 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Transceiver Design for Aerial Image Transmission and Large-scale Scene Reconstruction
Apr 13, 2026Large-scale three-dimensional (3D) scene reconstruction in low-altitude intelligent networks (LAIN) demands highly efficient wireless image transmission. However, existing schemes struggle to balance severe pilot overhead with the transmission accuracy required to maintain reconstruction fidelity. To strike a balance between efficiency and reliability, this paper proposes a novel deep learning-based end-to-end (E2E) transceiver design that integrates 3D Gaussian Splatting (3DGS) directly into the training process. By jointly optimizing the communication modules via the combined 3DGS rendering loss, our approach explicitly improves scene recovery quality. Furthermore, this task-driven framework enables the use of a sparse pilot scheme, significantly reducing transmission overhead while maintaining robust image recovery under low-altitude channel conditions. Extensive experiments on real-world aerial image datasets demonstrate that the proposed E2E design significantly outperforms existing baselines, delivering superior transmission performance and accurate 3D scene reconstructions.
ReMemNav: A Rethinking and Memory-Augmented Framework for Zero-Shot Object Navigation
Mar 25, 2026Zero-shot object navigation requires agents to locate unseen target objects in unfamiliar environments without prior maps or task-specific training which remains a significant challenge. Although recent advancements in vision-language models(VLMs) provide promising commonsense reasoning capabilities for this task, these models still suffer from spatial hallucinations, local exploration deadlocks, and a disconnect between high-level semantic intent and low-level control. In this regard, we propose a novel hierarchical navigation framework named ReMemNav, which seamlessly integrates panoramic semantic priors and episodic memory with VLMs. We introduce the Recognize Anything Model to anchor the spatial reasoning process of the VLM. We also design an adaptive dual-modal rethinking mechanism based on an episodic semantic buffer queue. The proposed mechanism actively verifies target visibility and corrects decisions using historical memory to prevent deadlocks. For low-level action execution, ReMemNav extracts a sequence of feasible actions using depth masks, allowing the VLM to select the optimal action for mapping into actual spatial movement. Extensive evaluations on HM3D and MP3D demonstrate that ReMemNav outperforms existing training-free zero-shot baselines in both success rate and exploration efficiency. Specifically, we achieve significant absolute performance improvements, with SR and SPL increasing by 1.7% and 7.0% on HM3D v0.1, 18.2% and 11.1% on HM3D v0.2, and 8.7% and 7.9% on MP3D.
HPTune: Hierarchical Proactive Tuning for Collision-Free Model Predictive Control
Jan 29, 2026Parameter tuning is a powerful approach to enhance adaptability in model predictive control (MPC) motion planners. However, existing methods typically operate in a myopic fashion that only evaluates executed actions, leading to inefficient parameter updates due to the sparsity of failure events (e.g., obstacle nearness or collision). To cope with this issue, we propose to extend evaluation from executed to non-executed actions, yielding a hierarchical proactive tuning (HPTune) framework that combines both a fast-level tuning and a slow-level tuning. The fast one adopts risk indicators of predictive closing speed and predictive proximity distance, and the slow one leverages an extended evaluation loss for closed-loop backpropagation. Additionally, we integrate HPTune with the Doppler LiDAR that provides obstacle velocities apart from position-only measurements for enhanced motion predictions, thus facilitating the implementation of HPTune. Extensive experiments on high-fidelity simulator demonstrate that HPTune achieves efficient MPC tuning and outperforms various baseline schemes in complex environments. It is found that HPTune enables situation-tailored motion planning by formulating a safe, agile collision avoidance strategy.
NTK-Guided Implicit Neural Teaching
Nov 19, 2025



Implicit Neural Representations (INRs) parameterize continuous signals via multilayer perceptrons (MLPs), enabling compact, resolution-independent modeling for tasks like image, audio, and 3D reconstruction. However, fitting high-resolution signals demands optimizing over millions of coordinates, incurring prohibitive computational costs. To address it, we propose NTK-Guided Implicit Neural Teaching (NINT), which accelerates training by dynamically selecting coordinates that maximize global functional updates. Leveraging the Neural Tangent Kernel (NTK), NINT scores examples by the norm of their NTK-augmented loss gradients, capturing both fitting errors and heterogeneous leverage (self-influence and cross-coordinate coupling). This dual consideration enables faster convergence compared to existing methods. Through extensive experiments, we demonstrate that NINT significantly reduces training time by nearly half while maintaining or improving representation quality, establishing state-of-the-art acceleration among recent sampling-based strategies.
DreamDance: Animating Character Art via Inpainting Stable Gaussian Worlds
May 30, 2025



This paper presents DreamDance, a novel character art animation framework capable of producing stable, consistent character and scene motion conditioned on precise camera trajectories. To achieve this, we re-formulate the animation task as two inpainting-based steps: Camera-aware Scene Inpainting and Pose-aware Video Inpainting. The first step leverages a pre-trained image inpainting model to generate multi-view scene images from the reference art and optimizes a stable large-scale Gaussian field, which enables coarse background video rendering with camera trajectories. However, the rendered video is rough and only conveys scene motion. To resolve this, the second step trains a pose-aware video inpainting model that injects the dynamic character into the scene video while enhancing background quality. Specifically, this model is a DiT-based video generation model with a gating strategy that adaptively integrates the character's appearance and pose information into the base background video. Through extensive experiments, we demonstrate the effectiveness and generalizability of DreamDance, producing high-quality and consistent character animations with remarkable camera dynamics.
MikuDance: Animating Character Art with Mixed Motion Dynamics
Nov 14, 2024



We propose MikuDance, a diffusion-based pipeline incorporating mixed motion dynamics to animate stylized character art. MikuDance consists of two key techniques: Mixed Motion Modeling and Mixed-Control Diffusion, to address the challenges of high-dynamic motion and reference-guidance misalignment in character art animation. Specifically, a Scene Motion Tracking strategy is presented to explicitly model the dynamic camera in pixel-wise space, enabling unified character-scene motion modeling. Building on this, the Mixed-Control Diffusion implicitly aligns the scale and body shape of diverse characters with motion guidance, allowing flexible control of local character motion. Subsequently, a Motion-Adaptive Normalization module is incorporated to effectively inject global scene motion, paving the way for comprehensive character art animation. Through extensive experiments, we demonstrate the effectiveness and generalizability of MikuDance across various character art and motion guidance, consistently producing high-quality animations with remarkable motion dynamics.
Building a great multi-lingual teacher with sparsely-gated mixture of experts for speech recognition
Jan 04, 2022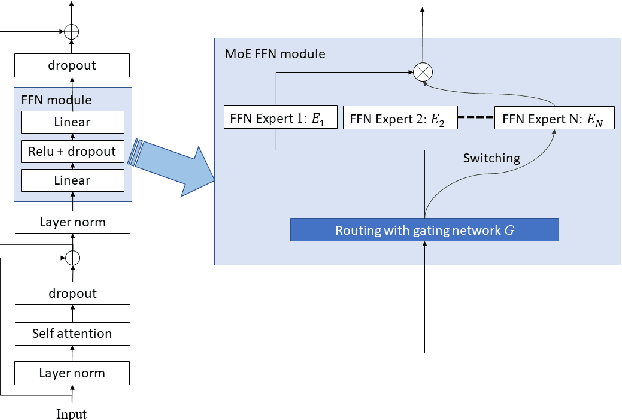
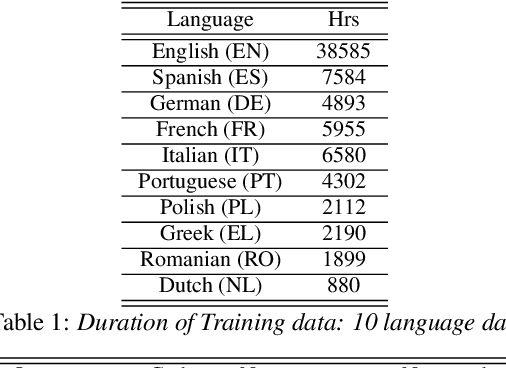
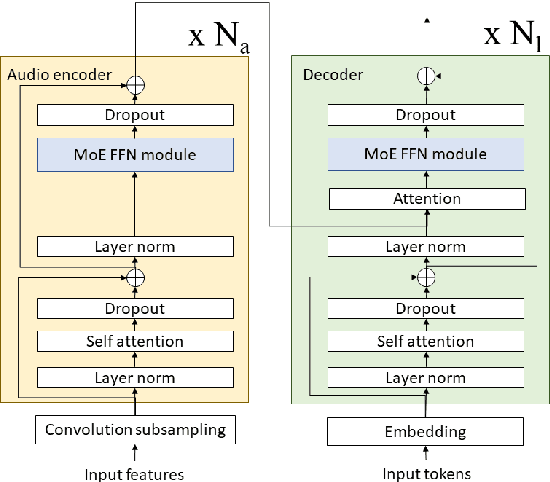
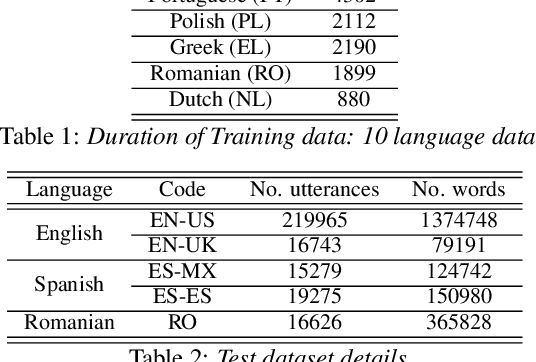
The sparsely-gated Mixture of Experts (MoE) can magnify a network capacity with a little computational complexity. In this work, we investigate how multi-lingual Automatic Speech Recognition (ASR) networks can be scaled up with a simple routing algorithm in order to achieve better accuracy. More specifically, we apply the sparsely-gated MoE technique to two types of networks: Sequence-to-Sequence Transformer (S2S-T) and Transformer Transducer (T-T). We demonstrate through a set of ASR experiments on multiple language data that the MoE networks can reduce the relative word error rates by 16.3% and 4.6% with the S2S-T and T-T, respectively. Moreover, we thoroughly investigate the effect of the MoE on the T-T architecture in various conditions: streaming mode, non-streaming mode, the use of language ID and the label decoder with the MoE.
Reconstruct Anomaly to Normal: Adversarial Learned and Latent Vector-constrained Autoencoder for Time-series Anomaly Detection
Oct 14, 2020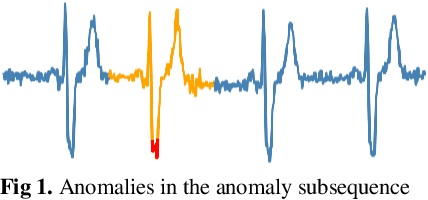
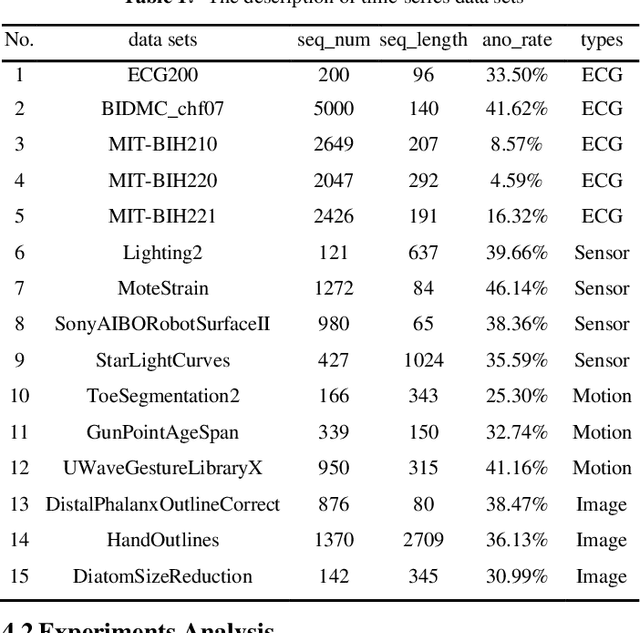
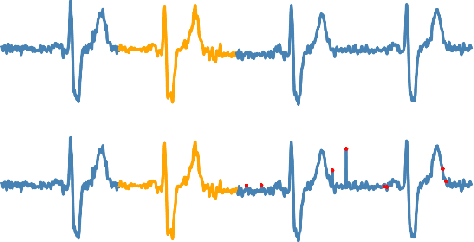
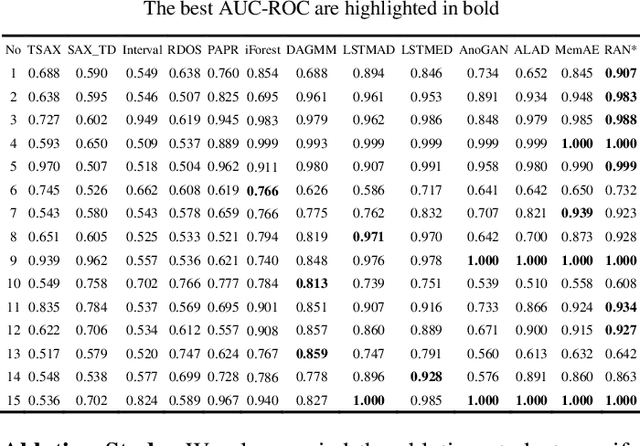
Anomaly detection in time series has been widely researched and has important practical applications. In recent years, anomaly detection algorithms are mostly based on deep-learning generative models and use the reconstruction error to detect anomalies. They try to capture the distribution of normal data by reconstructing normal data in the training phase, then calculate the reconstruction error of test data to do anomaly detection. However, most of them only use the normal data in the training phase and can not ensure the reconstruction process of anomaly data. So, anomaly data can also be well reconstructed sometimes and gets low reconstruction error, which leads to the omission of anomalies. What's more, the neighbor information of data points in time series data has not been fully utilized in these algorithms. In this paper, we propose RAN based on the idea of Reconstruct Anomalies to Normal and apply it for unsupervised time series anomaly detection. To minimize the reconstruction error of normal data and maximize this of anomaly data, we do not just ensure normal data to reconstruct well, but also try to make the reconstruction of anomaly data consistent with the distribution of normal data, then anomalies will get higher reconstruction errors. We implement this idea by introducing the "imitated anomaly data" and combining a specially designed latent vector-constrained Autoencoder with the discriminator to construct an adversary network. Extensive experiments on time-series datasets from different scenes such as ECG diagnosis also show that RAN can detect meaningful anomalies, and it outperforms other algorithms in terms of AUC-ROC.