 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShareVerse: Multi-Agent Consistent Video Generation for Shared World Modeling
Mar 03, 2026This paper presents ShareVerse, a video generation framework enabling multi-agent shared world modeling, addressing the gap in existing works that lack support for unified shared world construction with multi-agent interaction. ShareVerse leverages the generation capability of large video models and integrates three key innovations: 1) A dataset for large-scale multi-agent interactive world modeling is built on the CARLA simulation platform, featuring diverse scenes, weather conditions, and interactive trajectories with paired multi-view videos (front/ rear/ left/ right views per agent) and camera data. 2) We propose a spatial concatenation strategy for four-view videos of independent agents to model a broader environment and to ensure internal multi-view geometric consistency. 3) We integrate cross-agent attention blocks into the pretrained video model, which enable interactive transmission of spatial-temporal information across agents, guaranteeing shared world consistency in overlapping regions and reasonable generation in non-overlapping regions. ShareVerse, which supports 49-frame large-scale video generation, accurately perceives the position of dynamic agents and achieves consistent shared world modeling.
OmniLottie: Generating Vector Animations via Parameterized Lottie Tokens
Mar 02, 2026OmniLottie is a versatile framework that generates high quality vector animations from multi-modal instructions. For flexible motion and visual content control, we focus on Lottie, a light weight JSON formatting for both shapes and animation behaviors representation. However, the raw Lottie JSON files contain extensive invariant structural metadata and formatting tokens, posing significant challenges for learning vector animation generation. Therefore, we introduce a well designed Lottie tokenizer that transforms JSON files into structured sequences of commands and parameters representing shapes, animation functions and control parameters. Such tokenizer enables us to build OmniLottie upon pretrained vision language models to follow multi-modal interleaved instructions and generate high quality vector animations. To further advance research in vector animation generation, we curate MMLottie-2M, a large scale dataset of professionally designed vector animations paired with textual and visual annotations. With extensive experiments, we validate that OmniLottie can produce vivid and semantically aligned vector animations that adhere closely to multi modal human instructions.
BEAP-Agent: Backtrackable Execution and Adaptive Planning for GUI Agents
Jan 29, 2026GUI agents are designed to automate repetitive tasks and enhance productivity. However, existing GUI agents struggle to recover once they follow an incorrect exploration path, often leading to task failure. In this work, we model GUI task execution as a DFS process and propose BEAP-Agent, a DFS-based framework that supports long-range, multi-level state backtracking with dynamic task tracking and updating. The framework consists of three collaborative components: Planner, Executor, and Tracker. Together, they enable effective task exploration and execution. BEAP-Agent fills the gap in systematic backtracking mechanisms for GUI agents, offering a systematic solution for long-horizon task exploration. We conducted a systematic evaluation on the OSWorld benchmark, where BEAP-Agent achieved an accuracy of 28.2%, validating the effectiveness of the proposed method.
ReEx-SQL: Reasoning with Execution-Aware Reinforcement Learning for Text-to-SQL
May 19, 2025In Text-to-SQL, execution feedback is essential for guiding large language models (LLMs) to reason accurately and generate reliable SQL queries. However, existing methods treat execution feedback solely as a post-hoc signal for correction or selection, failing to integrate it into the generation process. This limitation hinders their ability to address reasoning errors as they occur, ultimately reducing query accuracy and robustness. To address this issue, we propose ReEx-SQL (Reasoning with Execution-Aware Reinforcement Learning), a framework for Text-to-SQL that enables models to interact with the database during decoding and dynamically adjust their reasoning based on execution feedback. ReEx-SQL introduces an execution-aware reasoning paradigm that interleaves intermediate SQL execution into reasoning paths, facilitating context-sensitive revisions. It achieves this through structured prompts with markup tags and a stepwise rollout strategy that integrates execution feedback into each stage of generation. To supervise policy learning, we develop a composite reward function that includes an exploration reward, explicitly encouraging effective database interaction. Additionally, ReEx-SQL adopts a tree-based decoding strategy to support exploratory reasoning, enabling dynamic expansion of alternative reasoning paths. Notably, ReEx-SQL achieves 88.8% on Spider and 64.9% on BIRD at the 7B scale, surpassing the standard reasoning baseline by 2.7% and 2.6%, respectively. It also shows robustness, achieving 85.2% on Spider-Realistic with leading performance. In addition, its tree-structured decoding improves efficiency and performance over linear decoding, reducing inference time by 51.9% on the BIRD development set.
StyleMe3D: Stylization with Disentangled Priors by Multiple Encoders on 3D Gaussians
Apr 21, 20253D Gaussian Splatting (3DGS) excels in photorealistic scene reconstruction but struggles with stylized scenarios (e.g., cartoons, games) due to fragmented textures, semantic misalignment, and limited adaptability to abstract aesthetics. We propose StyleMe3D, a holistic framework for 3D GS style transfer that integrates multi-modal style conditioning, multi-level semantic alignment, and perceptual quality enhancement. Our key insights include: (1) optimizing only RGB attributes preserves geometric integrity during stylization; (2) disentangling low-, medium-, and high-level semantics is critical for coherent style transfer; (3) scalability across isolated objects and complex scenes is essential for practical deployment. StyleMe3D introduces four novel components: Dynamic Style Score Distillation (DSSD), leveraging Stable Diffusion's latent space for semantic alignment; Contrastive Style Descriptor (CSD) for localized, content-aware texture transfer; Simultaneously Optimized Scale (SOS) to decouple style details and structural coherence; and 3D Gaussian Quality Assessment (3DG-QA), a differentiable aesthetic prior trained on human-rated data to suppress artifacts and enhance visual harmony. Evaluated on NeRF synthetic dataset (objects) and tandt db (scenes) datasets, StyleMe3D outperforms state-of-the-art methods in preserving geometric details (e.g., carvings on sculptures) and ensuring stylistic consistency across scenes (e.g., coherent lighting in landscapes), while maintaining real-time rendering. This work bridges photorealistic 3D GS and artistic stylization, unlocking applications in gaming, virtual worlds, and digital art.
OmniSVG: A Unified Scalable Vector Graphics Generation Model
Apr 08, 2025
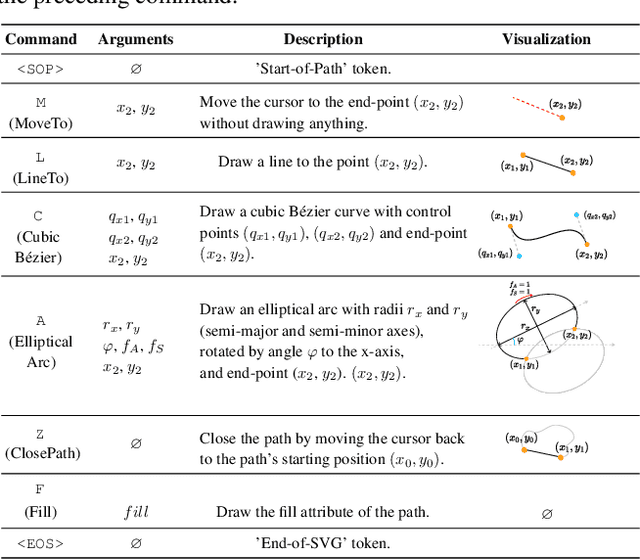


Scalable Vector Graphics (SVG) is an important image format widely adopted in graphic design because of their resolution independence and editability. The study of generating high-quality SVG has continuously drawn attention from both designers and researchers in the AIGC community. However, existing methods either produces unstructured outputs with huge computational cost or is limited to generating monochrome icons of over-simplified structures. To produce high-quality and complex SVG, we propose OmniSVG, a unified framework that leverages pre-trained Vision-Language Models (VLMs) for end-to-end multimodal SVG generation. By parameterizing SVG commands and coordinates into discrete tokens, OmniSVG decouples structural logic from low-level geometry for efficient training while maintaining the expressiveness of complex SVG structure. To further advance the development of SVG synthesis, we introduce MMSVG-2M, a multimodal dataset with two million richly annotated SVG assets, along with a standardized evaluation protocol for conditional SVG generation tasks. Extensive experiments show that OmniSVG outperforms existing methods and demonstrates its potential for integration into professional SVG design workflows.
Scene123: One Prompt to 3D Scene Generation via Video-Assisted and Consistency-Enhanced MAE
Aug 10, 2024



As Artificial Intelligence Generated Content (AIGC) advances, a variety of methods have been developed to generate text, images, videos, and 3D objects from single or multimodal inputs, contributing efforts to emulate human-like cognitive content creation. However, generating realistic large-scale scenes from a single input presents a challenge due to the complexities involved in ensuring consistency across extrapolated views generated by models. Benefiting from recent video generation models and implicit neural representations, we propose Scene123, a 3D scene generation model, that not only ensures realism and diversity through the video generation framework but also uses implicit neural fields combined with Masked Autoencoders (MAE) to effectively ensures the consistency of unseen areas across views. Specifically, we initially warp the input image (or an image generated from text) to simulate adjacent views, filling the invisible areas with the MAE model. However, these filled images usually fail to maintain view consistency, thus we utilize the produced views to optimize a neural radiance field, enhancing geometric consistency. Moreover, to further enhance the details and texture fidelity of generated views, we employ a GAN-based Loss against images derived from the input image through the video generation model. Extensive experiments demonstrate that our method can generate realistic and consistent scenes from a single prompt. Both qualitative and quantitative results indicate that our approach surpasses existing state-of-the-art methods. We show encourage video examples at https://yiyingyang12.github.io/Scene123.github.io/.
V2VSSC: A 3D Semantic Scene Completion Benchmark for Perception with Vehicle to Vehicle Communication
Feb 07, 2024



Semantic scene completion (SSC) has recently gained popularity because it can provide both semantic and geometric information that can be used directly for autonomous vehicle navigation. However, there are still challenges to overcome. SSC is often hampered by occlusion and short-range perception due to sensor limitations, which can pose safety risks. This paper proposes a fundamental solution to this problem by leveraging vehicle-to-vehicle (V2V) communication. We propose the first generalized collaborative SSC framework that allows autonomous vehicles to share sensing information from different sensor views to jointly perform SSC tasks. To validate the proposed framework, we further build V2VSSC, the first V2V SSC benchmark, on top of the large-scale V2V perception dataset OPV2V. Extensive experiments demonstrate that by leveraging V2V communication, the SSC performance can be increased by 8.3% on geometric metric IoU and 6.0% mIOU.
VQ-NeRF: Vector Quantization Enhances Implicit Neural Representations
Oct 23, 2023



Recent advancements in implicit neural representations have contributed to high-fidelity surface reconstruction and photorealistic novel view synthesis. However, the computational complexity inherent in these methodologies presents a substantial impediment, constraining the attainable frame rates and resolutions in practical applications. In response to this predicament, we propose VQ-NeRF, an effective and efficient pipeline for enhancing implicit neural representations via vector quantization. The essence of our method involves reducing the sampling space of NeRF to a lower resolution and subsequently reinstating it to the original size utilizing a pre-trained VAE decoder, thereby effectively mitigating the sampling time bottleneck encountered during rendering. Although the codebook furnishes representative features, reconstructing fine texture details of the scene remains challenging due to high compression rates. To overcome this constraint, we design an innovative multi-scale NeRF sampling scheme that concurrently optimizes the NeRF model at both compressed and original scales to enhance the network's ability to preserve fine details. Furthermore, we incorporate a semantic loss function to improve the geometric fidelity and semantic coherence of our 3D reconstructions. Extensive experiments demonstrate the effectiveness of our model in achieving the optimal trade-off between rendering quality and efficiency. Evaluation on the DTU, BlendMVS, and H3DS datasets confirms the superior performance of our approach.
Progression Cognition Reinforcement Learning with Prioritized Experience for Multi-Vehicle Pursuit
Jun 08, 2023



Multi-vehicle pursuit (MVP) such as autonomous police vehicles pursuing suspects is important but very challenging due to its mission and safety critical nature. While multi-agent reinforcement learning (MARL) algorithms have been proposed for MVP problem in structured grid-pattern roads, the existing algorithms use randomly training samples in centralized learning, which leads to homogeneous agents showing low collaboration performance. For the more challenging problem of pursuing multiple evading vehicles, these algorithms typically select a fixed target evading vehicle for pursuing vehicles without considering dynamic traffic situation, which significantly reduces pursuing success rate. To address the above problems, this paper proposes a Progression Cognition Reinforcement Learning with Prioritized Experience for MVP (PEPCRL-MVP) in urban multi-intersection dynamic traffic scenes. PEPCRL-MVP uses a prioritization network to assess the transitions in the global experience replay buffer according to the parameters of each MARL agent. With the personalized and prioritized experience set selected via the prioritization network, diversity is introduced to the learning process of MARL, which can improve collaboration and task related performance. Furthermore, PEPCRL-MVP employs an attention module to extract critical features from complex urban traffic environments. These features are used to develop progression cognition method to adaptively group pursuing vehicles. Each group efficiently target one evading vehicle in dynamic driving environments. Extensive experiments conducted with a simulator over unstructured roads of an urban area show that PEPCRL-MVP is superior to other state-of-the-art methods. Specifically, PEPCRL-MVP improves pursuing efficiency by 3.95% over TD3-DMAP and its success rate is 34.78% higher than that of MADDPG. Codes are open sourced.