 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint What You Mean: Visually Grounded Instruction Policy
Dec 22, 2025



Vision-Language-Action (VLA) models align vision and language with embodied control, but their object referring ability remains limited when relying solely on text prompt, especially in cluttered or out-of-distribution (OOD) scenes. In this study, we introduce the Point-VLA, a plug-and-play policy that augments language instructions with explicit visual cues (e.g., bounding boxes) to resolve referential ambiguity and enable precise object-level grounding. To efficiently scale visually grounded datasets, we further develop an automatic data annotation pipeline requiring minimal human effort. We evaluate Point-VLA on diverse real-world referring tasks and observe consistently stronger performance than text-only instruction VLAs, particularly in cluttered or unseen-object scenarios, with robust generalization. These results demonstrate that Point-VLA effectively resolves object referring ambiguity through pixel-level visual grounding, achieving more generalizable embodied control.
Error-Free Linear Attention is a Free Lunch: Exact Solution from Continuous-Time Dynamics
Dec 14, 2025


Linear-time attention and State Space Models (SSMs) promise to solve the quadratic cost bottleneck in long-context language models employing softmax attention. We introduce Error-Free Linear Attention (EFLA), a numerically stable, fully parallelism and generalized formulation of the delta rule. Specifically, we formulate the online learning update as a continuous-time dynamical system and prove that its exact solution is not only attainable but also computable in linear time with full parallelism. By leveraging the rank-1 structure of the dynamics matrix, we directly derive the exact closed-form solution effectively corresponding to the infinite-order Runge-Kutta method. This attention mechanism is theoretically free from error accumulation, perfectly capturing the continuous dynamics while preserving the linear-time complexity. Through an extensive suite of experiments, we show that EFLA enables robust performance in noisy environments, achieving lower language modeling perplexity and superior downstream benchmark performance than DeltaNet without introducing additional parameters. Our work provides a new theoretical foundation for building high-fidelity, scalable linear-time attention models.
A Sensing Dataset Protocol for Benchmarking and Multi-Task Wireless Sensing
Dec 13, 2025



Wireless sensing has become a fundamental enabler for intelligent environments, supporting applications such as human detection, activity recognition, localization, and vital sign monitoring. Despite rapid advances, existing datasets and pipelines remain fragmented across sensing modalities, hindering fair comparison, transfer, and reproducibility. We propose the Sensing Dataset Protocol (SDP), a protocol-level specification and benchmark framework for large-scale wireless sensing. SDP defines how heterogeneous wireless signals are mapped into a unified perception data-block schema through lightweight synchronization, frequency-time alignment, and resampling, while a Canonical Polyadic-Alternating Least Squares (CP-ALS) pooling stage provides a task-agnostic representation that preserves multipath, spectral, and temporal structures. Built upon this protocol, a unified benchmark is established for detection, recognition, and vital-sign estimation with consistent preprocessing, training, and evaluation. Experiments under the cross-user split demonstrate that SDP significantly reduces variance (approximately 88%) across seeds while maintaining competitive accuracy and latency, confirming its value as a reproducible foundation for multi-modal and multitask sensing research.
FilmWeaver: Weaving Consistent Multi-Shot Videos with Cache-Guided Autoregressive Diffusion
Dec 12, 2025Current video generation models perform well at single-shot synthesis but struggle with multi-shot videos, facing critical challenges in maintaining character and background consistency across shots and flexibly generating videos of arbitrary length and shot count. To address these limitations, we introduce \textbf{FilmWeaver}, a novel framework designed to generate consistent, multi-shot videos of arbitrary length. First, it employs an autoregressive diffusion paradigm to achieve arbitrary-length video generation. To address the challenge of consistency, our key insight is to decouple the problem into inter-shot consistency and intra-shot coherence. We achieve this through a dual-level cache mechanism: a shot memory caches keyframes from preceding shots to maintain character and scene identity, while a temporal memory retains a history of frames from the current shot to ensure smooth, continuous motion. The proposed framework allows for flexible, multi-round user interaction to create multi-shot videos. Furthermore, due to this decoupled design, our method demonstrates high versatility by supporting downstream tasks such as multi-concept injection and video extension. To facilitate the training of our consistency-aware method, we also developed a comprehensive pipeline to construct a high-quality multi-shot video dataset. Extensive experimental results demonstrate that our method surpasses existing approaches on metrics for both consistency and aesthetic quality, opening up new possibilities for creating more consistent, controllable, and narrative-driven video content. Project Page: https://filmweaver.github.io
Fast Bayesian Updates via Harmonic Representations
Nov 10, 2025Bayesian inference, while foundational to probabilistic reasoning, is often hampered by the computational intractability of posterior distributions, particularly through the challenging evidence integral. Conventional approaches like Markov Chain Monte Carlo (MCMC) and Variational Inference (VI) face significant scalability and efficiency limitations. This paper introduces a novel, unifying framework for fast Bayesian updates by leveraging harmonic analysis. We demonstrate that representing the prior and likelihood in a suitable orthogonal basis transforms the Bayesian update rule into a spectral convolution. Specifically, the Fourier coefficients of the posterior are shown to be the normalized convolution of the prior and likelihood coefficients. To achieve computational feasibility, we introduce a spectral truncation scheme, which, for smooth functions, yields an exceptionally accurate finite-dimensional approximation and reduces the update to a circular convolution. This formulation allows us to exploit the Fast Fourier Transform (FFT), resulting in a deterministic algorithm with O(N log N) complexity -- a substantial improvement over the O(N^2) cost of naive methods. We establish rigorous mathematical criteria for the applicability of our method, linking its efficiency to the smoothness and spectral decay of the involved distributions. The presented work offers a paradigm shift, connecting Bayesian computation to signal processing and opening avenues for real-time, sequential inference in a wide class of problems.
NVIDIA Nemotron Nano V2 VL
Nov 07, 2025We introduce Nemotron Nano V2 VL, the latest model of the Nemotron vision-language series designed for strong real-world document understanding, long video comprehension, and reasoning tasks. Nemotron Nano V2 VL delivers significant improvements over our previous model, Llama-3.1-Nemotron-Nano-VL-8B, across all vision and text domains through major enhancements in model architecture, datasets, and training recipes. Nemotron Nano V2 VL builds on Nemotron Nano V2, a hybrid Mamba-Transformer LLM, and innovative token reduction techniques to achieve higher inference throughput in long document and video scenarios. We are releasing model checkpoints in BF16, FP8, and FP4 formats and sharing large parts of our datasets, recipes and training code.
Learning Geometry: A Framework for Building Adaptive Manifold Models through Metric Optimization
Oct 30, 2025This paper proposes a novel paradigm for machine learning that moves beyond traditional parameter optimization. Unlike conventional approaches that search for optimal parameters within a fixed geometric space, our core idea is to treat the model itself as a malleable geometric entity. Specifically, we optimize the metric tensor field on a manifold with a predefined topology, thereby dynamically shaping the geometric structure of the model space. To achieve this, we construct a variational framework whose loss function carefully balances data fidelity against the intrinsic geometric complexity of the manifold. The former ensures the model effectively explains observed data, while the latter acts as a regularizer, penalizing overly curved or irregular geometries to encourage simpler models and prevent overfitting. To address the computational challenges of this infinite-dimensional optimization problem, we introduce a practical method based on discrete differential geometry: the continuous manifold is discretized into a triangular mesh, and the metric tensor is parameterized by edge lengths, enabling efficient optimization using automatic differentiation tools. Theoretical analysis reveals a profound analogy between our framework and the Einstein-Hilbert action in general relativity, providing an elegant physical interpretation for the concept of "data-driven geometry". We further argue that even with fixed topology, metric optimization offers significantly greater expressive power than models with fixed geometry. This work lays a solid foundation for constructing fully dynamic "meta-learners" capable of autonomously evolving their geometry and topology, and it points to broad application prospects in areas such as scientific model discovery and robust representation learning.
Towards Stable and Effective Reinforcement Learning for Mixture-of-Experts
Oct 27, 2025Recent advances in reinforcement learning (RL) have substantially improved the training of large-scale language models, leading to significant gains in generation quality and reasoning ability. However, most existing research focuses on dense models, while RL training for Mixture-of-Experts (MoE) architectures remains underexplored. To address the instability commonly observed in MoE training, we propose a novel router-aware approach to optimize importance sampling (IS) weights in off-policy RL. Specifically, we design a rescaling strategy guided by router logits, which effectively reduces gradient variance and mitigates training divergence. Experimental results demonstrate that our method significantly improves both the convergence stability and the final performance of MoE models, highlighting the potential of RL algorithmic innovations tailored to MoE architectures and providing a promising direction for efficient training of large-scale expert models.
CMPhysBench: A Benchmark for Evaluating Large Language Models in Condensed Matter Physics
Aug 25, 2025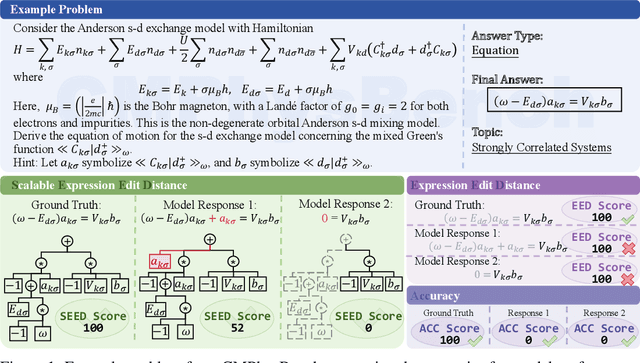
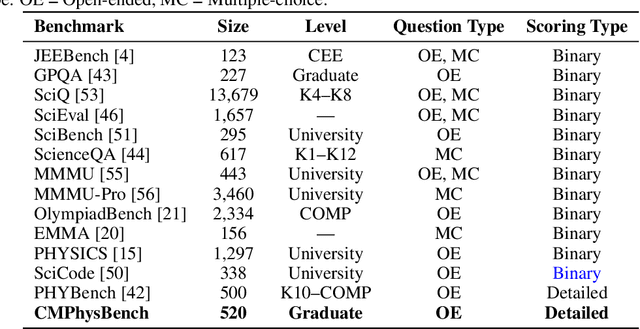
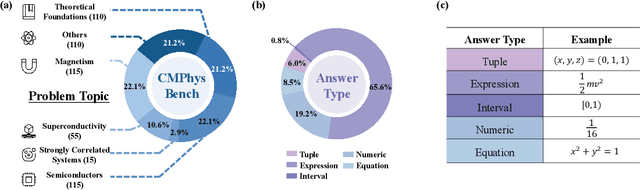

We introduce CMPhysBench, designed to assess the proficiency of Large Language Models (LLMs) in Condensed Matter Physics, as a novel Benchmark. CMPhysBench is composed of more than 520 graduate-level meticulously curated questions covering both representative subfields and foundational theoretical frameworks of condensed matter physics, such as magnetism, superconductivity, strongly correlated systems, etc. To ensure a deep understanding of the problem-solving process,we focus exclusively on calculation problems, requiring LLMs to independently generate comprehensive solutions. Meanwhile, leveraging tree-based representations of expressions, we introduce the Scalable Expression Edit Distance (SEED) score, which provides fine-grained (non-binary) partial credit and yields a more accurate assessment of similarity between prediction and ground-truth. Our results show that even the best models, Grok-4, reach only 36 average SEED score and 28% accuracy on CMPhysBench, underscoring a significant capability gap, especially for this practical and frontier domain relative to traditional physics. The code anddataset are publicly available at https://github.com/CMPhysBench/CMPhysBench.
MUSE: Multi-Subject Unified Synthesis via Explicit Layout Semantic Expansion
Aug 20, 2025Existing text-to-image diffusion models have demonstrated remarkable capabilities in generating high-quality images guided by textual prompts. However, achieving multi-subject compositional synthesis with precise spatial control remains a significant challenge. In this work, we address the task of layout-controllable multi-subject synthesis (LMS), which requires both faithful reconstruction of reference subjects and their accurate placement in specified regions within a unified image. While recent advancements have separately improved layout control and subject synthesis, existing approaches struggle to simultaneously satisfy the dual requirements of spatial precision and identity preservation in this composite task. To bridge this gap, we propose MUSE, a unified synthesis framework that employs concatenated cross-attention (CCA) to seamlessly integrate layout specifications with textual guidance through explicit semantic space expansion. The proposed CCA mechanism enables bidirectional modality alignment between spatial constraints and textual descriptions without interference. Furthermore, we design a progressive two-stage training strategy that decomposes the LMS task into learnable sub-objectives for effective optimization. Extensive experiments demonstrate that MUSE achieves zero-shot end-to-end generation with superior spatial accuracy and identity consistency compared to existing solutions, advancing the frontier of controllable image synthesis. Our code and model are available at https://github.com/pf0607/MUSE.