 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClimber-Pilot: A Non-Myopic Generative Recommendation Model Towards Better Instruction-Following
Feb 14, 2026Generative retrieval has emerged as a promising paradigm in recommender systems, offering superior sequence modeling capabilities over traditional dual-tower architectures. However, in large-scale industrial scenarios, such models often suffer from inherent myopia: due to single-step inference and strict latency constraints, they tend to collapse diverse user intents into locally optimal predictions, failing to capture long-horizon and multi-item consumption patterns. Moreover, real-world retrieval systems must follow explicit retrieval instructions, such as category-level control and policy constraints. Incorporating such instruction-following behavior into generative retrieval remains challenging, as existing conditioning or post-hoc filtering approaches often compromise relevance or efficiency. In this work, we present Climber-Pilot, a unified generative retrieval framework to address both limitations. First, we introduce Time-Aware Multi-Item Prediction (TAMIP), a novel training paradigm designed to mitigate inherent myopia in generative retrieval. By distilling long-horizon, multi-item foresight into model parameters through time-aware masking, TAMIP alleviates locally optimal predictions while preserving efficient single-step inference. Second, to support flexible instruction-following retrieval, we propose Condition-Guided Sparse Attention (CGSA), which incorporates business constraints directly into the generative process via sparse attention, without introducing additional inference steps. Extensive offline experiments and online A/B testing at NetEase Cloud Music, one of the largest music streaming platforms, demonstrate that Climber-Pilot significantly outperforms state-of-the-art baselines, achieving a 4.24\% lift of the core business metric.
Bootstrap Model Ensemble and Rank Loss for Engagement Intensity Regression
Jul 08, 2019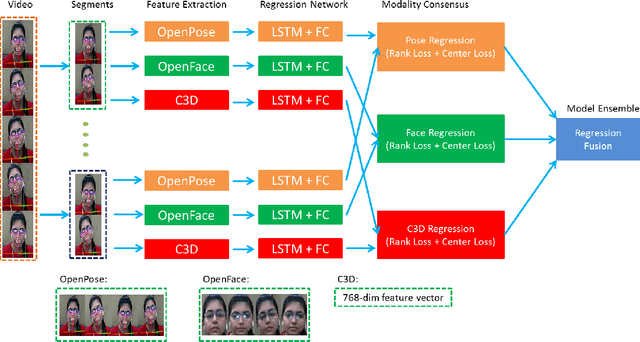
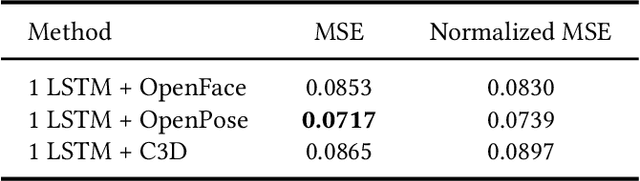
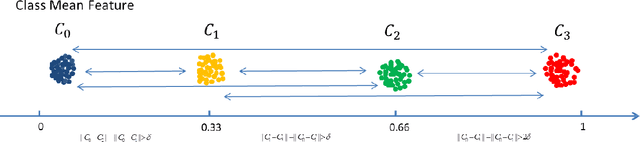
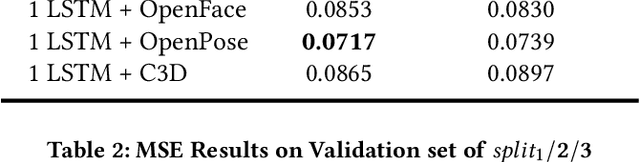
This paper presents our approach for the engagement intensity regression task of EmotiW 2019. The task is to predict the engagement intensity value of a student when he or she is watching an online MOOCs video in various conditions. Based on our winner solution last year, we mainly explore head features and body features with a bootstrap strategy and two novel loss functions in this paper. We maintain the framework of multi-instance learning with long short-term memory (LSTM) network, and make three contributions. First, besides of the gaze and head pose features, we explore facial landmark features in our framework. Second, inspired by the fact that engagement intensity can be ranked in values, we design a rank loss as a regularization which enforces a distance margin between the features of distant category pairs and adjacent category pairs. Third, we use the classical bootstrap aggregation method to perform model ensemble which randomly samples a certain training data by several times and then averages the model predictions. We evaluate the performance of our method and discuss the influence of each part on the validation dataset. Our methods finally win 3rd place with MSE of 0.0626 on the testing set.