 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural data-to-text generation: A comparison between pipeline and end-to-end architectures
Aug 23, 2019
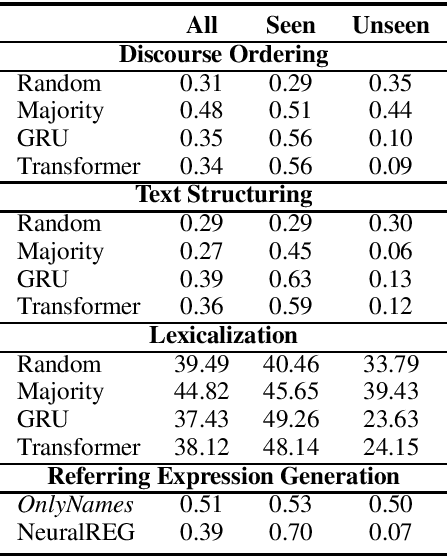
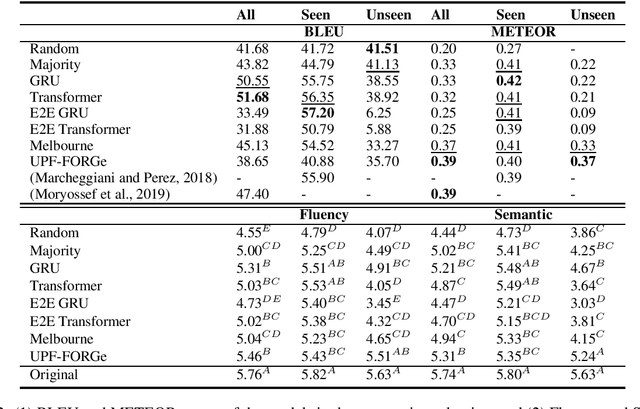

Traditionally, most data-to-text applications have been designed using a modular pipeline architecture, in which non-linguistic input data is converted into natural language through several intermediate transformations. In contrast, recent neural models for data-to-text generation have been proposed as end-to-end approaches, where the non-linguistic input is rendered in natural language with much less explicit intermediate representations in-between. This study introduces a systematic comparison between neural pipeline and end-to-end data-to-text approaches for the generation of text from RDF triples. Both architectures were implemented making use of state-of-the art deep learning methods as the encoder-decoder Gated-Recurrent Units (GRU) and Transformer. Automatic and human evaluations together with a qualitative analysis suggest that having explicit intermediate steps in the generation process results in better texts than the ones generated by end-to-end approaches. Moreover, the pipeline models generalize better to unseen inputs. Data and code are publicly available.
Cross-linguistic differences and similarities in image descriptions
Aug 13, 2017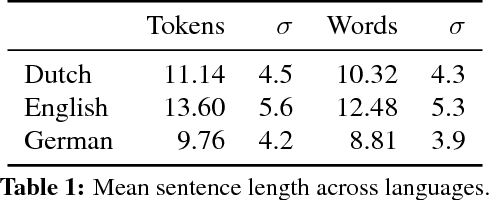
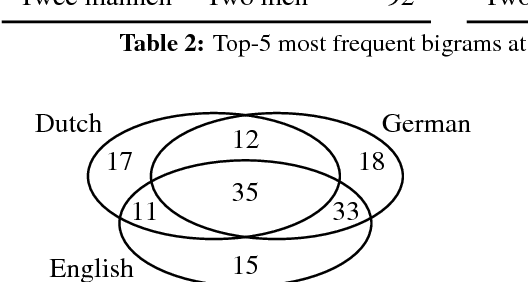


Automatic image description systems are commonly trained and evaluated on large image description datasets. Recently, researchers have started to collect such datasets for languages other than English. An unexplored question is how different these datasets are from English and, if there are any differences, what causes them to differ. This paper provides a cross-linguistic comparison of Dutch, English, and German image descriptions. We find that these descriptions are similar in many respects, but the familiarity of crowd workers with the subjects of the images has a noticeable influence on description specificity.
Room for improvement in automatic image description: an error analysis
Apr 13, 2017
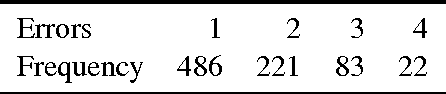
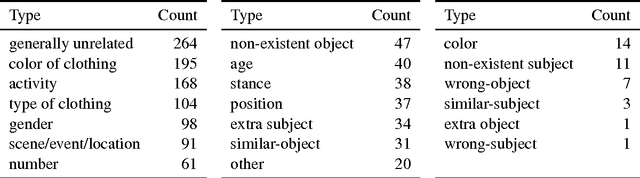
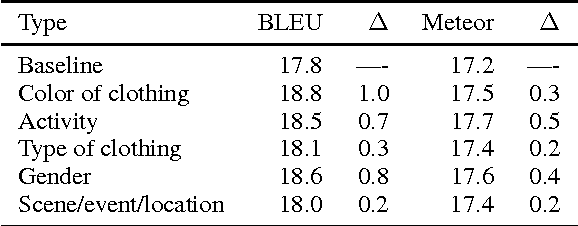
In recent years we have seen rapid and significant progress in automatic image description but what are the open problems in this area? Most work has been evaluated using text-based similarity metrics, which only indicate that there have been improvements, without explaining what has improved. In this paper, we present a detailed error analysis of the descriptions generated by a state-of-the-art attention-based model. Our analysis operates on two levels: first we check the descriptions for accuracy, and then we categorize the types of errors we observe in the inaccurate descriptions. We find only 20% of the descriptions are free from errors, and surprisingly that 26% are unrelated to the image. Finally, we manually correct the most frequently occurring error types (e.g. gender identification) to estimate the performance reward for addressing these errors, observing gains of 0.2--1 BLEU point per type.
Pragmatic factors in image description: the case of negations
Jun 27, 2016
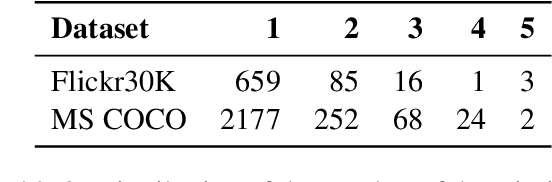
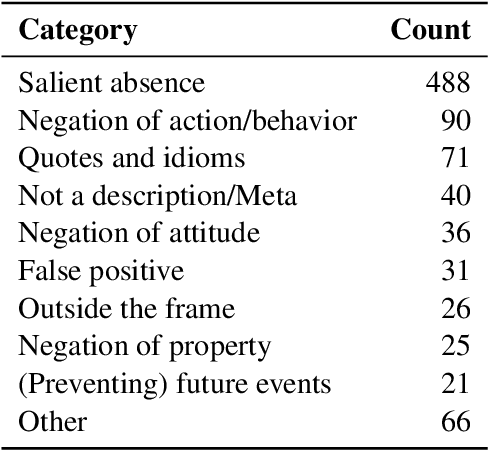
We provide a qualitative analysis of the descriptions containing negations (no, not, n't, nobody, etc) in the Flickr30K corpus, and a categorization of negation uses. Based on this analysis, we provide a set of requirements that an image description system should have in order to generate negation sentences. As a pilot experiment, we used our categorization to manually annotate sentences containing negations in the Flickr30K corpus, with an agreement score of K=0.67. With this paper, we hope to open up a broader discussion of subjective language in image descriptions.
Stereotyping and Bias in the Flickr30K Dataset
May 19, 2016
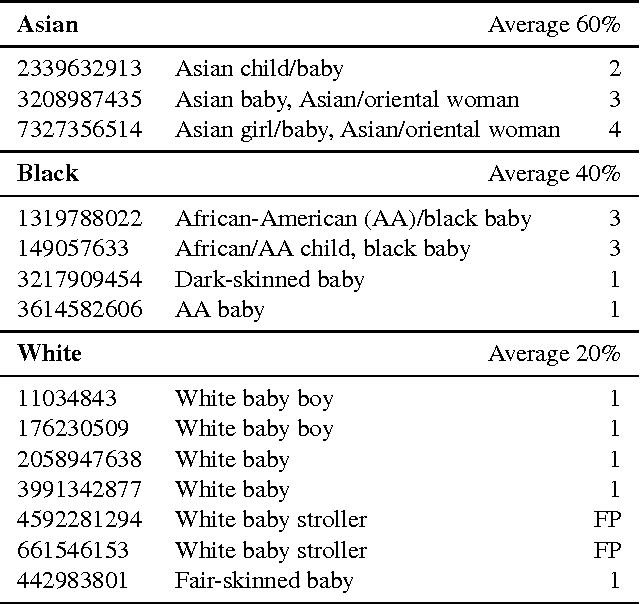

An untested assumption behind the crowdsourced descriptions of the images in the Flickr30K dataset (Young et al., 2014) is that they "focus only on the information that can be obtained from the image alone" (Hodosh et al., 2013, p. 859). This paper presents some evidence against this assumption, and provides a list of biases and unwarranted inferences that can be found in the Flickr30K dataset. Finally, it considers methods to find examples of these, and discusses how we should deal with stereotype-driven descriptions in future applications.
Detecting and ordering adjectival scalemates
Apr 30, 2015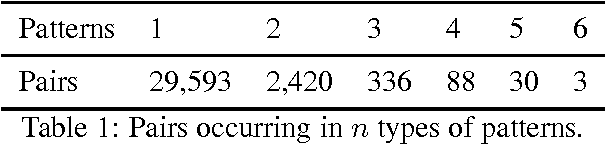
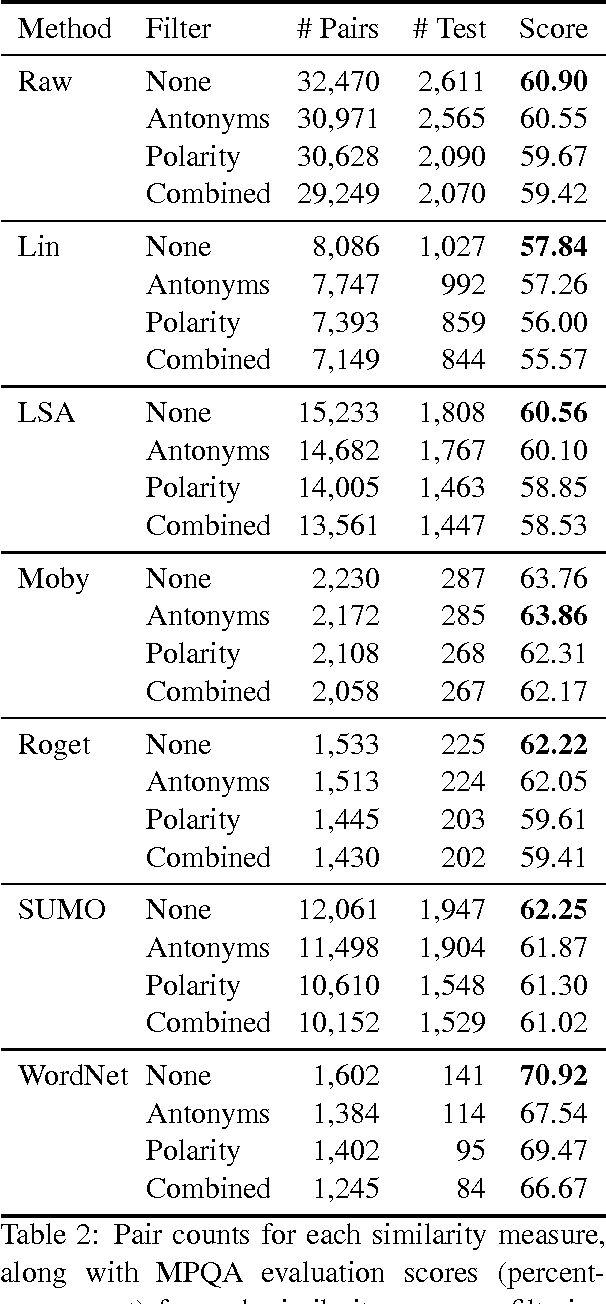
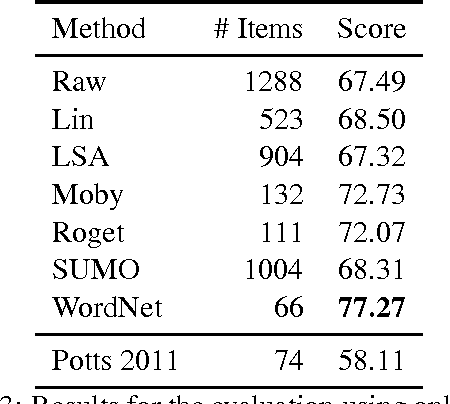
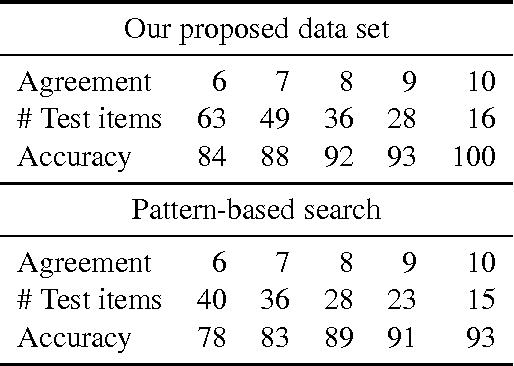
This paper presents a pattern-based method that can be used to infer adjectival scales, such as <lukewarm, warm, hot>, from a corpus. Specifically, the proposed method uses lexical patterns to automatically identify and order pairs of scalemates, followed by a filtering phase in which unrelated pairs are discarded. For the filtering phase, several different similarity measures are implemented and compared. The model presented in this paper is evaluated using the current standard, along with a novel evaluation set, and shown to be at least as good as the current state-of-the-art.