 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Distillation as Latent Memory Management
May 27, 2026Context distillation compresses contextual information into model parameters, yet existing methods often ignore how multiple distilled latent memories should be stored, retrieved, and safely activated in non-oracle settings. We formulate context distillation as a latent memory management problem. We distill each context into an independent LoRA adapter, forming a modular memory bank that enables explicit memory selection. Given a query, our framework retrieves candidate memories, routes the query to the most suitable adapter, and uses a Self-Gating mechanism to decide whether latent memory should be activated. To improve efficiency, we further introduce cache sharing to reduce management overhead during inference. Experiments show that our method substantially outperforms baselines with retrieval, while Self-Gating improves robustness by deactivate unnecessary latent memories.
ELoG-GS: Dual-Branch Gaussian Splatting with Luminance-Guided Enhancement for Extreme Low-light 3D Reconstruction
Apr 14, 2026This paper presents our approach to the NTIRE 2026 3D Restoration and Reconstruction Challenge (Track 1), which focuses on reconstructing high-quality 3D representations from degraded multi-view inputs. The challenge involves recovering geometrically consistent and photorealistic 3D scenes in extreme low-light environments. To address this task, we propose Extreme Low-light Optimized Gaussian Splatting (ELoG-GS), a robust low-light 3D reconstruction pipeline that integrates learning-based point cloud initialization and luminance-guided color enhancement for stable and photorealistic Gaussian Splatting. Our method incorporates both geometry-aware initialization and photometric adaptation strategies to improve reconstruction fidelity under challenging conditions. Extensive experiments on the NTIRE Track 1 benchmark demonstrate that our approach significantly improves reconstruction quality over the baselines, achieving superior visual fidelity and geometric consistency. The proposed method provides a practical solution for robust 3D reconstruction in real-world degraded scenarios. In the final testing phase, our method achieved a PSNR of 18.6626 and an SSIM of 0.6855 on the official platform leaderboard. Code is available at https://github.com/lyh120/FSGS_EAPGS.
Information-Theoretic Optimization for Task-Adapted Compressed Sensing Magnetic Resonance Imaging
Apr 14, 2026Task-adapted compressed sensing magnetic resonance imaging (CS-MRI) is emerging to address the specific demands of downstream clinical tasks with significantly fewer k-space measurements than required by Nyquist sampling. However, existing task-adapted CS-MRI methods suffer from the uncertainty problem for medical diagnosis and cannot achieve adaptive sampling in end-to-end optimization with reconstruction or clinical tasks. To address these limitations, we propose the first task-adapted CS-MRI from the information-theoretic perspective to simultaneously achieve probabilistic inference for uncertainty prediction and adapt to arbitrary sampling ratios and versatile clinical applications. Specifically, we formalize the task-adapted CS-MRI optimization problem by maximizing the mutual information between undersampled k-space measurements and clinical tasks to enable probabilistic inference for addressing the uncertainty problem. We leverage amortized optimization and construct tractable variational bounds for mutual information to jointly optimize sampling, reconstruction, and task-inference models, which enables flexible sampling ratio control using a single end-to-end trained model. Furthermore, the proposed framework addresses two kinds of distinct clinical scenarios within a unified approach, i.e., i) joint task and reconstruction, where reconstruction serves as an auxiliary process to enhance task performance; and ii) task implementation with suppressed reconstruction, applicable for privacy protection. Extensive experiments on large-scale MRI datasets demonstrate that the proposed framework achieves highly competitive performance on standard metrics like Dice compared to deterministic counterpart but provides better distribution matching to the ground-truth posterior distribution as measured by the generalized energy distance (GED).
NTIRE 2026 3D Restoration and Reconstruction in Real-world Adverse Conditions: RealX3D Challenge Results
Apr 05, 2026This paper presents a comprehensive review of the NTIRE 2026 3D Restoration and Reconstruction (3DRR) Challenge, detailing the proposed methods and results. The challenge seeks to identify robust reconstruction pipelines that are robust under real-world adverse conditions, specifically extreme low-light and smoke-degraded environments, as captured by our RealX3D benchmark. A total of 279 participants registered for the competition, of whom 33 teams submitted valid results. We thoroughly evaluate the submitted approaches against state-of-the-art baselines, revealing significant progress in 3D reconstruction under adverse conditions. Our analysis highlights shared design principles among top-performing methods and provides insights into effective strategies for handling 3D scene degradation.
Towards Holistic Modeling for Video Frame Interpolation with Auto-regressive Diffusion Transformers
Jan 21, 2026Existing video frame interpolation (VFI) methods often adopt a frame-centric approach, processing videos as independent short segments (e.g., triplets), which leads to temporal inconsistencies and motion artifacts. To overcome this, we propose a holistic, video-centric paradigm named \textbf{L}ocal \textbf{D}iffusion \textbf{F}orcing for \textbf{V}ideo \textbf{F}rame \textbf{I}nterpolation (LDF-VFI). Our framework is built upon an auto-regressive diffusion transformer that models the entire video sequence to ensure long-range temporal coherence. To mitigate error accumulation inherent in auto-regressive generation, we introduce a novel skip-concatenate sampling strategy that effectively maintains temporal stability. Furthermore, LDF-VFI incorporates sparse, local attention and tiled VAE encoding, a combination that not only enables efficient processing of long sequences but also allows generalization to arbitrary spatial resolutions (e.g., 4K) at inference without retraining. An enhanced conditional VAE decoder, which leverages multi-scale features from the input video, further improves reconstruction fidelity. Empirically, LDF-VFI achieves state-of-the-art performance on challenging long-sequence benchmarks, demonstrating superior per-frame quality and temporal consistency, especially in scenes with large motion. The source code is available at https://github.com/xypeng9903/LDF-VFI.
DynamicRTL: RTL Representation Learning for Dynamic Circuit Behavior
Nov 12, 2025



There is a growing body of work on using Graph Neural Networks (GNNs) to learn representations of circuits, focusing primarily on their static characteristics. However, these models fail to capture circuit runtime behavior, which is crucial for tasks like circuit verification and optimization. To address this limitation, we introduce DR-GNN (DynamicRTL-GNN), a novel approach that learns RTL circuit representations by incorporating both static structures and multi-cycle execution behaviors. DR-GNN leverages an operator-level Control Data Flow Graph (CDFG) to represent Register Transfer Level (RTL) circuits, enabling the model to capture dynamic dependencies and runtime execution. To train and evaluate DR-GNN, we build the first comprehensive dynamic circuit dataset, comprising over 6,300 Verilog designs and 63,000 simulation traces. Our results demonstrate that DR-GNN outperforms existing models in branch hit prediction and toggle rate prediction. Furthermore, its learned representations transfer effectively to related dynamic circuit tasks, achieving strong performance in power estimation and assertion prediction.
CMPhysBench: A Benchmark for Evaluating Large Language Models in Condensed Matter Physics
Aug 25, 2025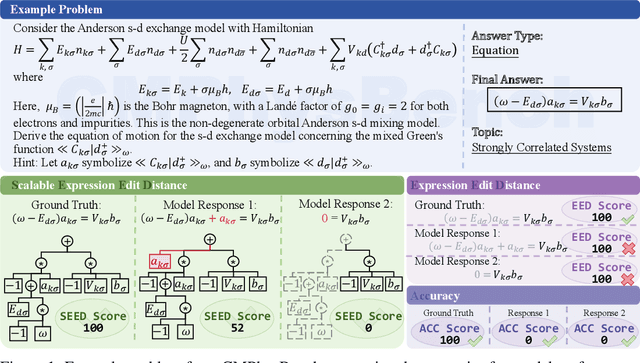
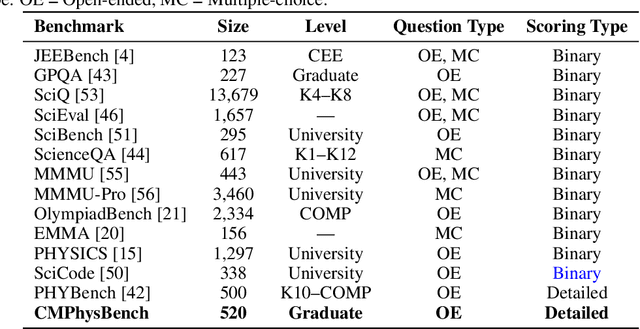
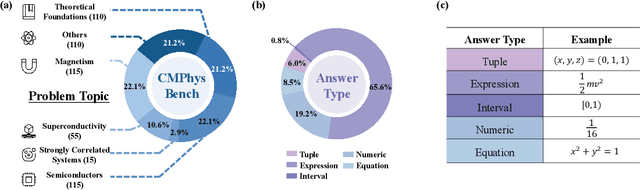

We introduce CMPhysBench, designed to assess the proficiency of Large Language Models (LLMs) in Condensed Matter Physics, as a novel Benchmark. CMPhysBench is composed of more than 520 graduate-level meticulously curated questions covering both representative subfields and foundational theoretical frameworks of condensed matter physics, such as magnetism, superconductivity, strongly correlated systems, etc. To ensure a deep understanding of the problem-solving process,we focus exclusively on calculation problems, requiring LLMs to independently generate comprehensive solutions. Meanwhile, leveraging tree-based representations of expressions, we introduce the Scalable Expression Edit Distance (SEED) score, which provides fine-grained (non-binary) partial credit and yields a more accurate assessment of similarity between prediction and ground-truth. Our results show that even the best models, Grok-4, reach only 36 average SEED score and 28% accuracy on CMPhysBench, underscoring a significant capability gap, especially for this practical and frontier domain relative to traditional physics. The code anddataset are publicly available at https://github.com/CMPhysBench/CMPhysBench.
3DGabSplat: 3D Gabor Splatting for Frequency-adaptive Radiance Field Rendering
Aug 07, 2025Recent prominence in 3D Gaussian Splatting (3DGS) has enabled real-time rendering while maintaining high-fidelity novel view synthesis. However, 3DGS resorts to the Gaussian function that is low-pass by nature and is restricted in representing high-frequency details in 3D scenes. Moreover, it causes redundant primitives with degraded training and rendering efficiency and excessive memory overhead. To overcome these limitations, we propose 3D Gabor Splatting (3DGabSplat) that leverages a novel 3D Gabor-based primitive with multiple directional 3D frequency responses for radiance field representation supervised by multi-view images. The proposed 3D Gabor-based primitive forms a filter bank incorporating multiple 3D Gabor kernels at different frequencies to enhance flexibility and efficiency in capturing fine 3D details. Furthermore, to achieve novel view rendering, an efficient CUDA-based rasterizer is developed to project the multiple directional 3D frequency components characterized by 3D Gabor-based primitives onto the 2D image plane, and a frequency-adaptive mechanism is presented for adaptive joint optimization of primitives. 3DGabSplat is scalable to be a plug-and-play kernel for seamless integration into existing 3DGS paradigms to enhance both efficiency and quality of novel view synthesis. Extensive experiments demonstrate that 3DGabSplat outperforms 3DGS and its variants using alternative primitives, and achieves state-of-the-art rendering quality across both real-world and synthetic scenes. Remarkably, we achieve up to 1.35 dB PSNR gain over 3DGS with simultaneously reduced number of primitives and memory consumption.
Circuit-Aware SAT Solving: Guiding CDCL via Conditional Probabilities
Aug 06, 2025



Circuit Satisfiability (CSAT) plays a pivotal role in Electronic Design Automation. The standard workflow for solving CSAT problems converts circuits into Conjunctive Normal Form (CNF) and employs generic SAT solvers powered by Conflict-Driven Clause Learning (CDCL). However, this process inherently discards rich structural and functional information, leading to suboptimal solver performance. To address this limitation, we introduce CASCAD, a novel circuit-aware SAT solving framework that directly leverages circuit-level conditional probabilities computed via Graph Neural Networks (GNNs). By explicitly modeling gate-level conditional probabilities, CASCAD dynamically guides two critical CDCL heuristics -- variable phase selection and clause managementto significantly enhance solver efficiency. Extensive evaluations on challenging real-world Logical Equivalence Checking (LEC) benchmarks demonstrate that CASCAD reduces solving times by up to 10x compared to state-of-the-art CNF-based approaches, achieving an additional 23.5% runtime reduction via our probability-guided clause filtering strategy. Our results underscore the importance of preserving circuit-level structural insights within SAT solvers, providing a robust foundation for future improvements in SAT-solving efficiency and EDA tool design.
Noise Conditional Variational Score Distillation
Jun 11, 2025



We propose Noise Conditional Variational Score Distillation (NCVSD), a novel method for distilling pretrained diffusion models into generative denoisers. We achieve this by revealing that the unconditional score function implicitly characterizes the score function of denoising posterior distributions. By integrating this insight into the Variational Score Distillation (VSD) framework, we enable scalable learning of generative denoisers capable of approximating samples from the denoising posterior distribution across a wide range of noise levels. The proposed generative denoisers exhibit desirable properties that allow fast generation while preserve the benefit of iterative refinement: (1) fast one-step generation through sampling from pure Gaussian noise at high noise levels; (2) improved sample quality by scaling the test-time compute with multi-step sampling; and (3) zero-shot probabilistic inference for flexible and controllable sampling. We evaluate NCVSD through extensive experiments, including class-conditional image generation and inverse problem solving. By scaling the test-time compute, our method outperforms teacher diffusion models and is on par with consistency models of larger sizes. Additionally, with significantly fewer NFEs than diffusion-based methods, we achieve record-breaking LPIPS on inverse problems.