 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomalyAgent: Agentic Industrial Anomaly Synthesis via Tool-Augmented Reinforcement Learning
Apr 09, 2026Industrial anomaly generation is a crucial method for alleviating the data scarcity problem in anomaly detection tasks. Most existing anomaly synthesis methods rely on single-step generation mechanisms, lacking complex reasoning and iterative optimization capabilities, making it difficult to generate anomaly samples with high semantic realism. We propose AnomalyAgent, an anomaly synthesis agent with self-reflection, knowledge retrieval, and iterative refinement capabilities, aiming to generate realistic and diverse anomalies. Specifically, AnomalyAgent is equipped with five tools: Prompt Generation (PG), Image Generation (IG), Quality Evaluation (QE), Knowledge Retrieval (KR), and Mask Generation (MG), enabling closed-loop optimization. To improve decision-making and self-reflection, we construct structured trajectories from real anomaly images and design a two-stage training framework: supervised fine-tuning followed by reinforcement learning. This process is driven by a three-part reward mechanism: (1) task rewards to supervise the quality and location rationality of generated anomalies; (2) reflection rewards to train the model's ability to improve anomaly synthesis prompt; (3) behavioral rewards to ensure adherence to the trajectory. On the MVTec-AD dataset, AnomalyAgent achieves IS/IC-L of 2.10/0.33 for anomaly generation, 57.0% classification accuracy using ResNet34, and 99.3%/74.2% AP at the image/pixel level using a simple UNet, surpassing all zero-shot SOTA methods. The code and data will be made publicly available.
CMPhysBench: A Benchmark for Evaluating Large Language Models in Condensed Matter Physics
Aug 25, 2025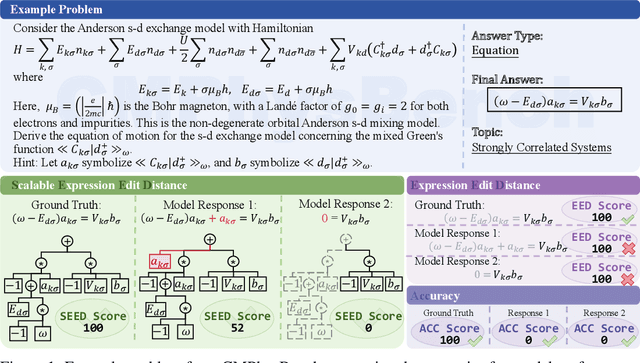
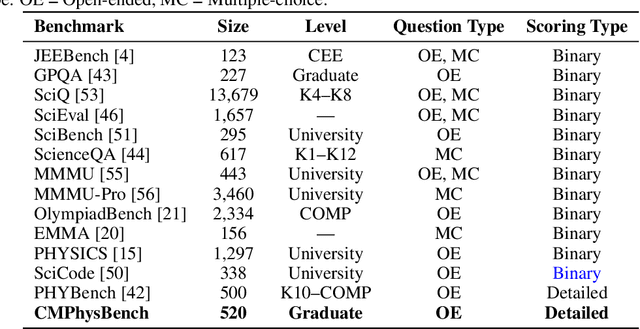
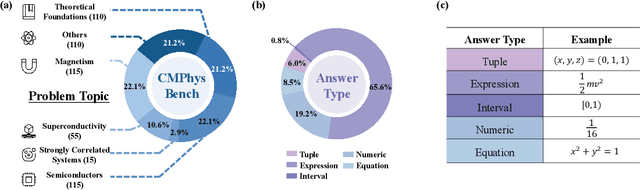

We introduce CMPhysBench, designed to assess the proficiency of Large Language Models (LLMs) in Condensed Matter Physics, as a novel Benchmark. CMPhysBench is composed of more than 520 graduate-level meticulously curated questions covering both representative subfields and foundational theoretical frameworks of condensed matter physics, such as magnetism, superconductivity, strongly correlated systems, etc. To ensure a deep understanding of the problem-solving process,we focus exclusively on calculation problems, requiring LLMs to independently generate comprehensive solutions. Meanwhile, leveraging tree-based representations of expressions, we introduce the Scalable Expression Edit Distance (SEED) score, which provides fine-grained (non-binary) partial credit and yields a more accurate assessment of similarity between prediction and ground-truth. Our results show that even the best models, Grok-4, reach only 36 average SEED score and 28% accuracy on CMPhysBench, underscoring a significant capability gap, especially for this practical and frontier domain relative to traditional physics. The code anddataset are publicly available at https://github.com/CMPhysBench/CMPhysBench.