 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniT: Unified Multimodal Chain-of-Thought Test-time Scaling
Feb 12, 2026Unified models can handle both multimodal understanding and generation within a single architecture, yet they typically operate in a single pass without iteratively refining their outputs. Many multimodal tasks, especially those involving complex spatial compositions, multiple interacting objects, or evolving instructions, require decomposing instructions, verifying intermediate results, and making iterative corrections. While test-time scaling (TTS) has demonstrated that allocating additional inference compute for iterative reasoning substantially improves language model performance, extending this paradigm to unified multimodal models remains an open challenge. We introduce UniT, a framework for multimodal chain-of-thought test-time scaling that enables a single unified model to reason, verify, and refine across multiple rounds. UniT combines agentic data synthesis, unified model training, and flexible test-time inference to elicit cognitive behaviors including verification, subgoal decomposition, and content memory. Our key findings are: (1) unified models trained on short reasoning trajectories generalize to longer inference chains at test time; (2) sequential chain-of-thought reasoning provides a more scalable and compute-efficient TTS strategy than parallel sampling; (3) training on generation and editing trajectories improves out-of-distribution visual reasoning. These results establish multimodal test-time scaling as an effective paradigm for advancing both generation and understanding in unified models.
HairWeaver: Few-Shot Photorealistic Hair Motion Synthesis with Sim-to-Real Guided Video Diffusion
Feb 11, 2026We present HairWeaver, a diffusion-based pipeline that animates a single human image with realistic and expressive hair dynamics. While existing methods successfully control body pose, they lack specific control over hair, and as a result, fail to capture the intricate hair motions, resulting in stiff and unrealistic animations. HairWeaver overcomes this limitation using two specialized modules: a Motion-Context-LoRA to integrate motion conditions and a Sim2Real-Domain-LoRA to preserve the subject's photoreal appearance across different data domains. These lightweight components are designed to guide a video diffusion backbone while maintaining its core generative capabilities. By training on a specialized dataset of dynamic human motion generated from a CG simulator, HairWeaver affords fine control over hair motion and ultimately learns to produce highly realistic hair that responds naturally to movement. Comprehensive evaluations demonstrate that our approach sets a new state of the art, producing lifelike human hair animations with dynamic details.
Non-Markov Multi-Round Conversational Image Generation with History-Conditioned MLLMs
Jan 28, 2026Conversational image generation requires a model to follow user instructions across multiple rounds of interaction, grounded in interleaved text and images that accumulate as chat history. While recent multimodal large language models (MLLMs) can generate and edit images, most existing multi-turn benchmarks and training recipes are effectively Markov: the next output depends primarily on the most recent image, enabling shortcut solutions that ignore long-range history. In this work we formalize and target the more challenging non-Markov setting, where a user may refer back to earlier states, undo changes, or reference entities introduced several rounds ago. We present (i) non-Markov multi-round data construction strategies, including rollback-style editing that forces retrieval of earlier visual states and name-based multi-round personalization that binds names to appearances across rounds; (ii) a history-conditioned training and inference framework with token-level caching to prevent multi-round identity drift; and (iii) enabling improvements for high-fidelity image reconstruction and editable personalization, including a reconstruction-based DiT detokenizer and a multi-stage fine-tuning curriculum. We demonstrate that explicitly training for non-Markov interactions yields substantial improvements in multi-round consistency and instruction compliance, while maintaining strong single-round editing and personalization.
PhyGDPO: Physics-Aware Groupwise Direct Preference Optimization for Physically Consistent Text-to-Video Generation
Dec 31, 2025Recent advances in text-to-video (T2V) generation have achieved good visual quality, yet synthesizing videos that faithfully follow physical laws remains an open challenge. Existing methods mainly based on graphics or prompt extension struggle to generalize beyond simple simulated environments or learn implicit physical reasoning. The scarcity of training data with rich physics interactions and phenomena is also a problem. In this paper, we first introduce a Physics-Augmented video data construction Pipeline, PhyAugPipe, that leverages a vision-language model (VLM) with chain-of-thought reasoning to collect a large-scale training dataset, PhyVidGen-135K. Then we formulate a principled Physics-aware Groupwise Direct Preference Optimization, PhyGDPO, framework that builds upon the groupwise Plackett-Luce probabilistic model to capture holistic preferences beyond pairwise comparisons. In PhyGDPO, we design a Physics-Guided Rewarding (PGR) scheme that embeds VLM-based physics rewards to steer optimization toward physical consistency. We also propose a LoRA-Switch Reference (LoRA-SR) scheme that eliminates memory-heavy reference duplication for efficient training. Experiments show that our method significantly outperforms state-of-the-art open-source methods on PhyGenBench and VideoPhy2. Please check our project page at https://caiyuanhao1998.github.io/project/PhyGDPO for more video results. Our code, models, and data will be released at https://github.com/caiyuanhao1998/Open-PhyGDPO
Exploring MLLM-Diffusion Information Transfer with MetaCanvas
Dec 12, 2025Multimodal learning has rapidly advanced visual understanding, largely via multimodal large language models (MLLMs) that use powerful LLMs as cognitive cores. In visual generation, however, these powerful core models are typically reduced to global text encoders for diffusion models, leaving most of their reasoning and planning ability unused. This creates a gap: current multimodal LLMs can parse complex layouts, attributes, and knowledge-intensive scenes, yet struggle to generate images or videos with equally precise and structured control. We propose MetaCanvas, a lightweight framework that lets MLLMs reason and plan directly in spatial and spatiotemporal latent spaces and interface tightly with diffusion generators. We empirically implement MetaCanvas on three different diffusion backbones and evaluate it across six tasks, including text-to-image generation, text/image-to-video generation, image/video editing, and in-context video generation, each requiring precise layouts, robust attribute binding, and reasoning-intensive control. MetaCanvas consistently outperforms global-conditioning baselines, suggesting that treating MLLMs as latent-space planners is a promising direction for narrowing the gap between multimodal understanding and generation.
Beyond Pixels: Semantic-aware Typographic Attack for Geo-Privacy Protection
Nov 16, 2025Large Visual Language Models (LVLMs) now pose a serious yet overlooked privacy threat, as they can infer a social media user's geolocation directly from shared images, leading to unintended privacy leakage. While adversarial image perturbations provide a potential direction for geo-privacy protection, they require relatively strong distortions to be effective against LVLMs, which noticeably degrade visual quality and diminish an image's value for sharing. To overcome this limitation, we identify typographical attacks as a promising direction for protecting geo-privacy by adding text extension outside the visual content. We further investigate which textual semantics are effective in disrupting geolocation inference and design a two-stage, semantics-aware typographical attack that generates deceptive text to protect user privacy. Extensive experiments across three datasets demonstrate that our approach significantly reduces geolocation prediction accuracy of five state-of-the-art commercial LVLMs, establishing a practical and visually-preserving protection strategy against emerging geo-privacy threats.
Pushing the Limits of Safety: A Technical Report on the ATLAS Challenge 2025
Jun 14, 2025Multimodal Large Language Models (MLLMs) have enabled transformative advancements across diverse applications but remain susceptible to safety threats, especially jailbreak attacks that induce harmful outputs. To systematically evaluate and improve their safety, we organized the Adversarial Testing & Large-model Alignment Safety Grand Challenge (ATLAS) 2025}. This technical report presents findings from the competition, which involved 86 teams testing MLLM vulnerabilities via adversarial image-text attacks in two phases: white-box and black-box evaluations. The competition results highlight ongoing challenges in securing MLLMs and provide valuable guidance for developing stronger defense mechanisms. The challenge establishes new benchmarks for MLLM safety evaluation and lays groundwork for advancing safer multimodal AI systems. The code and data for this challenge are openly available at https://github.com/NY1024/ATLAS_Challenge_2025.
Token-Shuffle: Towards High-Resolution Image Generation with Autoregressive Models
Apr 24, 2025Autoregressive (AR) models, long dominant in language generation, are increasingly applied to image synthesis but are often considered less competitive than Diffusion-based models. A primary limitation is the substantial number of image tokens required for AR models, which constrains both training and inference efficiency, as well as image resolution. To address this, we present Token-Shuffle, a novel yet simple method that reduces the number of image tokens in Transformer. Our key insight is the dimensional redundancy of visual vocabularies in Multimodal Large Language Models (MLLMs), where low-dimensional visual codes from visual encoder are directly mapped to high-dimensional language vocabularies. Leveraging this, we consider two key operations: token-shuffle, which merges spatially local tokens along channel dimension to decrease the input token number, and token-unshuffle, which untangles the inferred tokens after Transformer blocks to restore the spatial arrangement for output. Jointly training with textual prompts, our strategy requires no additional pretrained text-encoder and enables MLLMs to support extremely high-resolution image synthesis in a unified next-token prediction way while maintaining efficient training and inference. For the first time, we push the boundary of AR text-to-image generation to a resolution of 2048x2048 with gratifying generation performance. In GenAI-benchmark, our 2.7B model achieves 0.77 overall score on hard prompts, outperforming AR models LlamaGen by 0.18 and diffusion models LDM by 0.15. Exhaustive large-scale human evaluations also demonstrate our prominent image generation ability in terms of text-alignment, visual flaw, and visual appearance. We hope that Token-Shuffle can serve as a foundational design for efficient high-resolution image generation within MLLMs.
A Comprehensive Survey in LLM(-Agent) Full Stack Safety: Data, Training and Deployment
Apr 22, 2025The remarkable success of Large Language Models (LLMs) has illuminated a promising pathway toward achieving Artificial General Intelligence for both academic and industrial communities, owing to their unprecedented performance across various applications. As LLMs continue to gain prominence in both research and commercial domains, their security and safety implications have become a growing concern, not only for researchers and corporations but also for every nation. Currently, existing surveys on LLM safety primarily focus on specific stages of the LLM lifecycle, e.g., deployment phase or fine-tuning phase, lacking a comprehensive understanding of the entire "lifechain" of LLMs. To address this gap, this paper introduces, for the first time, the concept of "full-stack" safety to systematically consider safety issues throughout the entire process of LLM training, deployment, and eventual commercialization. Compared to the off-the-shelf LLM safety surveys, our work demonstrates several distinctive advantages: (I) Comprehensive Perspective. We define the complete LLM lifecycle as encompassing data preparation, pre-training, post-training, deployment and final commercialization. To our knowledge, this represents the first safety survey to encompass the entire lifecycle of LLMs. (II) Extensive Literature Support. Our research is grounded in an exhaustive review of over 800+ papers, ensuring comprehensive coverage and systematic organization of security issues within a more holistic understanding. (III) Unique Insights. Through systematic literature analysis, we have developed reliable roadmaps and perspectives for each chapter. Our work identifies promising research directions, including safety in data generation, alignment techniques, model editing, and LLM-based agent systems. These insights provide valuable guidance for researchers pursuing future work in this field.
Transfer between Modalities with MetaQueries
Apr 08, 2025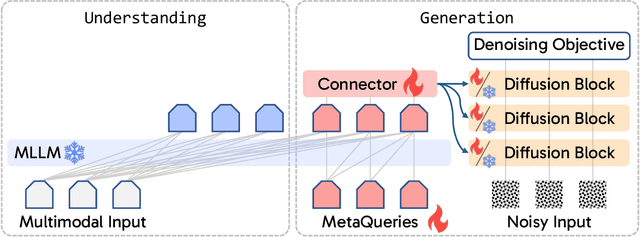


Unified multimodal models aim to integrate understanding (text output) and generation (pixel output), but aligning these different modalities within a single architecture often demands complex training recipes and careful data balancing. We introduce MetaQueries, a set of learnable queries that act as an efficient interface between autoregressive multimodal LLMs (MLLMs) and diffusion models. MetaQueries connects the MLLM's latents to the diffusion decoder, enabling knowledge-augmented image generation by leveraging the MLLM's deep understanding and reasoning capabilities. Our method simplifies training, requiring only paired image-caption data and standard diffusion objectives. Notably, this transfer is effective even when the MLLM backbone remains frozen, thereby preserving its state-of-the-art multimodal understanding capabilities while achieving strong generative performance. Additionally, our method is flexible and can be easily instruction-tuned for advanced applications such as image editing and subject-driven generation.