 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLumina-mGPT 2.0: Stand-Alone AutoRegressive Image Modeling
Jul 23, 2025
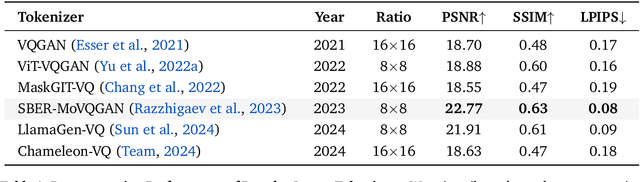
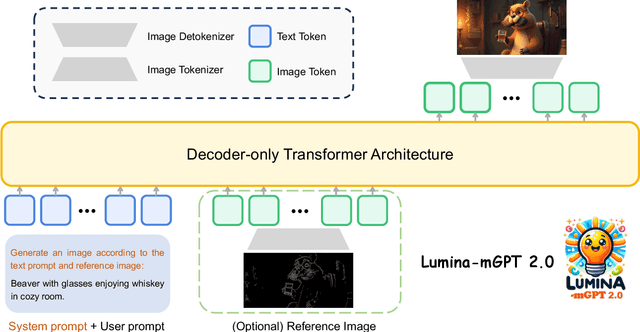

We present Lumina-mGPT 2.0, a stand-alone, decoder-only autoregressive model that revisits and revitalizes the autoregressive paradigm for high-quality image generation and beyond. Unlike existing approaches that rely on pretrained components or hybrid architectures, Lumina-mGPT 2.0 is trained entirely from scratch, enabling unrestricted architectural design and licensing freedom. It achieves generation quality on par with state-of-the-art diffusion models such as DALL-E 3 and SANA, while preserving the inherent flexibility and compositionality of autoregressive modeling. Our unified tokenization scheme allows the model to seamlessly handle a wide spectrum of tasks-including subject-driven generation, image editing, controllable synthesis, and dense prediction-within a single generative framework. To further boost usability, we incorporate efficient decoding strategies like inference-time scaling and speculative Jacobi sampling to improve quality and speed, respectively. Extensive evaluations on standard text-to-image benchmarks (e.g., GenEval, DPG) demonstrate that Lumina-mGPT 2.0 not only matches but in some cases surpasses diffusion-based models. Moreover, we confirm its multi-task capabilities on the Graph200K benchmark, with the native Lumina-mGPT 2.0 performing exceptionally well. These results position Lumina-mGPT 2.0 as a strong, flexible foundation model for unified multimodal generation. We have released our training details, code, and models at https://github.com/Alpha-VLLM/Lumina-mGPT-2.0.
The Ever-Evolving Science Exam
Jul 22, 2025



As foundation models grow rapidly in capability and deployment, evaluating their scientific understanding becomes increasingly critical. Existing science benchmarks have made progress towards broad **Range**, wide **Reach**, and high **Rigor**, yet they often face two major challenges: **data leakage risks** that compromise benchmarking validity, and **evaluation inefficiency** due to large-scale testing. To address these issues, we introduce the **Ever-Evolving Science Exam (EESE)**, a dynamic benchmark designed to reliably assess scientific capabilities in foundation models. Our approach consists of two components: 1) a non-public **EESE-Pool** with over 100K expertly constructed science instances (question-answer pairs) across 5 disciplines and 500+ subfields, built through a multi-stage pipeline ensuring **Range**, **Reach**, and **Rigor**, 2) a periodically updated 500-instance subset **EESE**, sampled and validated to enable leakage-resilient, low-overhead evaluations. Experiments on 32 open- and closed-source models demonstrate that EESE effectively differentiates the strengths and weaknesses of models in scientific fields and cognitive dimensions. Overall, EESE provides a robust, scalable, and forward-compatible solution for science benchmark design, offering a realistic measure of how well foundation models handle science questions. The project page is at: https://github.com/aiben-ch/EESE.
Resurrect Mask AutoRegressive Modeling for Efficient and Scalable Image Generation
Jul 17, 2025



AutoRegressive (AR) models have made notable progress in image generation, with Masked AutoRegressive (MAR) models gaining attention for their efficient parallel decoding. However, MAR models have traditionally underperformed when compared to standard AR models. This study refines the MAR architecture to improve image generation quality. We begin by evaluating various image tokenizers to identify the most effective one. Subsequently, we introduce an improved Bidirectional LLaMA architecture by replacing causal attention with bidirectional attention and incorporating 2D RoPE, which together form our advanced model, MaskGIL. Scaled from 111M to 1.4B parameters, MaskGIL achieves a FID score of 3.71, matching state-of-the-art AR models in the ImageNet 256x256 benchmark, while requiring only 8 inference steps compared to the 256 steps of AR models. Furthermore, we develop a text-driven MaskGIL model with 775M parameters for generating images from text at various resolutions. Beyond image generation, MaskGIL extends to accelerate AR-based generation and enable real-time speech-to-image conversion. Our codes and models are available at https://github.com/synbol/MaskGIL.
CompressedVQA-HDR: Generalized Full-reference and No-reference Quality Assessment Models for Compressed High Dynamic Range Videos
Jul 16, 2025Video compression is a standard procedure applied to all videos to minimize storage and transmission demands while preserving visual quality as much as possible. Therefore, evaluating the visual quality of compressed videos is crucial for guiding the practical usage and further development of video compression algorithms. Although numerous compressed video quality assessment (VQA) methods have been proposed, they often lack the generalization capability needed to handle the increasing diversity of video types, particularly high dynamic range (HDR) content. In this paper, we introduce CompressedVQA-HDR, an effective VQA framework designed to address the challenges of HDR video quality assessment. Specifically, we adopt the Swin Transformer and SigLip 2 as the backbone networks for the proposed full-reference (FR) and no-reference (NR) VQA models, respectively. For the FR model, we compute deep structural and textural similarities between reference and distorted frames using intermediate-layer features extracted from the Swin Transformer as its quality-aware feature representation. For the NR model, we extract the global mean of the final-layer feature maps from SigLip 2 as its quality-aware representation. To mitigate the issue of limited HDR training data, we pre-train the FR model on a large-scale standard dynamic range (SDR) VQA dataset and fine-tune it on the HDRSDR-VQA dataset. For the NR model, we employ an iterative mixed-dataset training strategy across multiple compressed VQA datasets, followed by fine-tuning on the HDRSDR-VQA dataset. Experimental results show that our models achieve state-of-the-art performance compared to existing FR and NR VQA models. Moreover, CompressedVQA-HDR-FR won first place in the FR track of the Generalizable HDR & SDR Video Quality Measurement Grand Challenge at IEEE ICME 2025. The code is available at https://github.com/sunwei925/CompressedVQA-HDR.
3DGS-IEval-15K: A Large-scale Image Quality Evaluation Database for 3D Gaussian-Splatting
Jun 17, 20253D Gaussian Splatting (3DGS) has emerged as a promising approach for novel view synthesis, offering real-time rendering with high visual fidelity. However, its substantial storage requirements present significant challenges for practical applications. While recent state-of-the-art (SOTA) 3DGS methods increasingly incorporate dedicated compression modules, there is a lack of a comprehensive framework to evaluate their perceptual impact. Therefore we present 3DGS-IEval-15K, the first large-scale image quality assessment (IQA) dataset specifically designed for compressed 3DGS representations. Our dataset encompasses 15,200 images rendered from 10 real-world scenes through 6 representative 3DGS algorithms at 20 strategically selected viewpoints, with different compression levels leading to various distortion effects. Through controlled subjective experiments, we collect human perception data from 60 viewers. We validate dataset quality through scene diversity and MOS distribution analysis, and establish a comprehensive benchmark with 30 representative IQA metrics covering diverse types. As the largest-scale 3DGS quality assessment dataset to date, our work provides a foundation for developing 3DGS specialized IQA metrics, and offers essential data for investigating view-dependent quality distribution patterns unique to 3DGS. The database is publicly available at https://github.com/YukeXing/3DGS-IEval-15K.
Scaling-up Perceptual Video Quality Assessment
May 28, 2025The data scaling law has been shown to significantly enhance the performance of large multi-modal models (LMMs) across various downstream tasks. However, in the domain of perceptual video quality assessment (VQA), the potential of scaling law remains unprecedented due to the scarcity of labeled resources and the insufficient scale of datasets. To address this, we propose \textbf{OmniVQA}, an efficient framework designed to efficiently build high-quality, human-in-the-loop VQA multi-modal instruction databases (MIDBs). We then scale up to create \textbf{OmniVQA-Chat-400K}, the largest MIDB in the VQA field concurrently. Our focus is on the technical and aesthetic quality dimensions, with abundant in-context instruction data to provide fine-grained VQA knowledge. Additionally, we have built the \textbf{OmniVQA-MOS-20K} dataset to enhance the model's quantitative quality rating capabilities. We then introduce a \textbf{complementary} training strategy that effectively leverages the knowledge from datasets for quality understanding and quality rating tasks. Furthermore, we propose the \textbf{OmniVQA-FG (fine-grain)-Benchmark} to evaluate the fine-grained performance of the models. Our results demonstrate that our models achieve state-of-the-art performance in both quality understanding and rating tasks.
TDVE-Assessor: Benchmarking and Evaluating the Quality of Text-Driven Video Editing with LMMs
May 26, 2025Text-driven video editing is rapidly advancing, yet its rigorous evaluation remains challenging due to the absence of dedicated video quality assessment (VQA) models capable of discerning the nuances of editing quality. To address this critical gap, we introduce TDVE-DB, a large-scale benchmark dataset for text-driven video editing. TDVE-DB consists of 3,857 edited videos generated from 12 diverse models across 8 editing categories, and is annotated with 173,565 human subjective ratings along three crucial dimensions, i.e., edited video quality, editing alignment, and structural consistency. Based on TDVE-DB, we first conduct a comprehensive evaluation for the 12 state-of-the-art editing models revealing the strengths and weaknesses of current video techniques, and then benchmark existing VQA methods in the context of text-driven video editing evaluation. Building on these insights, we propose TDVE-Assessor, a novel VQA model specifically designed for text-driven video editing assessment. TDVE-Assessor integrates both spatial and temporal video features into a large language model (LLM) for rich contextual understanding to provide comprehensive quality assessment. Extensive experiments demonstrate that TDVE-Assessor substantially outperforms existing VQA models on TDVE-DB across all three evaluation dimensions, setting a new state-of-the-art. Both TDVE-DB and TDVE-Assessor will be released upon the publication.
NTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.
Perceptual Quality Assessment for Embodied AI
May 22, 2025



Embodied AI has developed rapidly in recent years, but it is still mainly deployed in laboratories, with various distortions in the Real-world limiting its application. Traditionally, Image Quality Assessment (IQA) methods are applied to predict human preferences for distorted images; however, there is no IQA method to assess the usability of an image in embodied tasks, namely, the perceptual quality for robots. To provide accurate and reliable quality indicators for future embodied scenarios, we first propose the topic: IQA for Embodied AI. Specifically, we (1) based on the Mertonian system and meta-cognitive theory, constructed a perception-cognition-decision-execution pipeline and defined a comprehensive subjective score collection process; (2) established the Embodied-IQA database, containing over 36k reference/distorted image pairs, with more than 5m fine-grained annotations provided by Vision Language Models/Vision Language Action-models/Real-world robots; (3) trained and validated the performance of mainstream IQA methods on Embodied-IQA, demonstrating the need to develop more accurate quality indicators for Embodied AI. We sincerely hope that through evaluation, we can promote the application of Embodied AI under complex distortions in the Real-world. Project page: https://github.com/lcysyzxdxc/EmbodiedIQA
Exploring Image Quality Assessment from a New Perspective: Pupil Size
May 20, 2025This paper explores how the image quality assessment (IQA) task affects the cognitive processes of people from the perspective of pupil size and studies the relationship between pupil size and image quality. Specifically, we first invited subjects to participate in a subjective experiment, which includes two tasks: free observation and IQA. In the free observation task, subjects did not need to perform any action, and they only needed to observe images as they usually do with an album. In the IQA task, subjects were required to score images according to their overall impression of image quality. Then, by analyzing the difference in pupil size between the two tasks, we find that people may activate the visual attention mechanism when evaluating image quality. Meanwhile, we also find that the change in pupil size is closely related to image quality in the IQA task. For future research on IQA, this research can not only provide a theoretical basis for the objective IQA method and promote the development of more effective objective IQA methods, but also provide a new subjective IQA method for collecting the authentic subjective impression of image quality.