 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen-VLA: Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments
May 28, 2026Embodied intelligence is often studied through specialized models for individual tasks such as manipulation or navigation, resulting in fragmented capabilities and limited generalization across tasks, environments, and robot embodiments. In this work, we study whether heterogeneous embodied decision-making problems can be unified within a single vision-language-action model. We present Qwen-VLA, a unified embodied foundation model that extends Qwen's vision-language modeling stack from perception, understanding, and reasoning to continuous action and trajectory generation through a DiT-based action decoder. Qwen-VLA is trained with a large-scale joint pretraining recipe over diverse data sources, including robotics manipulation trajectories, human egocentric demonstrations, synthetic simulation data, vision-and-language navigation data, trajectory-centric supervision, and auxiliary vision-language data. To support multiple robot platforms, we introduce embodiment-aware prompt conditioning, where robot-specific textual descriptions specify the current embodiment and control convention. We further cast manipulation, navigation, and trajectory prediction into a unified action-and-trajectory prediction framework, enabling transferable visual grounding, spatial reasoning, and continuous action generation across robot morphologies, task families, and environments. Experiments on manipulation, navigation, and trajectory-centric benchmarks show consistent multi-task performance and out-of-distribution generalization under variations in scene layout, background, lighting, object configuration, and robot embodiment. Qwen-VLA-Instruct achieves 97.9% on LIBERO, 73.7% on Simpler-WidowX, 86.1%/87.2% on RoboTwin-Easy/Hard, 69.0% OSR on R2R, 59.6% SR on RxR, 76.9% average OOD success in real-world ALOHA experiments, and 26.6% zero-shot success on DOMINO dynamic manipulation.
FineVLA: Fine-Grained Instruction Alignment for Steerable Vision-Language-Action Policies
May 26, 2026Vision-Language-Action (VLA) models are increasingly expected to not only complete robot tasks, but also follow human instructions about how those tasks should be executed. However, existing robot datasets usually pair trajectories with coarse goal-level language, leaving execution-critical details such as active arm, approach direction, and contact region unspecified. This limits steerable policy learning and robotic video understanding. We introduce FineVLA, an open framework for action-aligned fine-grained VLA supervision. The framework includes: (1) a data construction tool that unifies 972,247 trajectories across 85K tasks from 10 open-source robot datasets and builds FineVLA-Data, a human-verified dataset of 47,159 fine-grained trajectories; (2) a held-out benchmark with 500 videos, 10,816 atomic facts, and 1,030 VQA questions; (3) a robotics-specialized VLM annotator for scalable fine-grained annotation; and (4) a steerable VLA policy trained with controlled mixtures of fine-grained and raw goal-level instructions. Our experiments yield three findings. First, fine-grained supervision does not sacrifice goal-level success: FG-only improves over Raw-only by +1.4 to +8.1 success-rate points across settings. Second, fine-grained and raw instructions are complementary, following a consistent inverted-U trend peaking at FG:Raw = 1:2 to 1:1. The best mixed setting reaches 86.8%/82.5% in RoboTwin simulation and 62.7/100 in real-world dual-arm manipulation (vs. 49.9 Raw-only). Third, fine-grained supervision improves steerable control: the largest real-world gains appear on pose (+23), color (+18), and approach direction (+18)--factors where goal-level instructions provide no guidance. Overall, fine-grained language should augment goal-level instructions: specifying how to execute alongside what to achieve. Project page: https://finevla.xlang.ai/
Learning Transferable Temporal Primitives for Video Reasoning via Synthetic Videos
Mar 18, 2026The transition from image to video understanding requires vision-language models (VLMs) to shift from recognizing static patterns to reasoning over temporal dynamics such as motion trajectories, speed changes, and state transitions. Yet current post-training methods fall short due to two critical limitations: (1) existing datasets often lack temporal-centricity, where answers can be inferred from isolated keyframes rather than requiring holistic temporal integration; and (2) training data generated by proprietary models contains systematic errors in fundamental temporal perception, such as confusing motion directions or misjudging speeds. We introduce SynRL, a post-training framework that teaches models temporal primitives, the fundamental building blocks of temporal understanding including direction, speed, and state tracking. Our key insight is that these abstract primitives, learned from programmatically generated synthetic videos, transfer effectively to real-world scenarios. We decompose temporal understanding into short-term perceptual primitives (speed, direction) and long-term cognitive primitives, constructing 7.7K CoT and 7K RL samples with ground-truth frame-level annotations through code-based video generation. Despite training on simple geometric shapes, SynRL achieves substantial improvements across 15 benchmarks spanning temporal grounding, complex reasoning, and general video understanding. Remarkably, our 7.7K synthetic CoT samples outperform Video-R1 with 165K real-world samples. We attribute this to fundamental temporal skills, such as tracking frame by frame changes and comparing velocity, that transfer effectively from abstract synthetic patterns to complex real-world scenarios. This establishes a new paradigm for video post-training: video temporal learning through carefully designed synthetic data provides a more cost efficient scaling path.
JavisGPT: A Unified Multi-modal LLM for Sounding-Video Comprehension and Generation
Dec 28, 2025This paper presents JavisGPT, the first unified multimodal large language model (MLLM) for Joint Audio-Video (JAV) comprehension and generation. JavisGPT adopts a concise encoder-LLM-decoder architecture, featuring a SyncFusion module for spatio-temporal audio-video fusion and synchrony-aware learnable queries to bridge a pretrained JAV-DiT generator. This design enables temporally coherent video-audio understanding and generation from multimodal instructions. We design an effective three-stage training pipeline consisting of multimodal pretraining, audio-video fine-tuning, and large-scale instruction-tuning, to progressively build multimodal comprehension and generation from existing vision-language models. To support this, we further construct JavisInst-Omni, a high-quality instruction dataset with over 200K GPT-4o-curated audio-video-text dialogues that span diverse and multi-level comprehension and generation scenarios. Extensive experiments on JAV comprehension and generation benchmarks show that JavisGPT outperforms existing MLLMs, particularly in complex and temporally synchronized settings.
JointAVBench: A Benchmark for Joint Audio-Visual Reasoning Evaluation
Dec 14, 2025Understanding videos inherently requires reasoning over both visual and auditory information. To properly evaluate Omni-Large Language Models (Omni-LLMs), which are capable of processing multi-modal information including vision and audio, an effective benchmark must comprehensively cover three key aspects: (1) multi-modal dependency (i.e., questions that cannot be answered using vision or audio alone), (2) diverse audio information types (e.g., speech, sound events), and (3) varying scene spans. However, existing datasets fall short in one or more of these dimensions, limiting strict and comprehensive evaluation. To address this gap, we introduce JointAVBench, a novel benchmark with strict audio-video correlation, spanning five cognitive dimensions, four audio information types (speech, sound events, music, vocal traits), and three scene spans (single-, cross-, and full-scene). Given the high cost of manual annotation, we propose an automated pipeline that leverages state-of-the-art vision-LLMs, audio-LLMs, and general-purpose LLMs to synthesize questions and answers that strictly require joint audio-visual understanding. We evaluate leading vision-only, audio-only, and Omni-LLMs on our dataset. Results show that even the best-performing Omni-LLM achieves an average accuracy of only 62.6\%, outperforming uni-modal baselines but revealing substantial room for improvement, especially in cross-scene reasoning.
BSharedRAG: Backbone Shared Retrieval-Augmented Generation for the E-commerce Domain
Sep 30, 2024



Retrieval Augmented Generation (RAG) system is important in domains such as e-commerce, which has many long-tail entities and frequently updated information. Most existing works adopt separate modules for retrieval and generation, which may be suboptimal since the retrieval task and the generation task cannot benefit from each other to improve performance. We propose a novel Backbone Shared RAG framework (BSharedRAG). It first uses a domain-specific corpus to continually pre-train a base model as a domain-specific backbone model and then trains two plug-and-play Low-Rank Adaptation (LoRA) modules based on the shared backbone to minimize retrieval and generation losses respectively. Experimental results indicate that our proposed BSharedRAG outperforms baseline models by 5% and 13% in Hit@3 upon two datasets in retrieval evaluation and by 23% in terms of BLEU-3 in generation evaluation. Our codes, models, and dataset are available at https://bsharedrag.github.io.
Parrot: Enhancing Multi-Turn Chat Models by Learning to Ask Questions
Oct 11, 2023



Impressive progress has been made on chat models based on Large Language Models (LLMs) recently; however, there is a noticeable lag in multi-turn conversations between open-source chat models (e.g., Alpaca and Vicuna) and the leading chat models (e.g., ChatGPT and GPT-4). Through a series of analyses, we attribute the lag to the lack of enough high-quality multi-turn instruction-tuning data. The available instruction-tuning data for the community are either single-turn conversations or multi-turn ones with certain issues, such as non-human-like instructions, less detailed responses, or rare topic shifts. In this paper, we address these challenges by introducing Parrot, a highly scalable solution designed to automatically generate high-quality instruction-tuning data, which are then used to enhance the effectiveness of chat models in multi-turn conversations. Specifically, we start by training the Parrot-Ask model, which is designed to emulate real users in generating instructions. We then utilize Parrot-Ask to engage in multi-turn conversations with ChatGPT across a diverse range of topics, resulting in a collection of 40K high-quality multi-turn dialogues (Parrot-40K). These data are subsequently employed to train a chat model that we have named Parrot-Chat. We demonstrate that the dialogues gathered from Parrot-Ask markedly outperform existing multi-turn instruction-following datasets in critical metrics, including topic diversity, number of turns, and resemblance to human conversation. With only 40K training examples, Parrot-Chat achieves strong performance against other 13B open-source models across a range of instruction-following benchmarks, and particularly excels in evaluations of multi-turn capabilities. We make all codes, datasets, and two versions of the Parrot-Ask model based on LLaMA2-13B and KuaiYii-13B available at https://github.com/kwai/KwaiYii/Parrot.
ViCo: Engaging Video Comment Generation with Human Preference Rewards
Aug 22, 2023



Engaging video comments play an important role in video social media, as they are the carrier of feelings, thoughts, or humor of the audience. Preliminary works have made initial exploration for video comment generation by adopting caption-style encoder-decoder models. However, comment generation presents some unique challenges distinct from caption generation, which makes these methods somewhat less effective at generating engaging comments. In contrast to the objective and descriptive nature of captions, comments tend to be inherently subjective, making it hard to quantify and evaluate the engagement of comments. Furthermore, the scarcity of truly engaging comments brings difficulty to collecting enough high-quality training examples. In this paper, we propose ViCo with three novel designs to tackle the above challenges for generating engaging Video Comments. Firstly, to quantify the engagement of comments, we utilize the number of "likes" each comment receives as a proxy of human preference after an appropriate debiasing procedure. Secondly, to automatically evaluate the engagement of comments, we train a reward model to align its judgment to the above proxy. Our user studies indicate that this reward model effectively aligns with human judgments. Lastly, to alleviate the scarcity of high-quality comments, an initial generator is trained on readily available but noisy data to generate comments. Then the reward model is employed to offer feedback on the generated comments, thus optimizing the initial generator. To facilitate the research of video commenting, we collect a large video comment-dataset (ViCo-20k) with rich metadata from a popular video website. Experiments on ViCo-20k show that the comments generated by our ViCo model exhibit the best performance in terms of both quantitative and qualitative results, particularly when engagement is considered.
Translating Text Synopses to Video Storyboards
Dec 31, 2022



A storyboard is a roadmap for video creation which consists of shot-by-shot images to visualize key plots in a text synopsis. Creating video storyboards however remains challenging which not only requires association between high-level texts and images, but also demands for long-term reasoning to make transitions smooth across shots. In this paper, we propose a new task called Text synopsis to Video Storyboard (TeViS) which aims to retrieve an ordered sequence of images to visualize the text synopsis. We construct a MovieNet-TeViS benchmark based on the public MovieNet dataset. It contains 10K text synopses each paired with keyframes that are manually selected from corresponding movies by considering both relevance and cinematic coherence. We also present an encoder-decoder baseline for the task. The model uses a pretrained vision-and-language model to improve high-level text-image matching. To improve coherence in long-term shots, we further propose to pre-train the decoder on large-scale movie frames without text. Experimental results demonstrate that our proposed model significantly outperforms other models to create text-relevant and coherent storyboards. Nevertheless, there is still a large gap compared to human performance suggesting room for promising future work.
Long-Form Video-Language Pre-Training with Multimodal Temporal Contrastive Learning
Oct 12, 2022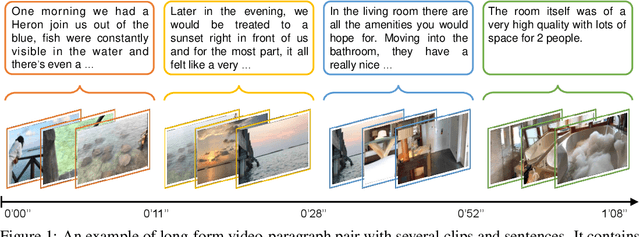
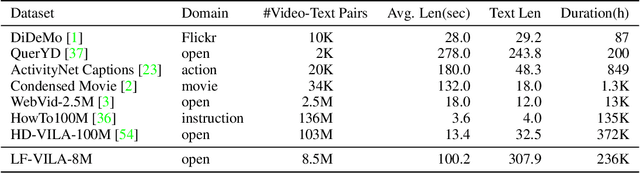
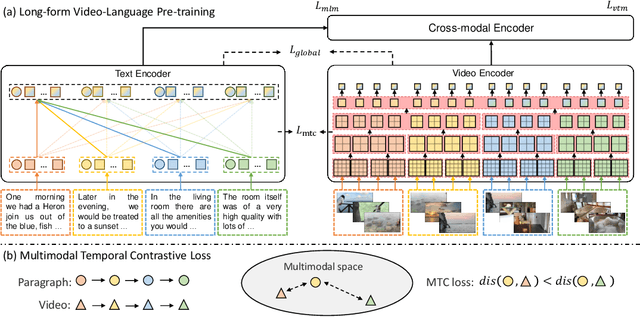
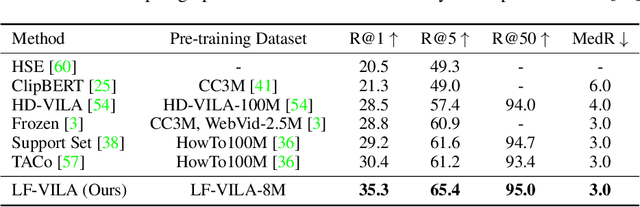
Large-scale video-language pre-training has shown significant improvement in video-language understanding tasks. Previous studies of video-language pretraining mainly focus on short-form videos (i.e., within 30 seconds) and sentences, leaving long-form video-language pre-training rarely explored. Directly learning representation from long-form videos and language may benefit many long-form video-language understanding tasks. However, it is challenging due to the difficulty of modeling long-range relationships and the heavy computational burden caused by more frames. In this paper, we introduce a Long-Form VIdeo-LAnguage pre-training model (LF-VILA) and train it on a large-scale long-form video and paragraph dataset constructed from an existing public dataset. To effectively capture the rich temporal dynamics and to better align video and language in an efficient end-to-end manner, we introduce two novel designs in our LF-VILA model. We first propose a Multimodal Temporal Contrastive (MTC) loss to learn the temporal relation across different modalities by encouraging fine-grained alignment between long-form videos and paragraphs. Second, we propose a Hierarchical Temporal Window Attention (HTWA) mechanism to effectively capture long-range dependency while reducing computational cost in Transformer. We fine-tune the pre-trained LF-VILA model on seven downstream long-form video-language understanding tasks of paragraph-to-video retrieval and long-form video question-answering, and achieve new state-of-the-art performances. Specifically, our model achieves 16.1% relative improvement on ActivityNet paragraph-to-video retrieval task and 2.4% on How2QA task, respectively. We release our code, dataset, and pre-trained models at https://github.com/microsoft/XPretrain.