 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyReal: A Benchmark for Real-World Polymer Science Workflows
Apr 03, 2026Multimodal Large Language Models (MLLMs) excel in general domains but struggle with complex, real-world science. We posit that polymer science, an interdisciplinary field spanning chemistry, physics, biology, and engineering, is an ideal high-stakes testbed due to its diverse multimodal data. Yet, existing benchmarks related to polymer science largely overlook real-world workflows, limiting their practical utility and failing to systematically evaluate MLLMs across the full, practice-grounded lifecycle of experimentation. We introduce PolyReal, a novel multimodal benchmark grounded in real-world scientific practices to evaluate MLLMs on the full lifecycle of polymer experimentation. It covers five critical capabilities: (1) foundational knowledge application; (2) lab safety analysis; (3) experiment mechanism reasoning; (4) raw data extraction; and (5) performance & application exploration. Our evaluation of leading MLLMs on PolyReal reveals a capability imbalance. While models perform well on knowledge-intensive reasoning (e.g., Experiment Mechanism Reasoning), they drop sharply on practice-based tasks (e.g., Lab Safety Analysis and Raw Data Extraction). This exposes a severe gap between abstract scientific knowledge and its practical, context-dependent application, showing that these real-world tasks remain challenging for MLLMs. Thus, PolyReal helps address this evaluation gap and provides a practical benchmark for assessing AI systems in real-world scientific workflows.
Plan Then Action:High-Level Planning Guidance Reinforcement Learning for LLM Reasoning
Oct 02, 2025Large language models (LLMs) have demonstrated remarkable reasoning abilities in complex tasks, often relying on Chain-of-Thought (CoT) reasoning. However, due to their autoregressive token-level generation, the reasoning process is largely constrained to local decision-making and lacks global planning. This limitation frequently results in redundant, incoherent, or inaccurate reasoning, which significantly degrades overall performance. Existing approaches, such as tree-based algorithms and reinforcement learning (RL), attempt to address this issue but suffer from high computational costs and often fail to produce optimal reasoning trajectories. To tackle this challenge, we propose Plan-Then-Action Enhanced Reasoning with Group Relative Policy Optimization PTA-GRPO, a two-stage framework designed to improve both high-level planning and fine-grained CoT reasoning. In the first stage, we leverage advanced LLMs to distill CoT into compact high-level guidance, which is then used for supervised fine-tuning (SFT). In the second stage, we introduce a guidance-aware RL method that jointly optimizes the final output and the quality of high-level guidance, thereby enhancing reasoning effectiveness. We conduct extensive experiments on multiple mathematical reasoning benchmarks, including MATH, AIME2024, AIME2025, and AMC, across diverse base models such as Qwen2.5-7B-Instruct, Qwen3-8B, Qwen3-14B, and LLaMA3.2-3B. Experimental results demonstrate that PTA-GRPO consistently achieves stable and significant improvements across different models and tasks, validating its effectiveness and generalization.
CMPhysBench: A Benchmark for Evaluating Large Language Models in Condensed Matter Physics
Aug 25, 2025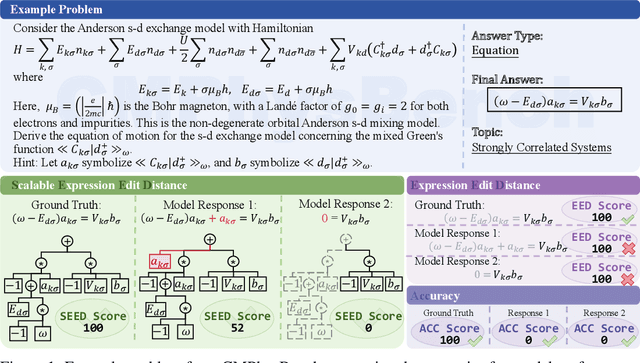
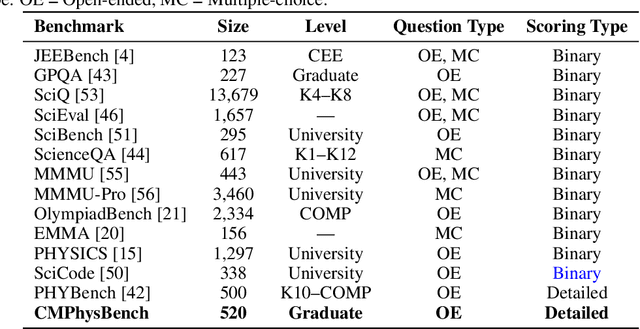
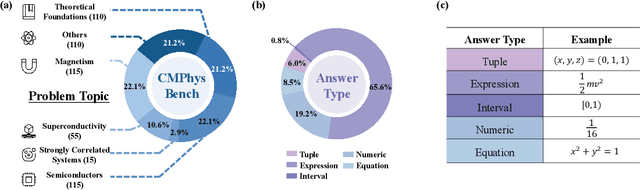

We introduce CMPhysBench, designed to assess the proficiency of Large Language Models (LLMs) in Condensed Matter Physics, as a novel Benchmark. CMPhysBench is composed of more than 520 graduate-level meticulously curated questions covering both representative subfields and foundational theoretical frameworks of condensed matter physics, such as magnetism, superconductivity, strongly correlated systems, etc. To ensure a deep understanding of the problem-solving process,we focus exclusively on calculation problems, requiring LLMs to independently generate comprehensive solutions. Meanwhile, leveraging tree-based representations of expressions, we introduce the Scalable Expression Edit Distance (SEED) score, which provides fine-grained (non-binary) partial credit and yields a more accurate assessment of similarity between prediction and ground-truth. Our results show that even the best models, Grok-4, reach only 36 average SEED score and 28% accuracy on CMPhysBench, underscoring a significant capability gap, especially for this practical and frontier domain relative to traditional physics. The code anddataset are publicly available at https://github.com/CMPhysBench/CMPhysBench.
DSADF: Thinking Fast and Slow for Decision Making
May 13, 2025



Although Reinforcement Learning (RL) agents are effective in well-defined environments, they often struggle to generalize their learned policies to dynamic settings due to their reliance on trial-and-error interactions. Recent work has explored applying Large Language Models (LLMs) or Vision Language Models (VLMs) to boost the generalization of RL agents through policy optimization guidance or prior knowledge. However, these approaches often lack seamless coordination between the RL agent and the foundation model, leading to unreasonable decision-making in unfamiliar environments and efficiency bottlenecks. Making full use of the inferential capabilities of foundation models and the rapid response capabilities of RL agents and enhancing the interaction between the two to form a dual system is still a lingering scientific question. To address this problem, we draw inspiration from Kahneman's theory of fast thinking (System 1) and slow thinking (System 2), demonstrating that balancing intuition and deep reasoning can achieve nimble decision-making in a complex world. In this study, we propose a Dual-System Adaptive Decision Framework (DSADF), integrating two complementary modules: System 1, comprising an RL agent and a memory space for fast and intuitive decision making, and System 2, driven by a VLM for deep and analytical reasoning. DSADF facilitates efficient and adaptive decision-making by combining the strengths of both systems. The empirical study in the video game environment: Crafter and Housekeep demonstrates the effectiveness of our proposed method, showing significant improvements in decision abilities for both unseen and known tasks.