 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Evaluate Monocular Depth Estimation?
Oct 22, 2025Monocular depth estimation is an important task with rapid progress, but how to evaluate it remains an open question, as evidenced by a lack of standardization in existing literature and a large selection of evaluation metrics whose trade-offs and behaviors are not well understood. This paper contributes a novel, quantitative analysis of existing metrics in terms of their sensitivity to various types of perturbations of ground truth, emphasizing comparison to human judgment. Our analysis reveals that existing metrics are severely under-sensitive to curvature perturbation such as making flat surfaces wavy. To remedy this, we introduce a new metric based on relative surface normals, along with new depth visualization tools and a principled method to create composite metrics with better human alignment. Code and data are available at: https://github.com/princeton-vl/evalmde.
How do Language Models Generate Slang: A Systematic Comparison between Human and Machine-Generated Slang Usages
Sep 19, 2025



Slang is a commonly used type of informal language that poses a daunting challenge to NLP systems. Recent advances in large language models (LLMs), however, have made the problem more approachable. While LLM agents are becoming more widely applied to intermediary tasks such as slang detection and slang interpretation, their generalizability and reliability are heavily dependent on whether these models have captured structural knowledge about slang that align well with human attested slang usages. To answer this question, we contribute a systematic comparison between human and machine-generated slang usages. Our evaluative framework focuses on three core aspects: 1) Characteristics of the usages that reflect systematic biases in how machines perceive slang, 2) Creativity reflected by both lexical coinages and word reuses employed by the slang usages, and 3) Informativeness of the slang usages when used as gold-standard examples for model distillation. By comparing human-attested slang usages from the Online Slang Dictionary (OSD) and slang generated by GPT-4o and Llama-3, we find significant biases in how LLMs perceive slang. Our results suggest that while LLMs have captured significant knowledge about the creative aspects of slang, such knowledge does not align with humans sufficiently to enable LLMs for extrapolative tasks such as linguistic analyses.
Evaluating Robustness of Monocular Depth Estimation with Procedural Scene Perturbations
Jul 01, 2025Recent years have witnessed substantial progress on monocular depth estimation, particularly as measured by the success of large models on standard benchmarks. However, performance on standard benchmarks does not offer a complete assessment, because most evaluate accuracy but not robustness. In this work, we introduce PDE (Procedural Depth Evaluation), a new benchmark which enables systematic robustness evaluation. PDE uses procedural generation to create 3D scenes that test robustness to various controlled perturbations, including object, camera, material and lighting changes. Our analysis yields interesting findings on what perturbations are challenging for state-of-the-art depth models, which we hope will inform further research. Code and data are available at https://github.com/princeton-vl/proc-depth-eval.
Pushing the Limits of Safety: A Technical Report on the ATLAS Challenge 2025
Jun 14, 2025Multimodal Large Language Models (MLLMs) have enabled transformative advancements across diverse applications but remain susceptible to safety threats, especially jailbreak attacks that induce harmful outputs. To systematically evaluate and improve their safety, we organized the Adversarial Testing & Large-model Alignment Safety Grand Challenge (ATLAS) 2025}. This technical report presents findings from the competition, which involved 86 teams testing MLLM vulnerabilities via adversarial image-text attacks in two phases: white-box and black-box evaluations. The competition results highlight ongoing challenges in securing MLLMs and provide valuable guidance for developing stronger defense mechanisms. The challenge establishes new benchmarks for MLLM safety evaluation and lays groundwork for advancing safer multimodal AI systems. The code and data for this challenge are openly available at https://github.com/NY1024/ATLAS_Challenge_2025.
Language Models Surface the Unwritten Code of Science and Society
May 25, 2025



This paper calls on the research community not only to investigate how human biases are inherited by large language models (LLMs) but also to explore how these biases in LLMs can be leveraged to make society's "unwritten code" - such as implicit stereotypes and heuristics - visible and accessible for critique. We introduce a conceptual framework through a case study in science: uncovering hidden rules in peer review - the factors that reviewers care about but rarely state explicitly due to normative scientific expectations. The idea of the framework is to push LLMs to speak out their heuristics through generating self-consistent hypotheses - why one paper appeared stronger in reviewer scoring - among paired papers submitted to 45 computer science conferences, while iteratively searching deeper hypotheses from remaining pairs where existing hypotheses cannot explain. We observed that LLMs' normative priors about the internal characteristics of good science extracted from their self-talk, e.g. theoretical rigor, were systematically updated toward posteriors that emphasize storytelling about external connections, such as how the work is positioned and connected within and across literatures. This shift reveals the primacy of scientific myths about intrinsic properties driving scientific excellence rather than extrinsic contextualization and storytelling that influence conceptions of relevance and significance. Human reviewers tend to explicitly reward aspects that moderately align with LLMs' normative priors (correlation = 0.49) but avoid articulating contextualization and storytelling posteriors in their review comments (correlation = -0.14), despite giving implicit reward to them with positive scores. We discuss the broad applicability of the framework, leveraging LLMs as diagnostic tools to surface the tacit codes underlying human society, enabling more precisely targeted responsible AI.
Introspective Growth: Automatically Advancing LLM Expertise in Technology Judgment
May 18, 2025



Large language models (LLMs) increasingly demonstrate signs of conceptual understanding, yet much of their internal knowledge remains latent, loosely structured, and difficult to access or evaluate. We propose self-questioning as a lightweight and scalable strategy to improve LLMs' understanding, particularly in domains where success depends on fine-grained semantic distinctions. To evaluate this approach, we introduce a challenging new benchmark of 1.3 million post-2015 computer science patent pairs, characterized by dense technical jargon and strategically complex writing. The benchmark centers on a pairwise differentiation task: can a model distinguish between closely related but substantively different inventions? We show that prompting LLMs to generate and answer their own questions - targeting the background knowledge required for the task - significantly improves performance. These self-generated questions and answers activate otherwise underutilized internal knowledge. Allowing LLMs to retrieve answers from external scientific texts further enhances performance, suggesting that model knowledge is compressed and lacks the full richness of the training data. We also find that chain-of-thought prompting and self-questioning converge, though self-questioning remains more effective for improving understanding of technical concepts. Notably, we uncover an asymmetry in prompting: smaller models often generate more fundamental, more open-ended, better-aligned questions for mid-sized models than large models with better understanding do, revealing a new strategy for cross-model collaboration. Altogether, our findings establish self-questioning as both a practical mechanism for automatically improving LLM comprehension, especially in domains with sparse and underrepresented knowledge, and a diagnostic probe of how internal and external knowledge are organized.
Adversarial Examples in the Physical World: A Survey
Nov 01, 2023Deep neural networks (DNNs) have demonstrated high vulnerability to adversarial examples. Besides the attacks in the digital world, the practical implications of adversarial examples in the physical world present significant challenges and safety concerns. However, current research on physical adversarial examples (PAEs) lacks a comprehensive understanding of their unique characteristics, leading to limited significance and understanding. In this paper, we address this gap by thoroughly examining the characteristics of PAEs within a practical workflow encompassing training, manufacturing, and re-sampling processes. By analyzing the links between physical adversarial attacks, we identify manufacturing and re-sampling as the primary sources of distinct attributes and particularities in PAEs. Leveraging this knowledge, we develop a comprehensive analysis and classification framework for PAEs based on their specific characteristics, covering over 100 studies on physical-world adversarial examples. Furthermore, we investigate defense strategies against PAEs and identify open challenges and opportunities for future research. We aim to provide a fresh, thorough, and systematic understanding of PAEs, thereby promoting the development of robust adversarial learning and its application in open-world scenarios.
Automatic Truss Design with Reinforcement Learning
Jun 27, 2023



Truss layout design, namely finding a lightweight truss layout satisfying all the physical constraints, is a fundamental problem in the building industry. Generating the optimal layout is a challenging combinatorial optimization problem, which can be extremely expensive to solve by exhaustive search. Directly applying end-to-end reinforcement learning (RL) methods to truss layout design is infeasible either, since only a tiny portion of the entire layout space is valid under the physical constraints, leading to particularly sparse rewards for RL training. In this paper, we develop AutoTruss, a two-stage framework to efficiently generate both lightweight and valid truss layouts. AutoTruss first adopts Monte Carlo tree search to discover a diverse collection of valid layouts. Then RL is applied to iteratively refine the valid solutions. We conduct experiments and ablation studies in popular truss layout design test cases in both 2D and 3D settings. AutoTruss outperforms the best-reported layouts by 25.1% in the most challenging 3D test cases, resulting in the first effective deep-RL-based approach in the truss layout design literature.
Visual Dexterity: In-hand Dexterous Manipulation from Depth
Nov 21, 2022In-hand object reorientation is necessary for performing many dexterous manipulation tasks, such as tool use in unstructured environments that remain beyond the reach of current robots. Prior works built reorientation systems that assume one or many of the following specific circumstances: reorienting only specific objects with simple shapes, limited range of reorientation, slow or quasistatic manipulation, the need for specialized and costly sensor suites, simulation-only results, and other constraints which make the system infeasible for real-world deployment. We overcome these limitations and present a general object reorientation controller that is trained using reinforcement learning in simulation and evaluated in the real world. Our system uses readings from a single commodity depth camera to dynamically reorient complex objects by any amount in real time. The controller generalizes to novel objects not used during training. It is successful in the most challenging test: the ability to reorient objects in the air held by a downward-facing hand that must counteract gravity during reorientation. The results demonstrate that the policy transfer from simulation to the real world can be accomplished even for dynamic and contact-rich tasks. Lastly, our hardware only uses open-source components that cost less than five thousand dollars. Such construction makes it possible to replicate the work and democratize future research in dexterous manipulation. Videos are available at: https://taochenshh.github.io/projects/visual-dexterity.
Containerized Distributed Value-Based Multi-Agent Reinforcement Learning
Oct 15, 2021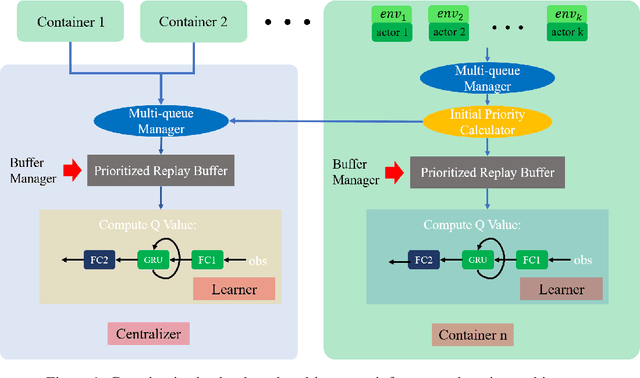
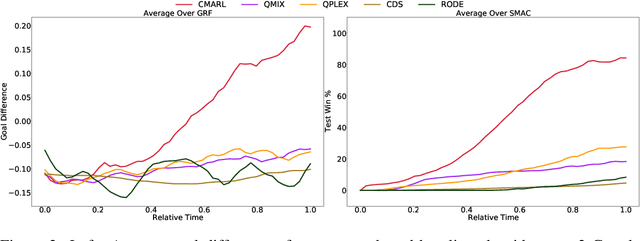
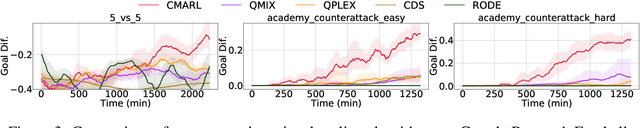
Multi-agent reinforcement learning tasks put a high demand on the volume of training samples. Different from its single-agent counterpart, distributed value-based multi-agent reinforcement learning faces the unique challenges of demanding data transfer, inter-process communication management, and high requirement of exploration. We propose a containerized learning framework to solve these problems. We pack several environment instances, a local learner and buffer, and a carefully designed multi-queue manager which avoids blocking into a container. Local policies of each container are encouraged to be as diverse as possible, and only trajectories with highest priority are sent to a global learner. In this way, we achieve a scalable, time-efficient, and diverse distributed MARL learning framework with high system throughput. To own knowledge, our method is the first to solve the challenging Google Research Football full game $5\_v\_5$. On the StarCraft II micromanagement benchmark, our method gets $4$-$18\times$ better results compared to state-of-the-art non-distributed MARL algorithms.