 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDREAM: Where Visual Understanding Meets Text-to-Image Generation
Mar 03, 2026Unifying visual representation learning and text-to-image (T2I) generation within a single model remains a central challenge in multimodal learning. We introduce DREAM, a unified framework that jointly optimizes discriminative and generative objectives, while learning strong visual representations. DREAM is built on two key techniques: During training, Masking Warmup, a progressive masking schedule, begins with minimal masking to establish the contrastive alignment necessary for representation learning, then gradually transitions to full masking for stable generative training. At inference, DREAM employs Semantically Aligned Decoding to align partially masked image candidates with the target text and select the best one for further decoding, improving text-image fidelity (+6.3%) without external rerankers. Trained solely on CC12M, DREAM achieves 72.7% ImageNet linear-probing accuracy (+1.1% over CLIP) and an FID of 4.25 (+6.2% over FLUID), with consistent gains in few-shot classification, semantic segmentation, and depth estimation. These results demonstrate that discriminative and generative objectives can be synergistic, allowing unified multimodal models that excel at both visual understanding and generation.
Think Then Embed: Generative Context Improves Multimodal Embedding
Oct 06, 2025There is a growing interest in Universal Multimodal Embeddings (UME), where models are required to generate task-specific representations. While recent studies show that Multimodal Large Language Models (MLLMs) perform well on such tasks, they treat MLLMs solely as encoders, overlooking their generative capacity. However, such an encoding paradigm becomes less effective as instructions become more complex and require compositional reasoning. Inspired by the proven effectiveness of chain-of-thought reasoning, we propose a general Think-Then-Embed (TTE) framework for UME, composed of a reasoner and an embedder. The reasoner MLLM first generates reasoning traces that explain complex queries, followed by an embedder that produces representations conditioned on both the original query and the intermediate reasoning. This explicit reasoning step enables more nuanced understanding of complex multimodal instructions. Our contributions are threefold. First, by leveraging a powerful MLLM reasoner, we achieve state-of-the-art performance on the MMEB-V2 benchmark, surpassing proprietary models trained on massive in-house datasets. Second, to reduce the dependency on large MLLM reasoners, we finetune a smaller MLLM reasoner using high-quality embedding-centric reasoning traces, achieving the best performance among open-source models with a 7% absolute gain over recently proposed models. Third, we investigate strategies for integrating the reasoner and embedder into a unified model for improved efficiency without sacrificing performance.
Transfer between Modalities with MetaQueries
Apr 08, 2025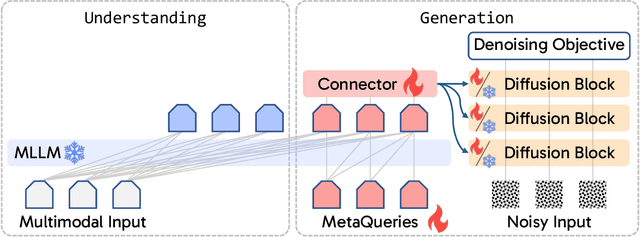


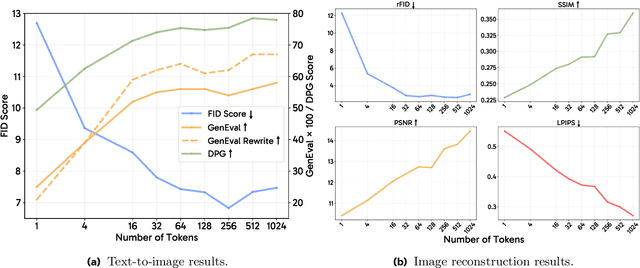
Unified multimodal models aim to integrate understanding (text output) and generation (pixel output), but aligning these different modalities within a single architecture often demands complex training recipes and careful data balancing. We introduce MetaQueries, a set of learnable queries that act as an efficient interface between autoregressive multimodal LLMs (MLLMs) and diffusion models. MetaQueries connects the MLLM's latents to the diffusion decoder, enabling knowledge-augmented image generation by leveraging the MLLM's deep understanding and reasoning capabilities. Our method simplifies training, requiring only paired image-caption data and standard diffusion objectives. Notably, this transfer is effective even when the MLLM backbone remains frozen, thereby preserving its state-of-the-art multimodal understanding capabilities while achieving strong generative performance. Additionally, our method is flexible and can be easily instruction-tuned for advanced applications such as image editing and subject-driven generation.
HaLP: Hallucinating Latent Positives for Skeleton-based Self-Supervised Learning of Actions
Apr 01, 2023Supervised learning of skeleton sequence encoders for action recognition has received significant attention in recent times. However, learning such encoders without labels continues to be a challenging problem. While prior works have shown promising results by applying contrastive learning to pose sequences, the quality of the learned representations is often observed to be closely tied to data augmentations that are used to craft the positives. However, augmenting pose sequences is a difficult task as the geometric constraints among the skeleton joints need to be enforced to make the augmentations realistic for that action. In this work, we propose a new contrastive learning approach to train models for skeleton-based action recognition without labels. Our key contribution is a simple module, HaLP - to Hallucinate Latent Positives for contrastive learning. Specifically, HaLP explores the latent space of poses in suitable directions to generate new positives. To this end, we present a novel optimization formulation to solve for the synthetic positives with an explicit control on their hardness. We propose approximations to the objective, making them solvable in closed form with minimal overhead. We show via experiments that using these generated positives within a standard contrastive learning framework leads to consistent improvements across benchmarks such as NTU-60, NTU-120, and PKU-II on tasks like linear evaluation, transfer learning, and kNN evaluation. Our code will be made available at https://github.com/anshulbshah/HaLP.
MAGE: MAsked Generative Encoder to Unify Representation Learning and Image Synthesis
Nov 16, 2022Generative modeling and representation learning are two key tasks in computer vision. However, these models are typically trained independently, which ignores the potential for each task to help the other, and leads to training and model maintenance overheads. In this work, we propose MAsked Generative Encoder (MAGE), the first framework to unify SOTA image generation and self-supervised representation learning. Our key insight is that using variable masking ratios in masked image modeling pre-training can allow generative training (very high masking ratio) and representation learning (lower masking ratio) under the same training framework. Inspired by previous generative models, MAGE uses semantic tokens learned by a vector-quantized GAN at inputs and outputs, combining this with masking. We can further improve the representation by adding a contrastive loss to the encoder output. We extensively evaluate the generation and representation learning capabilities of MAGE. On ImageNet-1K, a single MAGE ViT-L model obtains 9.10 FID in the task of class-unconditional image generation and 78.9% top-1 accuracy for linear probing, achieving state-of-the-art performance in both image generation and representation learning. Code is available at https://github.com/LTH14/mage.
Improved Detection of Face Presentation Attacks Using Image Decomposition
Mar 22, 2021



Presentation attack detection (PAD) is a critical component in secure face authentication. We present a PAD algorithm to distinguish face spoofs generated by a photograph of a subject from live images. Our method uses an image decomposition network to extract albedo and normal. The domain gap between the real and spoof face images leads to easily identifiable differences, especially between the recovered albedo maps. We enhance this domain gap by retraining existing methods using supervised contrastive loss. We present empirical and theoretical analysis that demonstrates that the contrast and lighting effects can play a significant role in PAD; these show up particularly in the recovered albedo. Finally, we demonstrate that by combining all of these methods we achieve state-of-the-art results on datasets such as CelebA-Spoof, OULU and CASIA-SURF.
Towards Automatic Generation of Questions from Long Answers
Apr 15, 2020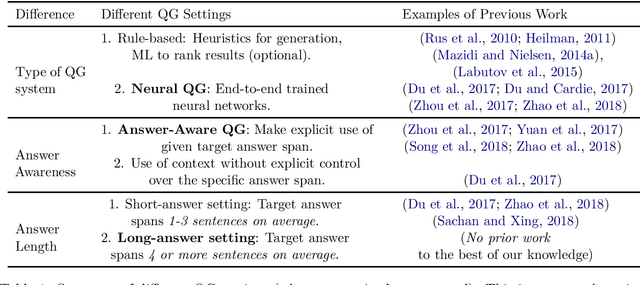

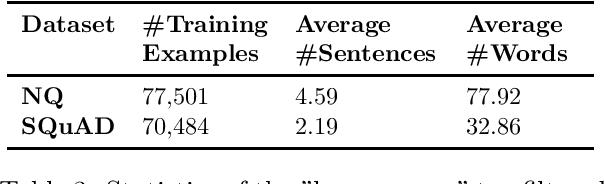
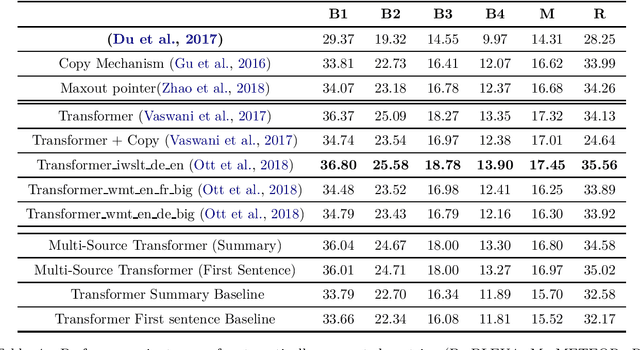
Automatic question generation (AQG) has broad applicability in domains such as tutoring systems, conversational agents, healthcare literacy, and information retrieval. Existing efforts at AQG have been limited to short answer lengths of up to two or three sentences. However, several real-world applications require question generation from answers that span several sentences. Therefore, we propose a novel evaluation benchmark to assess the performance of existing AQG systems for long-text answers. We leverage the large-scale open-source Google Natural Questions dataset to create the aforementioned long-answer AQG benchmark. We empirically demonstrate that the performance of existing AQG methods significantly degrades as the length of the answer increases. Transformer-based methods outperform other existing AQG methods on long answers in terms of automatic as well as human evaluation. However, we still observe degradation in the performance of our best performing models with increasing sentence length, suggesting that long answer QA is a challenging benchmark task for future research.