 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGSwap: Realistic Head Swapping with Dynamic Neural Gaussian Field
Mar 24, 2026We present GSwap, a novel consistent and realistic video head-swapping system empowered by dynamic neural Gaussian portrait priors, which significantly advances the state of the art in face and head replacement. Unlike previous methods that rely primarily on 2D generative models or 3D Morphable Face Models (3DMM), our approach overcomes their inherent limitations, including poor 3D consistency, unnatural facial expressions, and restricted synthesis quality. Moreover, existing techniques struggle with full head-swapping tasks due to insufficient holistic head modeling and ineffective background blending, often resulting in visible artifacts and misalignments. To address these challenges, GSwap introduces an intrinsic 3D Gaussian feature field embedded within a full-body SMPL-X surface, effectively elevating 2D portrait videos into a dynamic neural Gaussian field. This innovation ensures high-fidelity, 3D-consistent portrait rendering while preserving natural head-torso relationships and seamless motion dynamics. To facilitate training, we adapt a pretrained 2D portrait generative model to the source head domain using only a few reference images, enabling efficient domain adaptation. Furthermore, we propose a neural re-rendering strategy that harmoniously integrates the synthesized foreground with the original background, eliminating blending artifacts and enhancing realism. Extensive experiments demonstrate that GSwap surpasses existing methods in multiple aspects, including visual quality, temporal coherence, identity preservation, and 3D consistency.
ProgressiveAvatars: Progressive Animatable 3D Gaussian Avatars
Mar 17, 2026In practical real-time XR and telepresence applications, network and computing resources fluctuate frequently. Therefore, a progressive 3D representation is needed. To this end, we propose ProgressiveAvatars, a progressive avatar representation built on a hierarchy of 3D Gaussians grown by adaptive implicit subdivision on a template mesh. 3D Gaussians are defined in face-local coordinates to remain animatable under varying expressions and head motion across multiple detail levels. The hierarchy expands when screen-space signals indicate a lack of detail, allocating resources to important areas. Leveraging importance ranking, ProgressiveAvatars supports incremental loading and rendering, adding new Gaussians as they arrive while preserving previous content, thus achieving smooth quality improvements across varying bandwidths. ProgressiveAvatars enables progressive delivery and progressive rendering under fluctuating network bandwidth and varying compute and memory resources.
Easy3E: Feed-Forward 3D Asset Editing via Rectified Voxel Flow
Feb 25, 2026Existing 3D editing methods rely on computationally intensive scene-by-scene iterative optimization and suffer from multi-view inconsistency. We propose an effective and fully feedforward 3D editing framework based on the TRELLIS generative backbone, capable of modifying 3D models from a single editing view. Our framework addresses two key issues: adapting training-free 2D editing to structured 3D representations, and overcoming the bottleneck of appearance fidelity in compressed 3D features. To ensure geometric consistency, we introduce Voxel FlowEdit, an edit-driven flow in the sparse voxel latent space that achieves globally consistent 3D deformation in a single pass. To restore high-fidelity details, we develop a normal-guided single to multi-view generation module as an external appearance prior, successfully recovering high-frequency textures. Experiments demonstrate that our method enables fast, globally consistent, and high-fidelity 3D model editing.
ExpPortrait: Expressive Portrait Generation via Personalized Representation
Feb 23, 2026While diffusion models have shown great potential in portrait generation, generating expressive, coherent, and controllable cinematic portrait videos remains a significant challenge. Existing intermediate signals for portrait generation, such as 2D landmarks and parametric models, have limited disentanglement capabilities and cannot express personalized details due to their sparse or low-rank representation. Therefore, existing methods based on these models struggle to accurately preserve subject identity and expressions, hindering the generation of highly expressive portrait videos. To overcome these limitations, we propose a high-fidelity personalized head representation that more effectively disentangles expression and identity. This representation captures both static, subject-specific global geometry and dynamic, expression-related details. Furthermore, we introduce an expression transfer module to achieve personalized transfer of head pose and expression details between different identities. We use this sophisticated and highly expressive head model as a conditional signal to train a diffusion transformer (DiT)-based generator to synthesize richly detailed portrait videos. Extensive experiments on self- and cross-reenactment tasks demonstrate that our method outperforms previous models in terms of identity preservation, expression accuracy, and temporal stability, particularly in capturing fine-grained details of complex motion.
Channel Knowledge Map Construction: Recent Advances and Open Challenges
Nov 07, 2025Channel knowledge map (CKM) has emerged as a pivotal technology for environment-aware wireless communications and sensing, which provides a priori location-specific channel knowledge to facilitate network optimization. Efficient CKM construction is an important technical problem for its effective implementation. This article provides a comprehensive overview of recent advances in CKM construction. First, we examine classical interpolation-based CKM construction methods, highlighting their limitations in practical deployments. Next, we explore image processing and generative artificial intelligence (AI) techniques, which leverage feature extraction to construct CKMs based on environmental knowledge. Furthermore, we present emerging wireless radiance field (WRF) frameworks that exploit neural radiance fields or Gaussian splatting to construct high-fidelity CKMs from sparse measurement data. Finally, we outline various future research directions in real-time and cross-domain CKM construction, as well as cost-efficient deployment of CKMs.
6D Channel Knowledge Map Construction via Bidirectional Wireless Gaussian Splatting
Oct 30, 2025
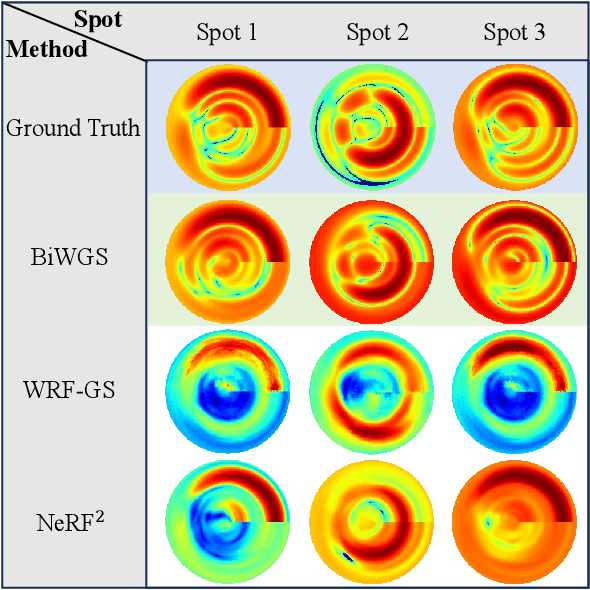
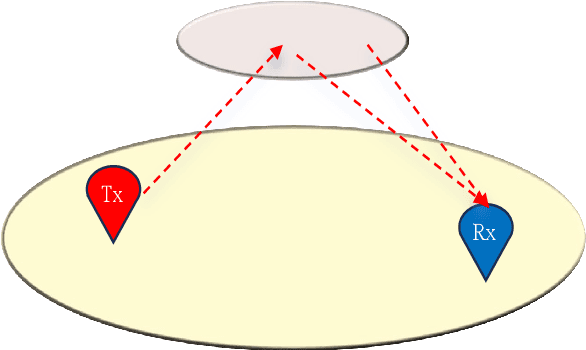
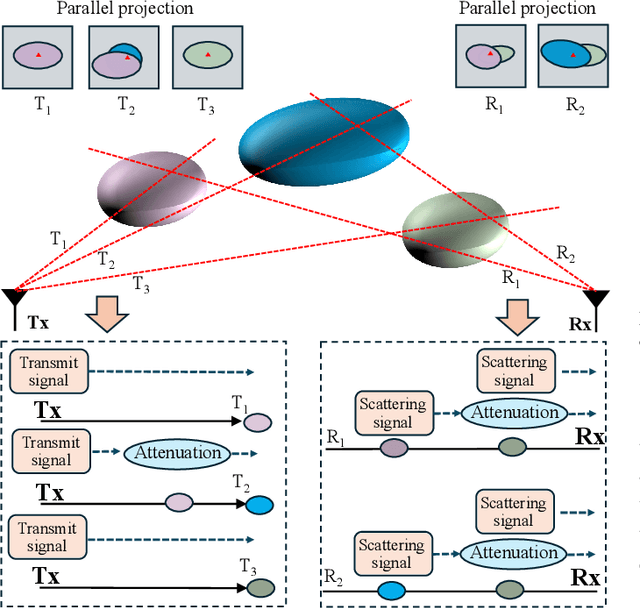
This paper investigates the construction of channel knowledge map (CKM) from sparse channel measurements. Dif ferent from conventional two-/three-dimensional (2D/3D) CKM approaches assuming fixed base station configurations, we present a six-dimensional (6D) CKM framework named bidirectional wireless Gaussian splatting (BiWGS), which is capable of mod eling wireless channels across dynamic transmitter (Tx) and receiver (Rx) positions in 3D space. BiWGS uses Gaussian el lipsoids to represent virtual scatterer clusters and environmental obstacles in the wireless environment. By properly learning the bidirectional scattering patterns and complex attenuation profiles based on channel measurements, these ellipsoids inherently cap ture the electromagnetic transmission characteristics of wireless environments, thereby accurately modeling signal transmission under varying transceiver configurations. Experiment results show that BiWGS significantly outperforms classic multi-layer perception (MLP) for the construction of 6D channel power gain map with varying Tx-Rx positions, and achieves spatial spectrum prediction accuracy comparable to the state-of-the art wireless radiation field Gaussian splatting (WRF-GS) for 3D CKM construction. This validates the capability of the proposed BiWGS in accomplishing dimensional expansion of 6D CKM construction, without compromising fidelity.
Joint Deblurring and 3D Reconstruction for Macrophotography
Oct 02, 2025


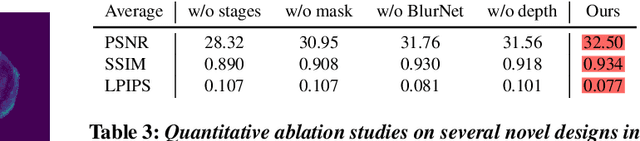
Macro lens has the advantages of high resolution and large magnification, and 3D modeling of small and detailed objects can provide richer information. However, defocus blur in macrophotography is a long-standing problem that heavily hinders the clear imaging of the captured objects and high-quality 3D reconstruction of them. Traditional image deblurring methods require a large number of images and annotations, and there is currently no multi-view 3D reconstruction method for macrophotography. In this work, we propose a joint deblurring and 3D reconstruction method for macrophotography. Starting from multi-view blurry images captured, we jointly optimize the clear 3D model of the object and the defocus blur kernel of each pixel. The entire framework adopts a differentiable rendering method to self-supervise the optimization of the 3D model and the defocus blur kernel. Extensive experiments show that from a small number of multi-view images, our proposed method can not only achieve high-quality image deblurring but also recover high-fidelity 3D appearance.
DualReg: Dual-Space Filtering and Reinforcement for Rigid Registration
Aug 23, 2025Rigid registration, aiming to estimate a rigid transformation to align source and target data, play a crucial role in applications such as SLAM and 3D reconstruction. However, noisy, partially overlapping data and the need for real-time processing pose major challenges for rigid registration. Considering that feature-based matching can handle large transformation differences but suffers from limited accuracy, while local geometry-based matching can achieve fine-grained local alignment but relies heavily on a good initial transformation, we propose a novel dual-space paradigm to fully leverage the strengths of both approaches. First, we introduce an efficient filtering mechanism that incorporates a computationally lightweight single-point RANSAC algorithm followed by a refinement module to eliminate unreliable feature-based correspondences. Subsequently, we treat filtered correspondences as anchor points, extract geometric proxies, and formulates an effective objective function with a tailored solver to estimate the transformation. Experiments verify our method's effectiveness, as shown by achieving up to a 32x CPU-time speedup over MAC on KITTI with comparable accuracy.
Controlling Avatar Diffusion with Learnable Gaussian Embedding
Mar 20, 2025Recent advances in diffusion models have made significant progress in digital human generation. However, most existing models still struggle to maintain 3D consistency, temporal coherence, and motion accuracy. A key reason for these shortcomings is the limited representation ability of commonly used control signals(e.g., landmarks, depth maps, etc.). In addition, the lack of diversity in identity and pose variations in public datasets further hinders progress in this area. In this paper, we analyze the shortcomings of current control signals and introduce a novel control signal representation that is optimizable, dense, expressive, and 3D consistent. Our method embeds a learnable neural Gaussian onto a parametric head surface, which greatly enhances the consistency and expressiveness of diffusion-based head models. Regarding the dataset, we synthesize a large-scale dataset with multiple poses and identities. In addition, we use real/synthetic labels to effectively distinguish real and synthetic data, minimizing the impact of imperfections in synthetic data on the generated head images. Extensive experiments show that our model outperforms existing methods in terms of realism, expressiveness, and 3D consistency. Our code, synthetic datasets, and pre-trained models will be released in our project page: https://ustc3dv.github.io/Learn2Control/
Scalable and High-Quality Neural Implicit Representation for 3D Reconstruction
Jan 15, 2025Various SDF-based neural implicit surface reconstruction methods have been proposed recently, and have demonstrated remarkable modeling capabilities. However, due to the global nature and limited representation ability of a single network, existing methods still suffer from many drawbacks, such as limited accuracy and scale of the reconstruction. In this paper, we propose a versatile, scalable and high-quality neural implicit representation to address these issues. We integrate a divide-and-conquer approach into the neural SDF-based reconstruction. Specifically, we model the object or scene as a fusion of multiple independent local neural SDFs with overlapping regions. The construction of our representation involves three key steps: (1) constructing the distribution and overlap relationship of the local radiance fields based on object structure or data distribution, (2) relative pose registration for adjacent local SDFs, and (3) SDF blending. Thanks to the independent representation of each local region, our approach can not only achieve high-fidelity surface reconstruction, but also enable scalable scene reconstruction. Extensive experimental results demonstrate the effectiveness and practicality of our proposed method.