 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAVOR-Bench: A Comprehensive Benchmark for Fine-Grained Video Motion Understanding
Mar 19, 2025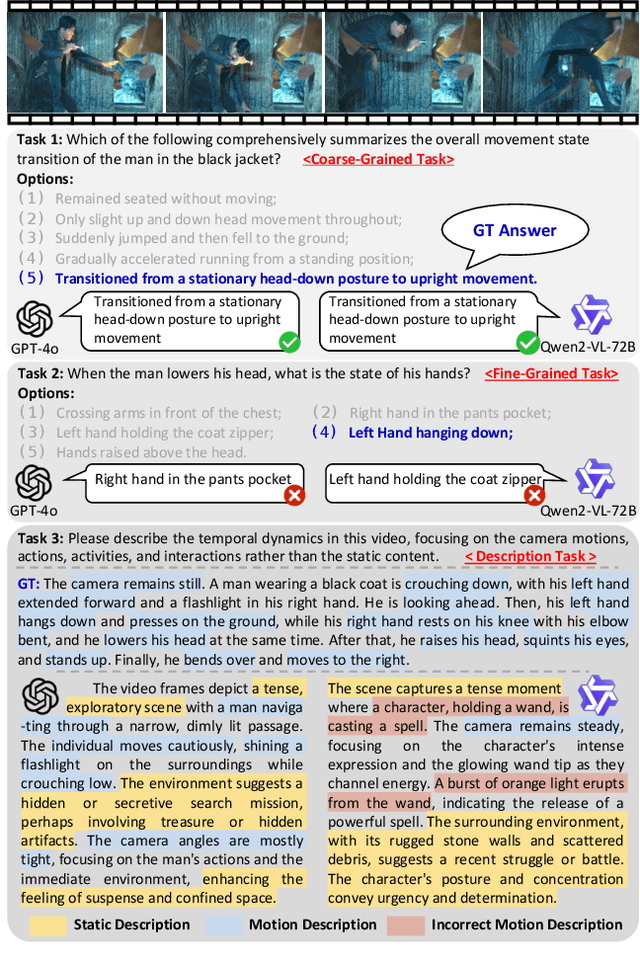

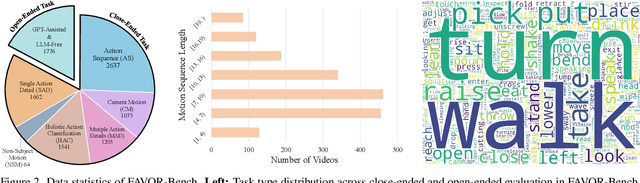
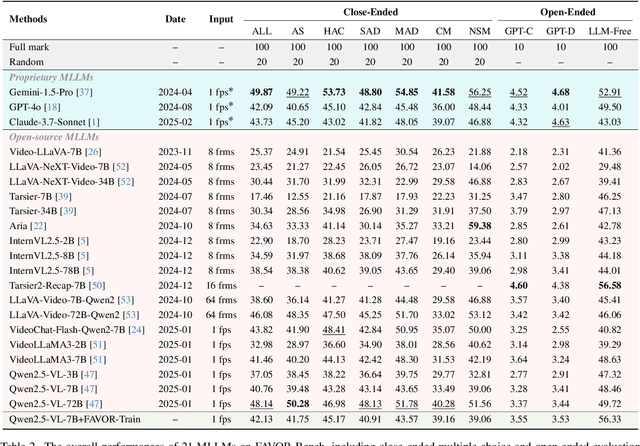
Multimodal Large Language Models (MLLMs) have shown remarkable capabilities in video content understanding but still struggle with fine-grained motion comprehension. To comprehensively assess the motion understanding ability of existing MLLMs, we introduce FAVOR-Bench, comprising 1,776 videos with structured manual annotations of various motions. Our benchmark includes both close-ended and open-ended tasks. For close-ended evaluation, we carefully design 8,184 multiple-choice question-answer pairs spanning six distinct sub-tasks. For open-ended evaluation, we develop both a novel cost-efficient LLM-free and a GPT-assisted caption assessment method, where the former can enhance benchmarking interpretability and reproducibility. Comprehensive experiments with 21 state-of-the-art MLLMs reveal significant limitations in their ability to comprehend and describe detailed temporal dynamics in video motions. To alleviate this limitation, we further build FAVOR-Train, a dataset consisting of 17,152 videos with fine-grained motion annotations. The results of finetuning Qwen2.5-VL on FAVOR-Train yield consistent improvements on motion-related tasks of TVBench, MotionBench and our FAVOR-Bench. Comprehensive assessment results demonstrate that the proposed FAVOR-Bench and FAVOR-Train provide valuable tools to the community for developing more powerful video understanding models. Project page: \href{https://favor-bench.github.io/}{https://favor-bench.github.io/}.
Step-Video-TI2V Technical Report: A State-of-the-Art Text-Driven Image-to-Video Generation Model
Mar 14, 2025We present Step-Video-TI2V, a state-of-the-art text-driven image-to-video generation model with 30B parameters, capable of generating videos up to 102 frames based on both text and image inputs. We build Step-Video-TI2V-Eval as a new benchmark for the text-driven image-to-video task and compare Step-Video-TI2V with open-source and commercial TI2V engines using this dataset. Experimental results demonstrate the state-of-the-art performance of Step-Video-TI2V in the image-to-video generation task. Both Step-Video-TI2V and Step-Video-TI2V-Eval are available at https://github.com/stepfun-ai/Step-Video-TI2V.
Attention Reallocation: Towards Zero-cost and Controllable Hallucination Mitigation of MLLMs
Mar 12, 2025Multi-Modal Large Language Models (MLLMs) stand out in various tasks but still struggle with hallucinations. While recent training-free mitigation methods mostly introduce additional inference overhead via retrospection strategy and contrastive decoding, we propose attention reallocation (AttnReal) to mitigate hallucinations with nearly zero extra cost. Our approach is motivated by the key observations that, MLLM's unreasonable attention distribution causes features to be dominated by historical output tokens, which further contributes to hallucinated responses because of the distribution gap between different token types. Based on the observations, AttnReal recycles excessive attention from output tokens and reallocates it to visual tokens, which reduces MLLM's reliance on language priors and ensures the decoding process depends more on the visual inputs. More interestingly, we find that, by controlling the intensity of AttnReal, we can achieve a wide-range trade-off between the response faithfulness and overall performance. Comprehensive results from different benchmarks validate the effectiveness of AttnReal across six open-source MLLMs and three decoding strategies.
DeRS: Towards Extremely Efficient Upcycled Mixture-of-Experts Models
Mar 03, 2025



Upcycled Mixture-of-Experts (MoE) models have shown great potential in various tasks by converting the original Feed-Forward Network (FFN) layers in pre-trained dense models into MoE layers. However, these models still suffer from significant parameter inefficiency due to the introduction of multiple experts. In this work, we propose a novel DeRS (Decompose, Replace, and Synthesis) paradigm to overcome this shortcoming, which is motivated by our observations about the unique redundancy mechanisms of upcycled MoE experts. Specifically, DeRS decomposes the experts into one expert-shared base weight and multiple expert-specific delta weights, and subsequently represents these delta weights in lightweight forms. Our proposed DeRS paradigm can be applied to enhance parameter efficiency in two different scenarios, including: 1) DeRS Compression for inference stage, using sparsification or quantization to compress vanilla upcycled MoE models; and 2) DeRS Upcycling for training stage, employing lightweight sparse or low-rank matrixes to efficiently upcycle dense models into MoE models. Extensive experiments across three different tasks show that the proposed methods can achieve extreme parameter efficiency while maintaining the performance for both training and compression of upcycled MoE models.
MotionAgent: Fine-grained Controllable Video Generation via Motion Field Agent
Feb 05, 2025



We propose MotionAgent, enabling fine-grained motion control for text-guided image-to-video generation. The key technique is the motion field agent that converts motion information in text prompts into explicit motion fields, providing flexible and precise motion guidance. Specifically, the agent extracts the object movement and camera motion described in the text and converts them into object trajectories and camera extrinsics, respectively. An analytical optical flow composition module integrates these motion representations in 3D space and projects them into a unified optical flow. An optical flow adapter takes the flow to control the base image-to-video diffusion model for generating fine-grained controlled videos. The significant improvement in the Video-Text Camera Motion metrics on VBench indicates that our method achieves precise control over camera motion. We construct a subset of VBench to evaluate the alignment of motion information in the text and the generated video, outperforming other advanced models on motion generation accuracy.
MikuDance: Animating Character Art with Mixed Motion Dynamics
Nov 14, 2024



We propose MikuDance, a diffusion-based pipeline incorporating mixed motion dynamics to animate stylized character art. MikuDance consists of two key techniques: Mixed Motion Modeling and Mixed-Control Diffusion, to address the challenges of high-dynamic motion and reference-guidance misalignment in character art animation. Specifically, a Scene Motion Tracking strategy is presented to explicitly model the dynamic camera in pixel-wise space, enabling unified character-scene motion modeling. Building on this, the Mixed-Control Diffusion implicitly aligns the scale and body shape of diverse characters with motion guidance, allowing flexible control of local character motion. Subsequently, a Motion-Adaptive Normalization module is incorporated to effectively inject global scene motion, paving the way for comprehensive character art animation. Through extensive experiments, we demonstrate the effectiveness and generalizability of MikuDance across various character art and motion guidance, consistently producing high-quality animations with remarkable motion dynamics.
MVPaint: Synchronized Multi-View Diffusion for Painting Anything 3D
Nov 04, 2024



Texturing is a crucial step in the 3D asset production workflow, which enhances the visual appeal and diversity of 3D assets. Despite recent advancements in Text-to-Texture (T2T) generation, existing methods often yield subpar results, primarily due to local discontinuities, inconsistencies across multiple views, and their heavy dependence on UV unwrapping outcomes. To tackle these challenges, we propose a novel generation-refinement 3D texturing framework called MVPaint, which can generate high-resolution, seamless textures while emphasizing multi-view consistency. MVPaint mainly consists of three key modules. 1) Synchronized Multi-view Generation (SMG). Given a 3D mesh model, MVPaint first simultaneously generates multi-view images by employing an SMG model, which leads to coarse texturing results with unpainted parts due to missing observations. 2) Spatial-aware 3D Inpainting (S3I). To ensure complete 3D texturing, we introduce the S3I method, specifically designed to effectively texture previously unobserved areas. 3) UV Refinement (UVR). Furthermore, MVPaint employs a UVR module to improve the texture quality in the UV space, which first performs a UV-space Super-Resolution, followed by a Spatial-aware Seam-Smoothing algorithm for revising spatial texturing discontinuities caused by UV unwrapping. Moreover, we establish two T2T evaluation benchmarks: the Objaverse T2T benchmark and the GSO T2T benchmark, based on selected high-quality 3D meshes from the Objaverse dataset and the entire GSO dataset, respectively. Extensive experimental results demonstrate that MVPaint surpasses existing state-of-the-art methods. Notably, MVPaint could generate high-fidelity textures with minimal Janus issues and highly enhanced cross-view consistency.
Polyp-E: Benchmarking the Robustness of Deep Segmentation Models via Polyp Editing
Oct 22, 2024



Automatic polyp segmentation is helpful to assist clinical diagnosis and treatment. In daily clinical practice, clinicians exhibit robustness in identifying polyps with both location and size variations. It is uncertain if deep segmentation models can achieve comparable robustness in automated colonoscopic analysis. To benchmark the model robustness, we focus on evaluating the robustness of segmentation models on the polyps with various attributes (e.g. location and size) and healthy samples. Based on the Latent Diffusion Model, we perform attribute editing on real polyps and build a new dataset named Polyp-E. Our synthetic dataset boasts exceptional realism, to the extent that clinical experts find it challenging to discern them from real data. We evaluate several existing polyp segmentation models on the proposed benchmark. The results reveal most of the models are highly sensitive to attribute variations. As a novel data augmentation technique, the proposed editing pipeline can improve both in-distribution and out-of-distribution generalization ability. The code and datasets will be released.
Scene123: One Prompt to 3D Scene Generation via Video-Assisted and Consistency-Enhanced MAE
Aug 10, 2024



As Artificial Intelligence Generated Content (AIGC) advances, a variety of methods have been developed to generate text, images, videos, and 3D objects from single or multimodal inputs, contributing efforts to emulate human-like cognitive content creation. However, generating realistic large-scale scenes from a single input presents a challenge due to the complexities involved in ensuring consistency across extrapolated views generated by models. Benefiting from recent video generation models and implicit neural representations, we propose Scene123, a 3D scene generation model, that not only ensures realism and diversity through the video generation framework but also uses implicit neural fields combined with Masked Autoencoders (MAE) to effectively ensures the consistency of unseen areas across views. Specifically, we initially warp the input image (or an image generated from text) to simulate adjacent views, filling the invisible areas with the MAE model. However, these filled images usually fail to maintain view consistency, thus we utilize the produced views to optimize a neural radiance field, enhancing geometric consistency. Moreover, to further enhance the details and texture fidelity of generated views, we employ a GAN-based Loss against images derived from the input image through the video generation model. Extensive experiments demonstrate that our method can generate realistic and consistent scenes from a single prompt. Both qualitative and quantitative results indicate that our approach surpasses existing state-of-the-art methods. We show encourage video examples at https://yiyingyang12.github.io/Scene123.github.io/.
Lightweight Model Pre-training via Language Guided Knowledge Distillation
Jun 17, 2024



This paper studies the problem of pre-training for small models, which is essential for many mobile devices. Current state-of-the-art methods on this problem transfer the representational knowledge of a large network (as a Teacher) into a smaller model (as a Student) using self-supervised distillation, improving the performance of the small model on downstream tasks. However, existing approaches are insufficient in extracting the crucial knowledge that is useful for discerning categories in downstream tasks during the distillation process. In this paper, for the first time, we introduce language guidance to the distillation process and propose a new method named Language-Guided Distillation (LGD) system, which uses category names of the target downstream task to help refine the knowledge transferred between the teacher and student. To this end, we utilize a pre-trained text encoder to extract semantic embeddings from language and construct a textual semantic space called Textual Semantics Bank (TSB). Furthermore, we design a Language-Guided Knowledge Aggregation (LGKA) module to construct the visual semantic space, also named Visual Semantics Bank (VSB). The task-related knowledge is transferred by driving a student encoder to mimic the similarity score distribution inferred by a teacher over TSB and VSB. Compared with other small models obtained by either ImageNet pre-training or self-supervised distillation, experiment results show that the distilled lightweight model using the proposed LGD method presents state-of-the-art performance and is validated on various downstream tasks, including classification, detection, and segmentation. We have made the code available at https://github.com/mZhenz/LGD.