive distributions of the test model and a goal-consistent reference model, and propose a recurrence model that interprets its evolution as a bounded stochastic process with restoring forces and controllable interventions. We instantiate this framework in both synthetic long-horizon rewriting tasks and realistic user-agent simulations such as in $\tau$-Bench, measuring drift for several open-weight LLMs that are used as user simulators. Our experiments consistently reveal stable, noise-limited equilibria rather than runaway degradation, and demonstrate that simple reminder interventions reliably reduce divergence in line with theoretical predictions. Together, these results suggest that multi-turn drift can be understood as a controllable equilibrium phenomenon rather than as inevitable decay, providing a foundation for studying and mitigating context drift in extended interactions.
A Survey on Long-Video Storytelling Generation: Architectures, Consistency, and Cinematic Quality
Jul 09, 2025

Despite the significant progress that has been made in video generative models, existing state-of-the-art methods can only produce videos lasting 5-16 seconds, often labeled "long-form videos". Furthermore, videos exceeding 16 seconds struggle to maintain consistent character appearances and scene layouts throughout the narrative. In particular, multi-subject long videos still fail to preserve character consistency and motion coherence. While some methods can generate videos up to 150 seconds long, they often suffer from frame redundancy and low temporal diversity. Recent work has attempted to produce long-form videos featuring multiple characters, narrative coherence, and high-fidelity detail. We comprehensively studied 32 papers on video generation to identify key architectural components and training strategies that consistently yield these qualities. We also construct a comprehensive novel taxonomy of existing methods and present comparative tables that categorize papers by their architectural designs and performance characteristics.
Learning to Clarify by Reinforcement Learning Through Reward-Weighted Fine-Tuning
Jun 08, 2025



Question answering (QA) agents automatically answer questions posed in natural language. In this work, we learn to ask clarifying questions in QA agents. The key idea in our method is to simulate conversations that contain clarifying questions and learn from them using reinforcement learning (RL). To make RL practical, we propose and analyze offline RL objectives that can be viewed as reward-weighted supervised fine-tuning (SFT) and easily optimized in large language models. Our work stands in a stark contrast to recently proposed methods, based on SFT and direct preference optimization, which have additional hyper-parameters and do not directly optimize rewards. We compare to these methods empirically and report gains in both optimized rewards and language quality.
Understanding Generative AI Capabilities in Everyday Image Editing Tasks
May 22, 2025



Generative AI (GenAI) holds significant promise for automating everyday image editing tasks, especially following the recent release of GPT-4o on March 25, 2025. However, what subjects do people most often want edited? What kinds of editing actions do they want to perform (e.g., removing or stylizing the subject)? Do people prefer precise edits with predictable outcomes or highly creative ones? By understanding the characteristics of real-world requests and the corresponding edits made by freelance photo-editing wizards, can we draw lessons for improving AI-based editors and determine which types of requests can currently be handled successfully by AI editors? In this paper, we present a unique study addressing these questions by analyzing 83k requests from the past 12 years (2013-2025) on the Reddit community, which collected 305k PSR-wizard edits. According to human ratings, approximately only 33% of requests can be fulfilled by the best AI editors (including GPT-4o, Gemini-2.0-Flash, SeedEdit). Interestingly, AI editors perform worse on low-creativity requests that require precise editing than on more open-ended tasks. They often struggle to preserve the identity of people and animals, and frequently make non-requested touch-ups. On the other side of the table, VLM judges (e.g., o1) perform differently from human judges and may prefer AI edits more than human edits. Code and qualitative examples are available at: https://psrdataset.github.io
LUSIFER: Language Universal Space Integration for Enhanced Multilingual Embeddings with Large Language Models
Jan 01, 2025



Recent advancements in large language models (LLMs) based embedding models have established new state-of-the-art benchmarks for text embedding tasks, particularly in dense vector-based retrieval. However, these models predominantly focus on English, leaving multilingual embedding capabilities largely unexplored. To address this limitation, we present LUSIFER, a novel zero-shot approach that adapts LLM-based embedding models for multilingual tasks without requiring multilingual supervision. LUSIFER's architecture combines a multilingual encoder, serving as a language-universal learner, with an LLM-based embedding model optimized for embedding-specific tasks. These components are seamlessly integrated through a minimal set of trainable parameters that act as a connector, effectively transferring the multilingual encoder's language understanding capabilities to the specialized embedding model. Additionally, to comprehensively evaluate multilingual embedding performance, we introduce a new benchmark encompassing 5 primary embedding tasks, 123 diverse datasets, and coverage across 14 languages. Extensive experimental results demonstrate that LUSIFER significantly enhances the multilingual performance across various embedding tasks, particularly for medium and low-resource languages, without requiring explicit multilingual training data.
GUI Agents: A Survey
Dec 18, 2024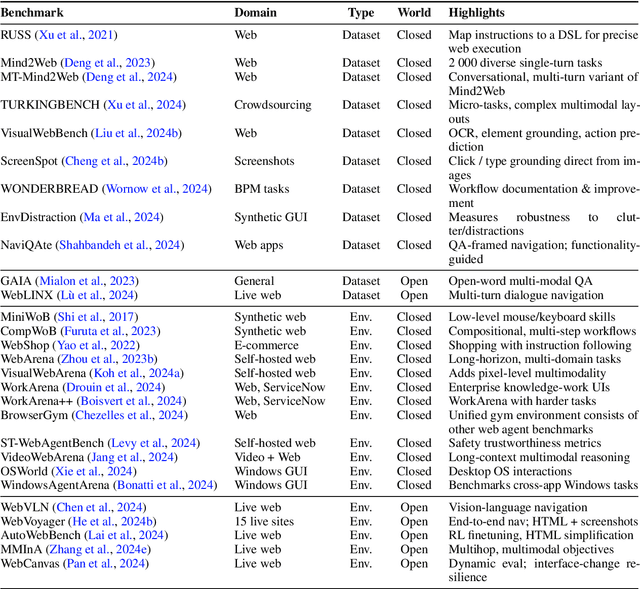
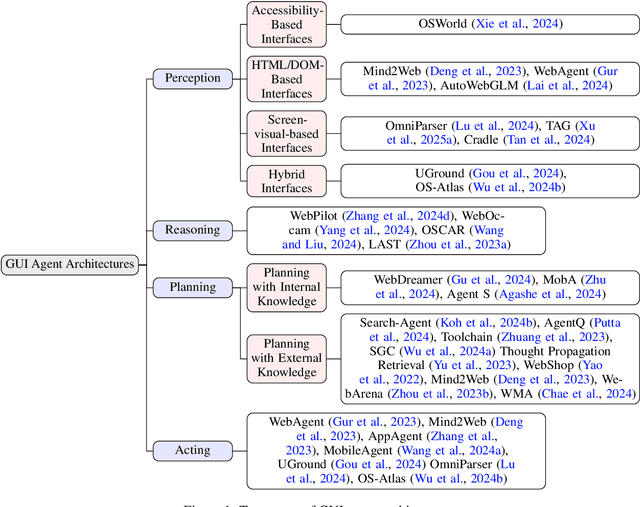

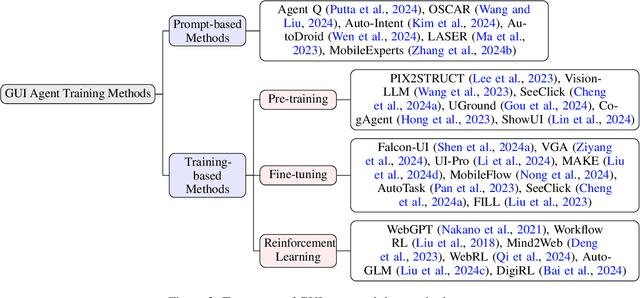
Graphical User Interface (GUI) agents, powered by Large Foundation Models, have emerged as a transformative approach to automating human-computer interaction. These agents autonomously interact with digital systems or software applications via GUIs, emulating human actions such as clicking, typing, and navigating visual elements across diverse platforms. Motivated by the growing interest and fundamental importance of GUI agents, we provide a comprehensive survey that categorizes their benchmarks, evaluation metrics, architectures, and training methods. We propose a unified framework that delineates their perception, reasoning, planning, and acting capabilities. Furthermore, we identify important open challenges and discuss key future directions. Finally, this work serves as a basis for practitioners and researchers to gain an intuitive understanding of current progress, techniques, benchmarks, and critical open problems that remain to be addressed.