 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinicalGPT-R1: Pushing reasoning capability of generalist disease diagnosis with large language model
Apr 15, 2025Recent advances in reasoning with large language models (LLMs)has shown remarkable reasoning capabilities in domains such as mathematics and coding, yet their application to clinical diagnosis remains underexplored. Here, we introduce ClinicalGPT-R1, a reasoning enhanced generalist large language model for disease diagnosis. Trained on a dataset of 20,000 real-world clinical records, ClinicalGPT-R1 leverages diverse training strategies to enhance diagnostic reasoning. To benchmark performance, we curated MedBench-Hard, a challenging dataset spanning seven major medical specialties and representative diseases. Experimental results demonstrate that ClinicalGPT-R1 outperforms GPT-4o in Chinese diagnostic tasks and achieves comparable performance to GPT-4 in English settings. This comparative study effectively validates the superior performance of ClinicalGPT-R1 in disease diagnosis tasks. Resources are available at https://github.com/medfound/medfound.
Leveraging Large Vision-Language Model as User Intent-aware Encoder for Composed Image Retrieval
Dec 15, 2024Composed Image Retrieval (CIR) aims to retrieve target images from candidate set using a hybrid-modality query consisting of a reference image and a relative caption that describes the user intent. Recent studies attempt to utilize Vision-Language Pre-training Models (VLPMs) with various fusion strategies for addressing the task.However, these methods typically fail to simultaneously meet two key requirements of CIR: comprehensively extracting visual information and faithfully following the user intent. In this work, we propose CIR-LVLM, a novel framework that leverages the large vision-language model (LVLM) as the powerful user intent-aware encoder to better meet these requirements. Our motivation is to explore the advanced reasoning and instruction-following capabilities of LVLM for accurately understanding and responding the user intent. Furthermore, we design a novel hybrid intent instruction module to provide explicit intent guidance at two levels: (1) The task prompt clarifies the task requirement and assists the model in discerning user intent at the task level. (2) The instance-specific soft prompt, which is adaptively selected from the learnable prompt pool, enables the model to better comprehend the user intent at the instance level compared to a universal prompt for all instances. CIR-LVLM achieves state-of-the-art performance across three prominent benchmarks with acceptable inference efficiency. We believe this study provides fundamental insights into CIR-related fields.
Awaker2.5-VL: Stably Scaling MLLMs with Parameter-Efficient Mixture of Experts
Nov 16, 2024As the research of Multimodal Large Language Models (MLLMs) becomes popular, an advancing MLLM model is typically required to handle various textual and visual tasks (e.g., VQA, Detection, OCR, and ChartQA) simultaneously for real-world applications. However, due to the significant differences in representation and distribution among data from various tasks, simply mixing data of all tasks together leads to the well-known``multi-task conflict" issue, resulting in performance degradation across various tasks. To address this issue, we propose Awaker2.5-VL, a Mixture of Experts~(MoE) architecture suitable for MLLM, which acquires the multi-task capabilities through multiple sparsely activated experts. To speed up the training and inference of Awaker2.5-VL, each expert in our model is devised as a low-rank adaptation (LoRA) structure. Extensive experiments on multiple latest benchmarks demonstrate the effectiveness of Awaker2.5-VL. The code and model weight are released in our Project Page: https://github.com/MetabrainAGI/Awaker.
Expert-level vision-language foundation model for real-world radiology and comprehensive evaluation
Sep 24, 2024



Radiology is a vital and complex component of modern clinical workflow and covers many tasks. Recently, vision-language (VL) foundation models in medicine have shown potential in processing multimodal information, offering a unified solution for various radiology tasks. However, existing studies either pre-trained VL models on natural data or did not fully integrate vision-language architecture and pretraining, often neglecting the unique multimodal complexity in radiology images and their textual contexts. Additionally, their practical applicability in real-world scenarios remains underexplored. Here, we present RadFound, a large and open-source vision-language foundation model tailored for radiology, that is trained on the most extensive dataset of over 8.1 million images and 250,000 image-text pairs, covering 19 major organ systems and 10 imaging modalities. To establish expert-level multimodal perception and generation capabilities, RadFound introduces an enhanced vision encoder to capture intra-image local features and inter-image contextual information, and a unified cross-modal learning design tailored to radiology. To fully assess the models' capability, we construct a benchmark, RadVLBench, including radiology interpretation tasks like medical vision-language question-answering, as well as text generation tasks ranging from captioning to report generation. We also propose a human evaluation framework. When evaluated on the real-world benchmark involving three representative modalities, 2D images (chest X-rays), multi-view images (mammograms), and 3D images (thyroid CT scans), RadFound significantly outperforms other VL foundation models on both quantitative metrics and human evaluation. In summary, the development of RadFound represents an advancement in radiology generalists, demonstrating broad applicability potential for integration into clinical workflows.
MoVL:Exploring Fusion Strategies for the Domain-Adaptive Application of Pretrained Models in Medical Imaging Tasks
May 13, 2024



Medical images are often more difficult to acquire than natural images due to the specialism of the equipment and technology, which leads to less medical image datasets. So it is hard to train a strong pretrained medical vision model. How to make the best of natural pretrained vision model and adapt in medical domain still pends. For image classification, a popular method is linear probe (LP). However, LP only considers the output after feature extraction. Yet, there exists a gap between input medical images and natural pretrained vision model. We introduce visual prompting (VP) to fill in the gap, and analyze the strategies of coupling between LP and VP. We design a joint learning loss function containing categorisation loss and discrepancy loss, which describe the variance of prompted and plain images, naming this joint training strategy MoVL (Mixture of Visual Prompting and Linear Probe). We experiment on 4 medical image classification datasets, with two mainstream architectures, ResNet and CLIP. Results shows that without changing the parameters and architecture of backbone model and with less parameters, there is potential for MoVL to achieve full finetune (FF) accuracy (on four medical datasets, average 90.91% for MoVL and 91.13% for FF). On out of distribution medical dataset, our method(90.33%) can outperform FF (85.15%) with absolute 5.18 % lead.
TCM-GPT: Efficient Pre-training of Large Language Models for Domain Adaptation in Traditional Chinese Medicine
Nov 03, 2023Pre-training and fine-tuning have emerged as a promising paradigm across various natural language processing (NLP) tasks. The effectiveness of pretrained large language models (LLM) has witnessed further enhancement, holding potential for applications in the field of medicine, particularly in the context of Traditional Chinese Medicine (TCM). However, the application of these general models to specific domains often yields suboptimal results, primarily due to challenges like lack of domain knowledge, unique objectives, and computational efficiency. Furthermore, their effectiveness in specialized domains, such as Traditional Chinese Medicine, requires comprehensive evaluation. To address the above issues, we propose a novel domain specific TCMDA (TCM Domain Adaptation) approach, efficient pre-training with domain-specific corpus. Specifically, we first construct a large TCM-specific corpus, TCM-Corpus-1B, by identifying domain keywords and retreving from general corpus. Then, our TCMDA leverages the LoRA which freezes the pretrained model's weights and uses rank decomposition matrices to efficiently train specific dense layers for pre-training and fine-tuning, efficiently aligning the model with TCM-related tasks, namely TCM-GPT-7B. We further conducted extensive experiments on two TCM tasks, including TCM examination and TCM diagnosis. TCM-GPT-7B archived the best performance across both datasets, outperforming other models by relative increments of 17% and 12% in accuracy, respectively. To the best of our knowledge, our study represents the pioneering validation of domain adaptation of a large language model with 7 billion parameters in TCM domain. We will release both TCMCorpus-1B and TCM-GPT-7B model once accepted to facilitate interdisciplinary development in TCM and NLP, serving as the foundation for further study.
ClinicalGPT: Large Language Models Finetuned with Diverse Medical Data and Comprehensive Evaluation
Jun 16, 2023



Large language models have exhibited exceptional performance on various Natural Language Processing (NLP) tasks, leveraging techniques such as the pre-training, and instruction fine-tuning. Despite these advances, their effectiveness in medical applications is limited, due to challenges such as factual inaccuracies, reasoning abilities, and lack grounding in real-world experience. In this study, we present ClinicalGPT, a language model explicitly designed and optimized for clinical scenarios. By incorporating extensive and diverse real-world data, such as medical records, domain-specific knowledge, and multi-round dialogue consultations in the training process, ClinicalGPT is better prepared to handle multiple clinical task. Furthermore, we introduce a comprehensive evaluation framework that includes medical knowledge question-answering, medical exams, patient consultations, and diagnostic analysis of medical records. Our results demonstrate that ClinicalGPT significantly outperforms other models in these tasks, highlighting the effectiveness of our approach in adapting large language models to the critical domain of healthcare.
VDT: An Empirical Study on Video Diffusion with Transformers
May 22, 2023This work introduces Video Diffusion Transformer (VDT), which pioneers the use of transformers in diffusion-based video generation. It features transformer blocks with modularized temporal and spatial attention modules, allowing separate optimization of each component and leveraging the rich spatial-temporal representation inherited from transformers. VDT offers several appealing benefits. 1) It excels at capturing temporal dependencies to produce temporally consistent video frames and even simulate the dynamics of 3D objects over time. 2) It enables flexible conditioning information through simple concatenation in the token space, effectively unifying video generation and prediction tasks. 3) Its modularized design facilitates a spatial-temporal decoupled training strategy, leading to improved efficiency. Extensive experiments on video generation, prediction, and dynamics modeling (i.e., physics-based QA) tasks have been conducted to demonstrate the effectiveness of VDT in various scenarios, including autonomous driving, human action, and physics-based simulation. We hope our study on the capabilities of transformer-based video diffusion in capturing accurate temporal dependencies, handling conditioning information, and achieving efficient training will benefit future research and advance the field. Codes and models are available at https://github.com/RERV/VDT.
UniAdapter: Unified Parameter-Efficient Transfer Learning for Cross-modal Modeling
Feb 13, 2023Large-scale vision-language pre-trained models have shown promising transferability to various downstream tasks. As the size of these foundation models and the number of downstream tasks grow, the standard full fine-tuning paradigm becomes unsustainable due to heavy computational and storage costs. This paper proposes UniAdapter, which unifies unimodal and multimodal adapters for parameter-efficient cross-modal adaptation on pre-trained vision-language models. Specifically, adapters are distributed to different modalities and their interactions, with the total number of tunable parameters reduced by partial weight sharing. The unified and knowledge-sharing design enables powerful cross-modal representations that can benefit various downstream tasks, requiring only 1.0%-2.0% tunable parameters of the pre-trained model. Extensive experiments on 6 cross-modal downstream benchmarks (including video-text retrieval, image-text retrieval, VideoQA, and VQA) show that in most cases, UniAdapter not only outperforms the state-of-the-arts, but even beats the full fine-tuning strategy. Particularly, on the MSRVTT retrieval task, UniAdapter achieves 49.7% recall@1 with 2.2% model parameters, outperforming the latest competitors by 2.0%. The code and models are available at https://github.com/RERV/UniAdapter.
WenLan 2.0: Make AI Imagine via a Multimodal Foundation Model
Oct 27, 2021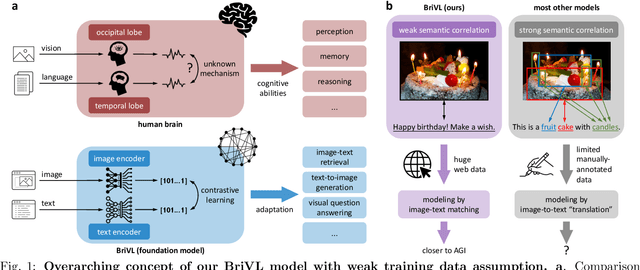


The fundamental goal of artificial intelligence (AI) is to mimic the core cognitive activities of human including perception, memory, and reasoning. Although tremendous success has been achieved in various AI research fields (e.g., computer vision and natural language processing), the majority of existing works only focus on acquiring single cognitive ability (e.g., image classification, reading comprehension, or visual commonsense reasoning). To overcome this limitation and take a solid step to artificial general intelligence (AGI), we develop a novel foundation model pre-trained with huge multimodal (visual and textual) data, which is able to be quickly adapted for a broad class of downstream cognitive tasks. Such a model is fundamentally different from the multimodal foundation models recently proposed in the literature that typically make strong semantic correlation assumption and expect exact alignment between image and text modalities in their pre-training data, which is often hard to satisfy in practice thus limiting their generalization abilities. To resolve this issue, we propose to pre-train our foundation model by self-supervised learning with weak semantic correlation data crawled from the Internet and show that state-of-the-art results can be obtained on a wide range of downstream tasks (both single-modal and cross-modal). Particularly, with novel model-interpretability tools developed in this work, we demonstrate that strong imagination ability (even with hints of commonsense) is now possessed by our foundation model. We believe our work makes a transformative stride towards AGI and will have broad impact on various AI+ fields (e.g., neuroscience and healthcare).