 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNebula-I: A General Framework for Collaboratively Training Deep Learning Models on Low-Bandwidth Cloud Clusters
May 19, 2022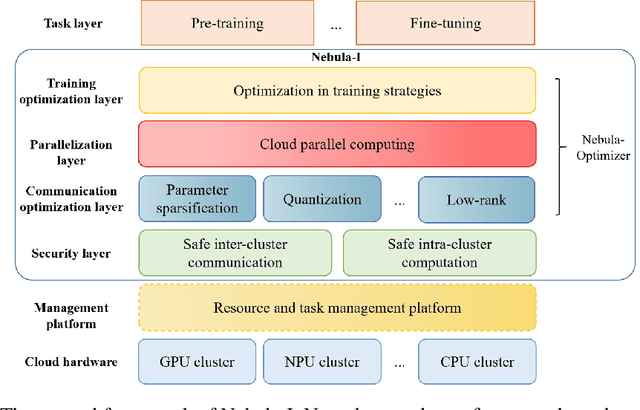
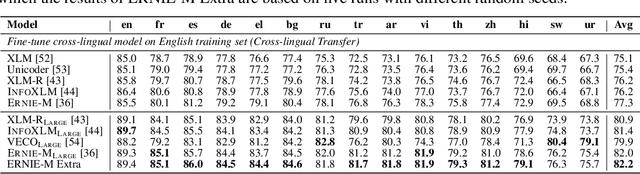
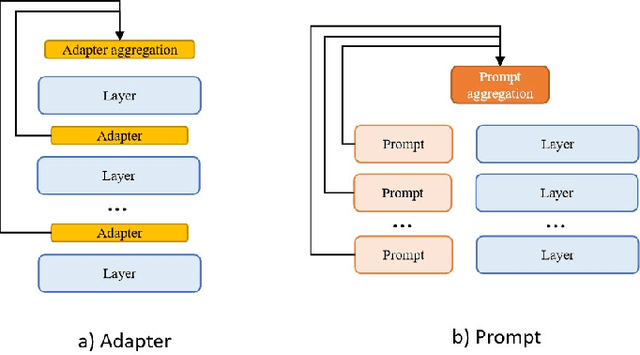
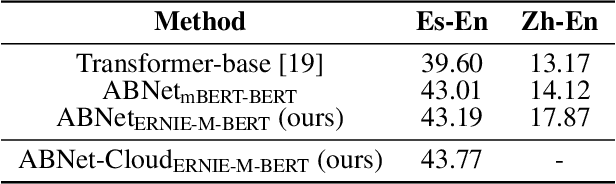
The ever-growing model size and scale of compute have attracted increasing interests in training deep learning models over multiple nodes. However, when it comes to training on cloud clusters, especially across remote clusters, huge challenges are faced. In this work, we introduce a general framework, Nebula-I, for collaboratively training deep learning models over remote heterogeneous clusters, the connections between which are low-bandwidth wide area networks (WANs). We took natural language processing (NLP) as an example to show how Nebula-I works in different training phases that include: a) pre-training a multilingual language model using two remote clusters; and b) fine-tuning a machine translation model using knowledge distilled from pre-trained models, which run through the most popular paradigm of recent deep learning. To balance the accuracy and communication efficiency, in Nebula-I, parameter-efficient training strategies, hybrid parallel computing methods and adaptive communication acceleration techniques are jointly applied. Meanwhile, security strategies are employed to guarantee the safety, reliability and privacy in intra-cluster computation and inter-cluster communication. Nebula-I is implemented with the PaddlePaddle deep learning framework, which can support collaborative training over heterogeneous hardware, e.g. GPU and NPU. Experiments demonstrate that the proposed framework could substantially maximize the training efficiency while preserving satisfactory NLP performance. By using Nebula-I, users can run large-scale training tasks over cloud clusters with minimum developments, and the utility of existed large pre-trained models could be further promoted. We also introduced new state-of-the-art results on cross-lingual natural language inference tasks, which are generated based upon a novel learning framework and Nebula-I.
Deep Geometry Post-Processing for Decompressed Point Clouds
Apr 29, 2022
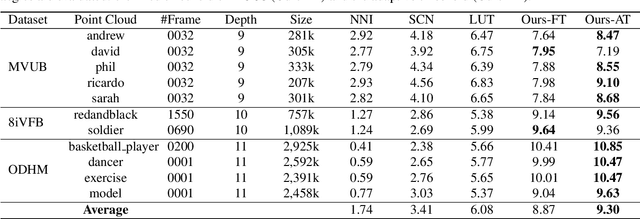
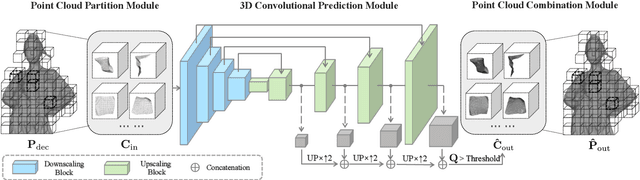

Point cloud compression plays a crucial role in reducing the huge cost of data storage and transmission. However, distortions can be introduced into the decompressed point clouds due to quantization. In this paper, we propose a novel learning-based post-processing method to enhance the decompressed point clouds. Specifically, a voxelized point cloud is first divided into small cubes. Then, a 3D convolutional network is proposed to predict the occupancy probability for each location of a cube. We leverage both local and global contexts by generating multi-scale probabilities. These probabilities are progressively summed to predict the results in a coarse-to-fine manner. Finally, we obtain the geometry-refined point clouds based on the predicted probabilities. Different from previous methods, we deal with decompressed point clouds with huge variety of distortions using a single model. Experimental results show that the proposed method can significantly improve the quality of the decompressed point clouds, achieving 9.30dB BDPSNR gain on three representative datasets on average.
Self-Supervised Arbitrary-Scale Point Clouds Upsampling via Implicit Neural Representation
Apr 18, 2022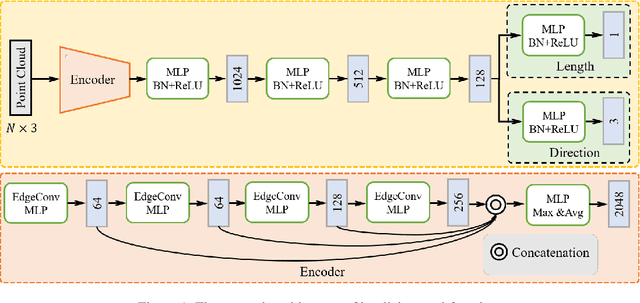
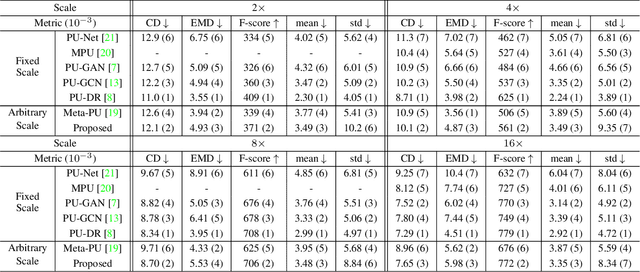
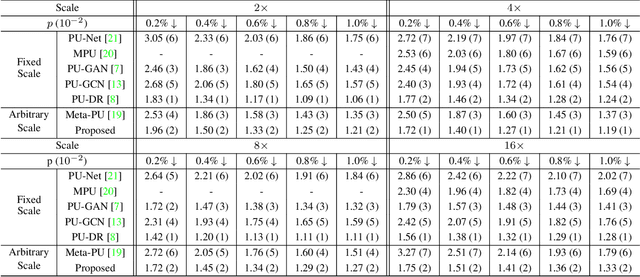
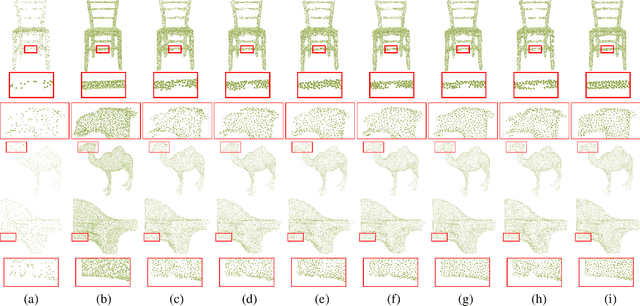
Point clouds upsampling is a challenging issue to generate dense and uniform point clouds from the given sparse input. Most existing methods either take the end-to-end supervised learning based manner, where large amounts of pairs of sparse input and dense ground-truth are exploited as supervision information; or treat up-scaling of different scale factors as independent tasks, and have to build multiple networks to handle upsampling with varying factors. In this paper, we propose a novel approach that achieves self-supervised and magnification-flexible point clouds upsampling simultaneously. We formulate point clouds upsampling as the task of seeking nearest projection points on the implicit surface for seed points. To this end, we define two implicit neural functions to estimate projection direction and distance respectively, which can be trained by two pretext learning tasks. Experimental results demonstrate that our self-supervised learning based scheme achieves competitive or even better performance than supervised learning based state-of-the-art methods. The source code is publicly available at https://github.com/xnowbzhao/sapcu.
Neural Texture Extraction and Distribution for Controllable Person Image Synthesis
Apr 13, 2022

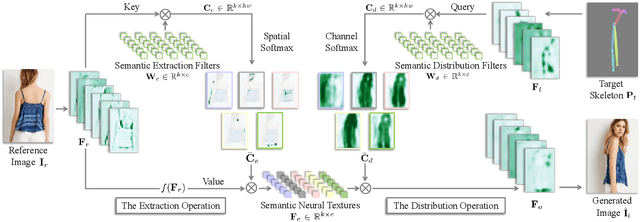
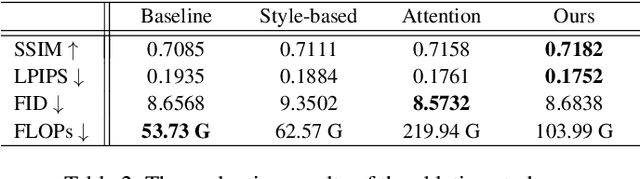
We deal with the controllable person image synthesis task which aims to re-render a human from a reference image with explicit control over body pose and appearance. Observing that person images are highly structured, we propose to generate desired images by extracting and distributing semantic entities of reference images. To achieve this goal, a neural texture extraction and distribution operation based on double attention is described. This operation first extracts semantic neural textures from reference feature maps. Then, it distributes the extracted neural textures according to the spatial distributions learned from target poses. Our model is trained to predict human images in arbitrary poses, which encourages it to extract disentangled and expressive neural textures representing the appearance of different semantic entities. The disentangled representation further enables explicit appearance control. Neural textures of different reference images can be fused to control the appearance of the interested areas. Experimental comparisons show the superiority of the proposed model. Code is available at https://github.com/RenYurui/Neural-Texture-Extraction-Distribution.
OctAttention: Octree-based Large-scale Contexts Model for Point Cloud Compression
Feb 12, 2022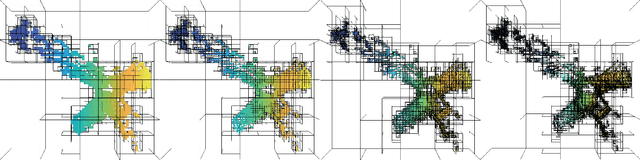
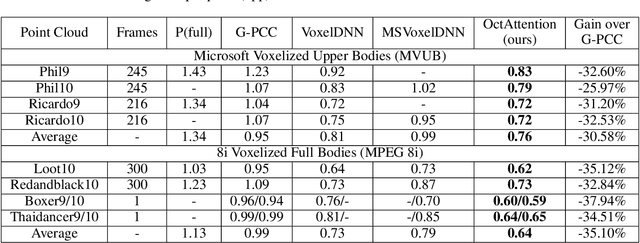
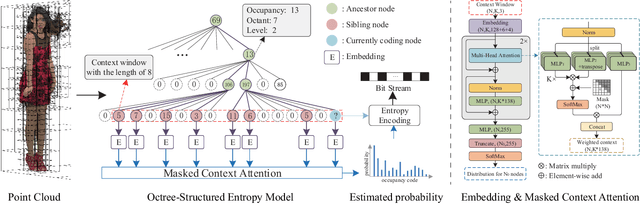
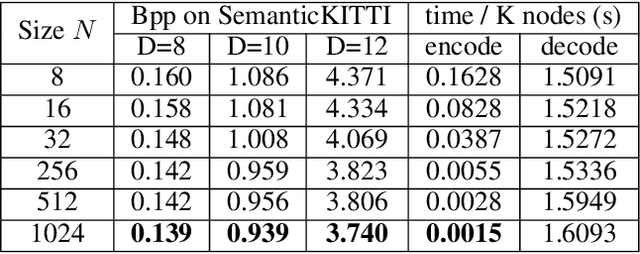
In point cloud compression, sufficient contexts are significant for modeling the point cloud distribution. However, the contexts gathered by the previous voxel-based methods decrease when handling sparse point clouds. To address this problem, we propose a multiple-contexts deep learning framework called OctAttention employing the octree structure, a memory-efficient representation for point clouds. Our approach encodes octree symbol sequences in a lossless way by gathering the information of sibling and ancestor nodes. Expressly, we first represent point clouds with octree to reduce spatial redundancy, which is robust for point clouds with different resolutions. We then design a conditional entropy model with a large receptive field that models the sibling and ancestor contexts to exploit the strong dependency among the neighboring nodes and employ an attention mechanism to emphasize the correlated nodes in the context. Furthermore, we introduce a mask operation during training and testing to make a trade-off between encoding time and performance. Compared to the previous state-of-the-art works, our approach obtains a 10%-35% BD-Rate gain on the LiDAR benchmark (e.g. SemanticKITTI) and object point cloud dataset (e.g. MPEG 8i, MVUB), and saves 95% coding time compared to the voxel-based baseline. The code is available at https://github.com/zb12138/OctAttention.
Multi-direction and Multi-scale Pyramid in Transformer for Video-based Pedestrian Retrieval
Feb 12, 2022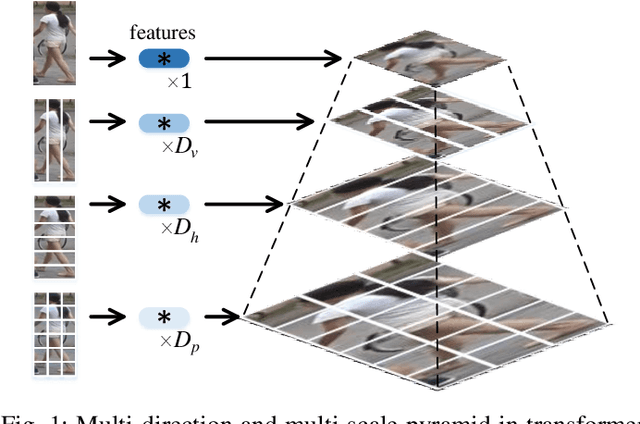
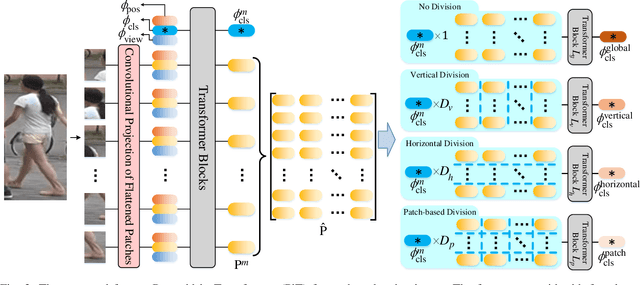
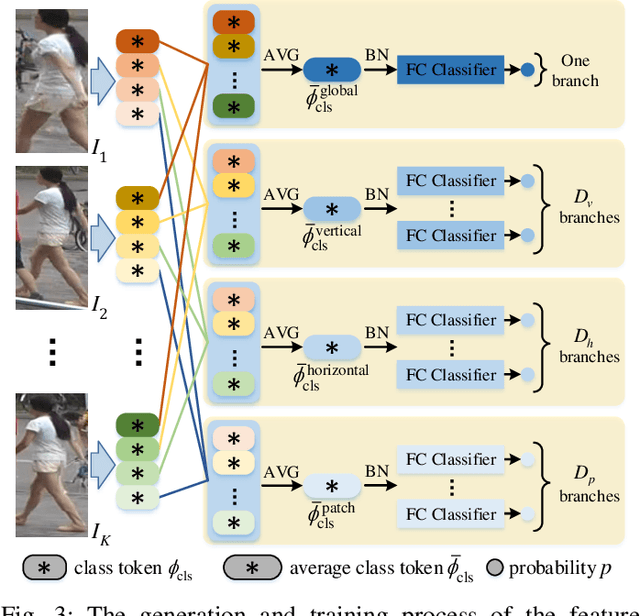
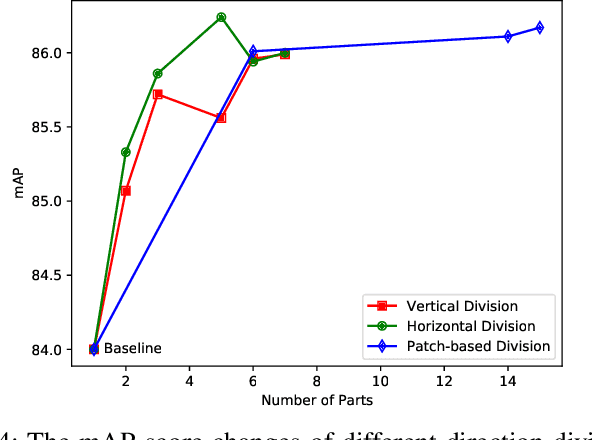
In video surveillance, pedestrian retrieval (also called person re-identification) is a critical task. This task aims to retrieve the pedestrian of interest from non-overlapping cameras. Recently, transformer-based models have achieved significant progress for this task. However, these models still suffer from ignoring fine-grained, part-informed information. This paper proposes a multi-direction and multi-scale Pyramid in Transformer (PiT) to solve this problem. In transformer-based architecture, each pedestrian image is split into many patches. Then, these patches are fed to transformer layers to obtain the feature representation of this image. To explore the fine-grained information, this paper proposes to apply vertical division and horizontal division on these patches to generate different-direction human parts. These parts provide more fine-grained information. To fuse multi-scale feature representation, this paper presents a pyramid structure containing global-level information and many pieces of local-level information from different scales. The feature pyramids of all the pedestrian images from the same video are fused to form the final multi-direction and multi-scale feature representation. Experimental results on two challenging video-based benchmarks, MARS and iLIDS-VID, show the proposed PiT achieves state-of-the-art performance. Extensive ablation studies demonstrate the superiority of the proposed pyramid structure. The code is available at https://git.openi.org.cn/zangxh/PiT.git.
Two heads are better than one: Enhancing medical representations by pre-training over structured and unstructured electronic health records
Jan 25, 2022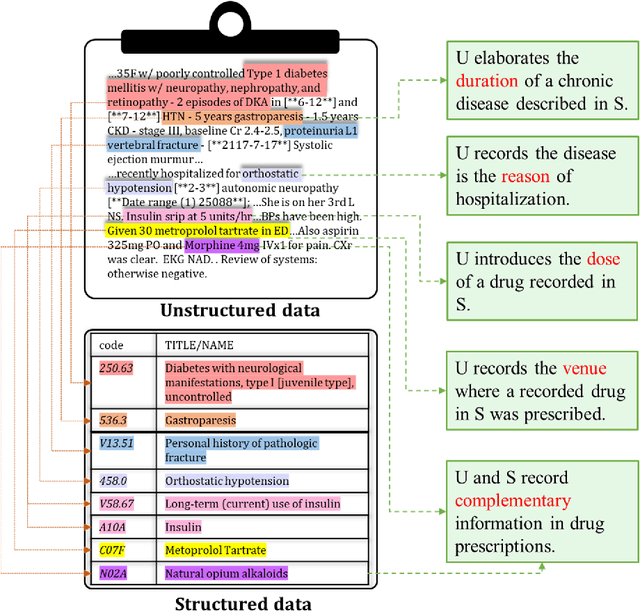
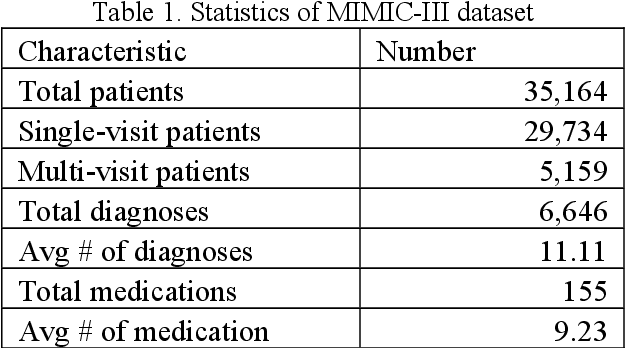
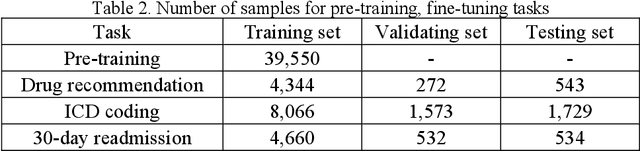
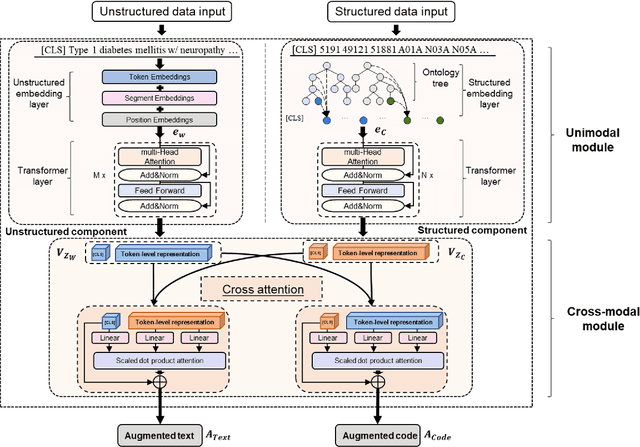
The massive context of electronic health records (EHRs) has created enormous potentials for improving healthcare, among which structured (coded) data and unstructured (text) data are two important textual modalities. They do not exist in isolation and can complement each other in most real-life clinical scenarios. Most existing researches in medical informatics, however, either only focus on a particular modality or straightforwardly concatenate the information from different modalities, which ignore the interaction and information sharing between them. To address these issues, we proposed a unified deep learning-based medical pre-trained language model, named UMM-PLM, to automatically learn representative features from multimodal EHRs that consist of both structured data and unstructured data. Specifically, we first developed parallel unimodal information representation modules to capture the unimodal-specific characteristic, where unimodal representations were learned from each data source separately. A cross-modal module was further introduced to model the interactions between different modalities. We pre-trained the model on a large EHRs dataset containing both structured data and unstructured data and verified the effectiveness of the model on three downstream clinical tasks, i.e., medication recommendation, 30-day readmission and ICD coding through extensive experiments. The results demonstrate the power of UMM-PLM compared with benchmark methods and state-of-the-art baselines. Analyses show that UMM-PLM can effectively concern with multimodal textual information and has the potential to provide more comprehensive interpretations for clinical decision making.
Winning solutions and post-challenge analyses of the ChaLearn AutoDL challenge 2019
Jan 11, 2022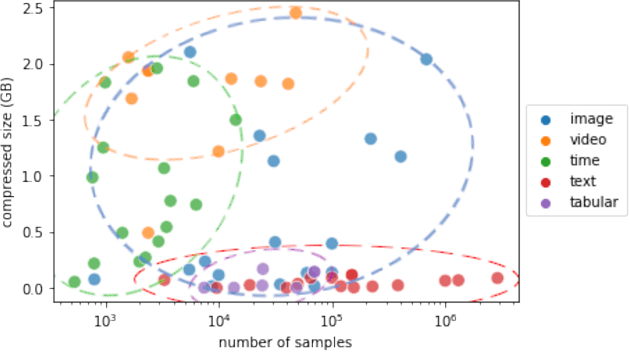
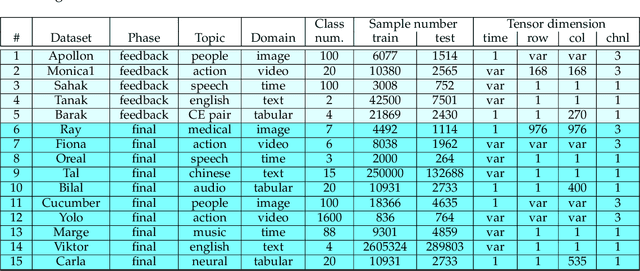
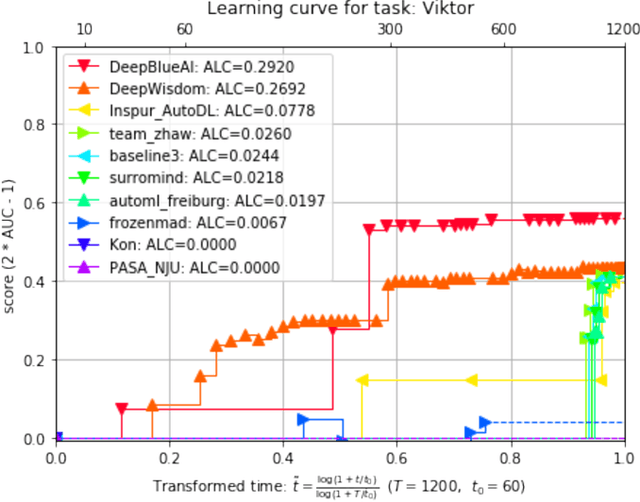
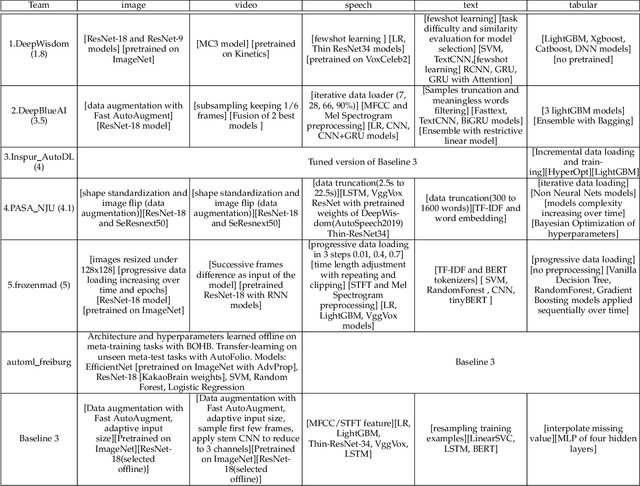
This paper reports the results and post-challenge analyses of ChaLearn's AutoDL challenge series, which helped sorting out a profusion of AutoML solutions for Deep Learning (DL) that had been introduced in a variety of settings, but lacked fair comparisons. All input data modalities (time series, images, videos, text, tabular) were formatted as tensors and all tasks were multi-label classification problems. Code submissions were executed on hidden tasks, with limited time and computational resources, pushing solutions that get results quickly. In this setting, DL methods dominated, though popular Neural Architecture Search (NAS) was impractical. Solutions relied on fine-tuned pre-trained networks, with architectures matching data modality. Post-challenge tests did not reveal improvements beyond the imposed time limit. While no component is particularly original or novel, a high level modular organization emerged featuring a "meta-learner", "data ingestor", "model selector", "model/learner", and "evaluator". This modularity enabled ablation studies, which revealed the importance of (off-platform) meta-learning, ensembling, and efficient data management. Experiments on heterogeneous module combinations further confirm the (local) optimality of the winning solutions. Our challenge legacy includes an ever-lasting benchmark (http://autodl.chalearn.org), the open-sourced code of the winners, and a free "AutoDL self-service".
* The first three authors contributed equally; This is only a draft version
Specializing Versatile Skill Libraries using Local Mixture of Experts
Jan 10, 2022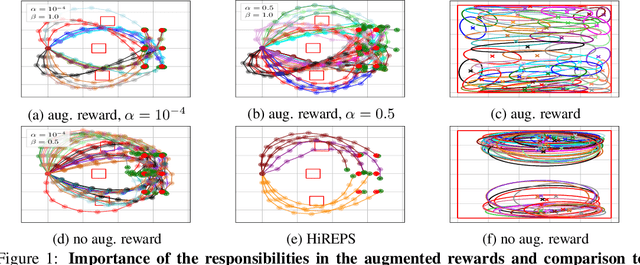
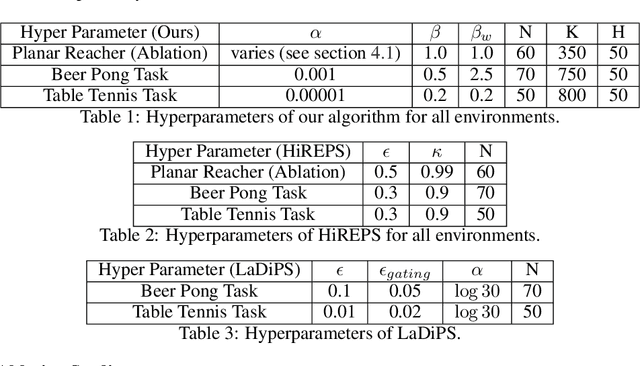
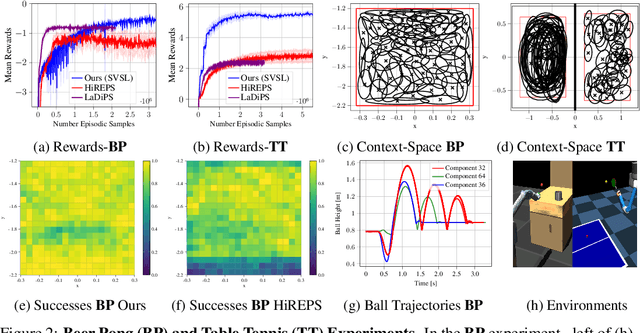

A long-cherished vision in robotics is to equip robots with skills that match the versatility and precision of humans. For example, when playing table tennis, a robot should be capable of returning the ball in various ways while precisely placing it at the desired location. A common approach to model such versatile behavior is to use a Mixture of Experts (MoE) model, where each expert is a contextual motion primitive. However, learning such MoEs is challenging as most objectives force the model to cover the entire context space, which prevents specialization of the primitives resulting in rather low-quality components. Starting from maximum entropy reinforcement learning (RL), we decompose the objective into optimizing an individual lower bound per mixture component. Further, we introduce a curriculum by allowing the components to focus on a local context region, enabling the model to learn highly accurate skill representations. To this end, we use local context distributions that are adapted jointly with the expert primitives. Our lower bound advocates an iterative addition of new components, where new components will concentrate on local context regions not covered by the current MoE. This local and incremental learning results in a modular MoE model of high accuracy and versatility, where both properties can be scaled by adding more components on the fly. We demonstrate this by an extensive ablation and on two challenging simulated robot skill learning tasks. We compare our achieved performance to LaDiPS and HiREPS, a known hierarchical policy search method for learning diverse skills.
ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
Dec 23, 2021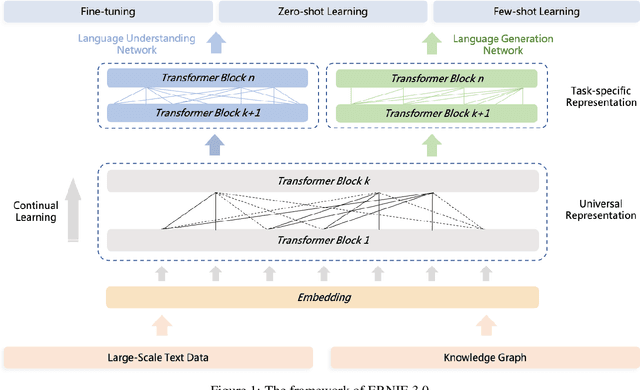
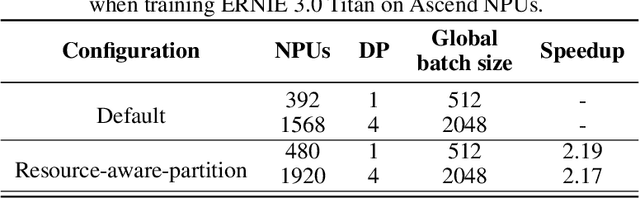
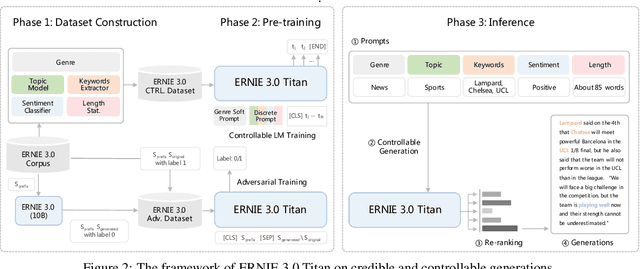
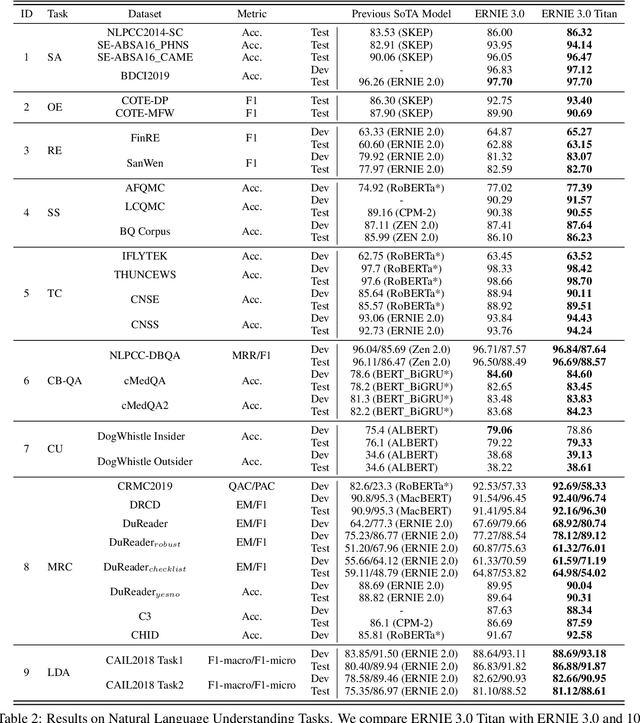
Pre-trained language models have achieved state-of-the-art results in various Natural Language Processing (NLP) tasks. GPT-3 has shown that scaling up pre-trained language models can further exploit their enormous potential. A unified framework named ERNIE 3.0 was recently proposed for pre-training large-scale knowledge enhanced models and trained a model with 10 billion parameters. ERNIE 3.0 outperformed the state-of-the-art models on various NLP tasks. In order to explore the performance of scaling up ERNIE 3.0, we train a hundred-billion-parameter model called ERNIE 3.0 Titan with up to 260 billion parameters on the PaddlePaddle platform. Furthermore, we design a self-supervised adversarial loss and a controllable language modeling loss to make ERNIE 3.0 Titan generate credible and controllable texts. To reduce the computation overhead and carbon emission, we propose an online distillation framework for ERNIE 3.0 Titan, where the teacher model will teach students and train itself simultaneously. ERNIE 3.0 Titan is the largest Chinese dense pre-trained model so far. Empirical results show that the ERNIE 3.0 Titan outperforms the state-of-the-art models on 68 NLP datasets.