 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepFusion: Leveraging Multimodal Priors for Denoising in Representation Space
Jun 12, 2026Large language models (LLMs) are widely used in text-to-image (T2I) systems, but they are typically limited to text encoding, while denoising is handled by newly trained generative backbones. The emergence of representation autoencoders (RAEs) shifts the generation target toward semantically structured visual representations, creating a latent space that is more compatible with pretrained LLM priors. Inspired by multimodal LLMs (MLLMs), where an MLP projector is sufficient to align clean visual representations with a pretrained LLM, we repurpose the MLLM itself as a noisy representation encoder, extending this mechanism from clean to noisy inputs. We present RepFusion, which uses the resulting MLLM outputs as the conditioning signal for a diffusion transformer. In controlled comparisons at similar inference budgets, RepFusion outperforms baselines that devote comparable capacity to newly initialized denoisers. These results demonstrate that MLLMs provide strong priors for denoising visual representations and that, by conditioning on evolving noisy representations, test-time compute can be productively spent on repeated MLLM conditioning in modern T2I systems.
An Attribute-Based Measure of Video Complexity
May 30, 2026A new framework for the estimation of the complexity posed by video-question pairs to video-LLMs, Video Attribute-Based Complexity (VideoABC), is proposed. Video complexity is defined as the probability of failure of a video-LLM for a given video-question pair. VideoABC is a non-parametric complexity measure, using a reference video dataset and a pre-defined vocabulary of video attributes informative of complexity, \eg the scene complexity or the speed of the video event informative of the question. In a training phase, reference videos are projected into the space of these attributes, which is then quantized. The expected ABC of each quantization cell is then computed. Given a new video and its projection into the attribute space, complexity is estimated by the expected ABC of the associated quantization cell. To enable the use of VideoABC with small reference video datasets, two quantizers are combined: a k-means quantizer that enables accurate complexity estimates for samples in the distribution of the reference dataset and a universal lattice quantizer that guarantees generalization to out-of-distribution samples. A synthetic video generation procedure, inspired by target-distractor manipulations of psychophysics studies, is proposed to populate the cells of the lattice quantizer during training, enabling the computation of their expected ABCs. Experimental results show that VideoABCis effective even with very low-dimensional attribute representations, substantially outperforming approaches like `video-LLM as judge' with much less complexity. Finally, the explainable nature of the VideoABC score, in terms of well-defined attributes, is shown to provide insights on how the attribute composition of benchmarks affects their complexity.
Verifiable Reasoning for LLM-based Generative Recommendation
Mar 08, 2026Reasoning in Large Language Models (LLMs) has recently shown strong potential in enhancing generative recommendation through deep understanding of complex user preference. Existing approaches follow a {reason-then-recommend} paradigm, where LLMs perform step-by-step reasoning before item generation. However, this paradigm inevitably suffers from reasoning degradation (i.e., homogeneous or error-accumulated reasoning) due to the lack of intermediate verification, thus undermining the recommendation. To bridge this gap, we propose a novel \textbf{\textit{reason-verify-recommend}} paradigm, which interleaves reasoning with verification to provide reliable feedback, guiding the reasoning process toward more faithful user preference understanding. To enable effective verification, we establish two key principles for verifier design: 1) reliability ensures accurate evaluation of reasoning correctness and informative guidance generation; and 2) multi-dimensionality emphasizes comprehensive verification across multi-dimensional user preferences. Accordingly, we propose an effective implementation called VRec. It employs a mixture of verifiers to ensure multi-dimensionality, while leveraging a proxy prediction objective to pursue reliability. Experiments on four real-world datasets demonstrate that VRec substantially enhances recommendation effectiveness and scalability without compromising efficiency. The codes can be found at https://github.com/Linxyhaha/Verifiable-Rec.
DREAM: Where Visual Understanding Meets Text-to-Image Generation
Mar 03, 2026Unifying visual representation learning and text-to-image (T2I) generation within a single model remains a central challenge in multimodal learning. We introduce DREAM, a unified framework that jointly optimizes discriminative and generative objectives, while learning strong visual representations. DREAM is built on two key techniques: During training, Masking Warmup, a progressive masking schedule, begins with minimal masking to establish the contrastive alignment necessary for representation learning, then gradually transitions to full masking for stable generative training. At inference, DREAM employs Semantically Aligned Decoding to align partially masked image candidates with the target text and select the best one for further decoding, improving text-image fidelity (+6.3%) without external rerankers. Trained solely on CC12M, DREAM achieves 72.7% ImageNet linear-probing accuracy (+1.1% over CLIP) and an FID of 4.25 (+6.2% over FLUID), with consistent gains in few-shot classification, semantic segmentation, and depth estimation. These results demonstrate that discriminative and generative objectives can be synergistic, allowing unified multimodal models that excel at both visual understanding and generation.
Xray-Visual Models: Scaling Vision models on Industry Scale Data
Feb 18, 2026We present Xray-Visual, a unified vision model architecture for large-scale image and video understanding trained on industry-scale social media data. Our model leverages over 15 billion curated image-text pairs and 10 billion video-hashtag pairs from Facebook and Instagram, employing robust data curation pipelines that incorporate balancing and noise suppression strategies to maximize semantic diversity while minimizing label noise. We introduce a three-stage training pipeline that combines self-supervised MAE, semi-supervised hashtag classification, and CLIP-style contrastive learning to jointly optimize image and video modalities. Our architecture builds on a Vision Transformer backbone enhanced with efficient token reorganization (EViT) for improved computational efficiency. Extensive experiments demonstrate that Xray-Visual achieves state-of-the-art performance across diverse benchmarks, including ImageNet for image classification, Kinetics and HMDB51 for video understanding, and MSCOCO for cross-modal retrieval. The model exhibits strong robustness to domain shift and adversarial perturbations. We further demonstrate that integrating large language models as text encoders (LLM2CLIP) significantly enhances retrieval performance and generalization capabilities, particularly in real-world environments. Xray-Visual establishes new benchmarks for scalable, multimodal vision models, while maintaining superior accuracy and computational efficiency.
Socratic Students: Teaching Language Models to Learn by Asking Questions
Dec 20, 2025Large Language Models (LLMs) excel at static interactions, where they answer user queries by retrieving knowledge encoded in their parameters. However, in many real-world settings, such as educational tutoring or medical assistance, relevant information is not directly available and must be actively acquired through dynamic interactions. An interactive agent would recognize its own uncertainty, ask targeted questions, and retain new knowledge efficiently. Prior work has primarily explored effective ways for a teacher to instruct the student, where the teacher identifies student gaps and provides guidance. In this work, we shift the focus to the student and investigate effective strategies to actively query the teacher in seeking useful information. Across math and coding benchmarks, where baseline student models begin with near-zero performance, we show that student-led approaches consistently yield absolute Pass@k improvements of at least 0.5 over static baselines. To improve question quality, we train students using Direct Preference Optimization (DPO) with guidance from either self or stronger students. We find that this guided training enables smaller models to learn how to ask better questions, further enhancing learning efficiency.
Think Then Embed: Generative Context Improves Multimodal Embedding
Oct 06, 2025There is a growing interest in Universal Multimodal Embeddings (UME), where models are required to generate task-specific representations. While recent studies show that Multimodal Large Language Models (MLLMs) perform well on such tasks, they treat MLLMs solely as encoders, overlooking their generative capacity. However, such an encoding paradigm becomes less effective as instructions become more complex and require compositional reasoning. Inspired by the proven effectiveness of chain-of-thought reasoning, we propose a general Think-Then-Embed (TTE) framework for UME, composed of a reasoner and an embedder. The reasoner MLLM first generates reasoning traces that explain complex queries, followed by an embedder that produces representations conditioned on both the original query and the intermediate reasoning. This explicit reasoning step enables more nuanced understanding of complex multimodal instructions. Our contributions are threefold. First, by leveraging a powerful MLLM reasoner, we achieve state-of-the-art performance on the MMEB-V2 benchmark, surpassing proprietary models trained on massive in-house datasets. Second, to reduce the dependency on large MLLM reasoners, we finetune a smaller MLLM reasoner using high-quality embedding-centric reasoning traces, achieving the best performance among open-source models with a 7% absolute gain over recently proposed models. Third, we investigate strategies for integrating the reasoner and embedder into a unified model for improved efficiency without sacrificing performance.
RESTRAIN: From Spurious Votes to Signals -- Self-Driven RL with Self-Penalization
Oct 02, 2025



Reinforcement learning with human-annotated data has boosted chain-of-thought reasoning in large reasoning models, but these gains come at high costs in labeled data while faltering on harder tasks. A natural next step is experience-driven learning, where models improve without curated labels by adapting to unlabeled data. We introduce RESTRAIN (REinforcement learning with Self-restraint), a self-penalizing RL framework that converts the absence of gold labels into a useful learning signal. Instead of overcommitting to spurious majority votes, RESTRAIN exploits signals from the model's entire answer distribution: penalizing overconfident rollouts and low-consistency examples while preserving promising reasoning chains. The self-penalization mechanism integrates seamlessly into policy optimization methods such as GRPO, enabling continual self-improvement without supervision. On challenging reasoning benchmarks, RESTRAIN delivers large gains using only unlabeled data. With Qwen3-4B-Base and OctoThinker Hybrid-8B-Base, it improves Pass@1 by up to +140.7 percent on AIME25, +36.2 percent on MMLU_STEM, and +19.6 percent on GPQA-Diamond, nearly matching gold-label training while using no gold labels. These results demonstrate that RESTRAIN establishes a scalable path toward stronger reasoning without gold labels.
Optimizing Recall or Relevance? A Multi-Task Multi-Head Approach for Item-to-Item Retrieval in Recommendation
Jun 06, 2025The task of item-to-item (I2I) retrieval is to identify a set of relevant and highly engaging items based on a given trigger item. It is a crucial component in modern recommendation systems, where users' previously engaged items serve as trigger items to retrieve relevant content for future engagement. However, existing I2I retrieval models in industry are primarily built on co-engagement data and optimized using the recall measure, which overly emphasizes co-engagement patterns while failing to capture semantic relevance. This often leads to overfitting short-term co-engagement trends at the expense of long-term benefits such as discovering novel interests and promoting content diversity. To address this challenge, we propose MTMH, a Multi-Task and Multi-Head I2I retrieval model that achieves both high recall and semantic relevance. Our model consists of two key components: 1) a multi-task learning loss for formally optimizing the trade-off between recall and semantic relevance, and 2) a multi-head I2I retrieval architecture for retrieving both highly co-engaged and semantically relevant items. We evaluate MTMH using proprietary data from a commercial platform serving billions of users and demonstrate that it can improve recall by up to 14.4% and semantic relevance by up to 56.6% compared with prior state-of-the-art models. We also conduct live experiments to verify that MTMH can enhance both short-term consumption metrics and long-term user-experience-related metrics. Our work provides a principled approach for jointly optimizing I2I recall and semantic relevance, which has significant implications for improving the overall performance of recommendation systems.
Transfer between Modalities with MetaQueries
Apr 08, 2025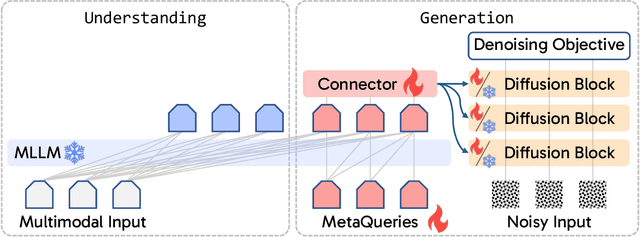


Unified multimodal models aim to integrate understanding (text output) and generation (pixel output), but aligning these different modalities within a single architecture often demands complex training recipes and careful data balancing. We introduce MetaQueries, a set of learnable queries that act as an efficient interface between autoregressive multimodal LLMs (MLLMs) and diffusion models. MetaQueries connects the MLLM's latents to the diffusion decoder, enabling knowledge-augmented image generation by leveraging the MLLM's deep understanding and reasoning capabilities. Our method simplifies training, requiring only paired image-caption data and standard diffusion objectives. Notably, this transfer is effective even when the MLLM backbone remains frozen, thereby preserving its state-of-the-art multimodal understanding capabilities while achieving strong generative performance. Additionally, our method is flexible and can be easily instruction-tuned for advanced applications such as image editing and subject-driven generation.