 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA H.265/HEVC Fine-Grained ROI Video Encryption Algorithm Based on Coding Unit and Prompt Segmentation
Apr 09, 2026ROI (Region of Interest) video selective encryption based on H.265/HEVC is a technology that protects the sensitive regions of videos by perturbing the syntax elements associated with target areas. However, existing methods typically adopt Tile (with a relatively large size) as the minimum encryption unit, which suffers from problems such as inaccurate encryption regions and low encryption precision. This low-precision encryption makes them difficult to apply in sensitive fields such as medicine, military, and remote sensing. In order to address the aforementioned problem, this paper proposes a fine-grained ROI video selective encryption algorithm based on Coding Units (CUs) and prompt segmentation. First, to achieve a more precise ROI acquisition, we present a novel ROI mapping approach based on prompt segmentation. This approach enables precise mapping of ROIs to small $8\times8$ CU levels, significantly enhancing the precision of encrypted regions. Second, we propose a selective encryption scheme based on multiple syntax elements, which distorts syntax elements within high-precision ROI to effectively safeguard ROI security. Finally, we design a diffusion isolation based on Pulse Code Modulation (PCM) mode and MV restriction, applying PCM mode and MV restriction strategy to the affected CU to address encryption diffusion during prediction. The above three strategies break the inherent mechanism of using Tiles in existing ROI encryption and push the fine-grained level of ROI video encryption to the minimum $8\times8$ CU precision. The experimental results demonstrate that the proposed algorithm can accurately segment ROI regions, effectively perturb pixels within these regions, and eliminate the diffusion artifacts introduced by encryption. The method exhibits great potential for application in medical imaging, military surveillance, and remote areas.
H.265/HEVC Video Steganalysis Based on CU Block Structure Gradients and IPM Mapping
Feb 12, 2026Existing H.265/HEVC video steganalysis research mainly focuses on statistical feature modeling at the levels of motion vectors (MV), intra prediction modes (IPM), or transform coefficients. In contrast, studies targeting the coding-structure level - especially the analysis of block-level steganographic behaviors in Coding Units (CUs) - remain at an early stage. As a core component of H.265/HEVC coding decisions, the CU partition structure often exhibits steganographic perturbations in the form of structural changes and reorganization of prediction relationships, which are difficult to characterize effectively using traditional pixel-domain features or mode statistics. To address this issue, this paper, for the first time from the perspective of CU block-level steganalysis, proposes an H.265/HEVC video steganalysis method based on CU block-structure gradients and intra prediction mode mapping. The proposed method constructs a CU block-structure gradient map to explicitly describe changes in coding-unit partitioning, and combines it with a block-level mapping representation of IPM to jointly model the structural perturbations introduced by CU-level steganographic embedding. On this basis, we design a Transformer network, GradIPMFormer, tailored for CU-block steganalysis, thereby effectively enhancing the capability to perceive CU-level steganographic behaviors. Experimental results show that under different quantization parameters and resolution settings, the proposed method consistently achieves superior detection performance across multiple H.265/HEVC steganographic algorithms, validating the feasibility and effectiveness of conducting video steganalysis from the coding-structure perspective. This study provides a new CU block-level analysis paradigm for H.265/HEVC video steganalysis and has significant research value for covert communication security detection.
A Visual Perception-Based Tunable Framework and Evaluation Benchmark for H.265/HEVC ROI Encryption
Nov 09, 2025ROI selective encryption, as an efficient privacy protection technique, encrypts only the key regions in the video, thereby ensuring security while minimizing the impact on coding efficiency. However, existing ROI-based video encryption methods suffer from insufficient flexibility and lack of a unified evaluation system. To address these issues, we propose a visual perception-based tunable framework and evaluation benchmark for H.265/HEVC ROI encryption. Our scheme introduces three key contributions: 1) A ROI region recognition module based on visual perception network is proposed to accurately identify the ROI region in videos. 2) A three-level tunable encryption strategy is implemented while balancing security and real-time performance. 3) A unified ROI encryption evaluation benchmark is developed to provide a standardized quantitative platform for subsequent research. This triple strategy provides new solution and significant unified performance evaluation methods for ROI selective encryption field. Experimental results indicate that the proposed benchmark can comprehensively measure the performance of the ROI selective encryption. Compared to existing ROI encryption algorithms, our proposed enhanced and advanced level encryption exhibit superior performance in multiple performance metrics. In general, the proposed framework effectively meets the privacy protection requirements in H.265/HEVC and provides a reliable solution for secure and efficient processing of sensitive video content.
MUSE: Multi-Subject Unified Synthesis via Explicit Layout Semantic Expansion
Aug 20, 2025Existing text-to-image diffusion models have demonstrated remarkable capabilities in generating high-quality images guided by textual prompts. However, achieving multi-subject compositional synthesis with precise spatial control remains a significant challenge. In this work, we address the task of layout-controllable multi-subject synthesis (LMS), which requires both faithful reconstruction of reference subjects and their accurate placement in specified regions within a unified image. While recent advancements have separately improved layout control and subject synthesis, existing approaches struggle to simultaneously satisfy the dual requirements of spatial precision and identity preservation in this composite task. To bridge this gap, we propose MUSE, a unified synthesis framework that employs concatenated cross-attention (CCA) to seamlessly integrate layout specifications with textual guidance through explicit semantic space expansion. The proposed CCA mechanism enables bidirectional modality alignment between spatial constraints and textual descriptions without interference. Furthermore, we design a progressive two-stage training strategy that decomposes the LMS task into learnable sub-objectives for effective optimization. Extensive experiments demonstrate that MUSE achieves zero-shot end-to-end generation with superior spatial accuracy and identity consistency compared to existing solutions, advancing the frontier of controllable image synthesis. Our code and model are available at https://github.com/pf0607/MUSE.
Data-Efficient Pretraining with Group-Level Data Influence Modeling
Feb 20, 2025



Data-efficient pretraining has shown tremendous potential to elevate scaling laws. This paper argues that effective pretraining data should be curated at the group level, treating a set of data points as a whole rather than as independent contributors. To achieve that, we propose Group-Level Data Influence Modeling (Group-MATES), a novel data-efficient pretraining method that captures and optimizes group-level data utility. Specifically, Group-MATES collects oracle group-level influences by locally probing the pretraining model with data sets. It then fine-tunes a relational data influence model to approximate oracles as relationship-weighted aggregations of individual influences. The fine-tuned model selects the data subset by maximizing its group-level influence prediction, with influence-aware clustering to enable efficient inference. Experiments on the DCLM benchmark demonstrate that Group-MATES achieves a 10% relative core score improvement on 22 downstream tasks over DCLM-Baseline and 5% over individual-influence-based methods, establishing a new state-of-the-art. Further analyses highlight the effectiveness of relational data influence models in capturing intricate interactions between data points.
A New Teacher-Reviewer-Student Framework for Semi-supervised 2D Human Pose Estimation
Jan 16, 2025



Conventional 2D human pose estimation methods typically require extensive labeled annotations, which are both labor-intensive and expensive. In contrast, semi-supervised 2D human pose estimation can alleviate the above problems by leveraging a large amount of unlabeled data along with a small portion of labeled data. Existing semi-supervised 2D human pose estimation methods update the network through backpropagation, ignoring crucial historical information from the previous training process. Therefore, we propose a novel semi-supervised 2D human pose estimation method by utilizing a newly designed Teacher-Reviewer-Student framework. Specifically, we first mimic the phenomenon that human beings constantly review previous knowledge for consolidation to design our framework, in which the teacher predicts results to guide the student's learning and the reviewer stores important historical parameters to provide additional supervision signals. Secondly, we introduce a Multi-level Feature Learning strategy, which utilizes the outputs from different stages of the backbone to estimate the heatmap to guide network training, enriching the supervisory information while effectively capturing keypoint relationships. Finally, we design a data augmentation strategy, i.e., Keypoint-Mix, to perturb pose information by mixing different keypoints, thus enhancing the network's ability to discern keypoints. Extensive experiments on publicly available datasets, demonstrate our method achieves significant improvements compared to the existing methods.
Semi-Supervised Teacher-Reference-Student Architecture for Action Quality Assessment
Jul 29, 2024



Existing action quality assessment (AQA) methods often require a large number of label annotations for fully supervised learning, which are laborious and expensive. In practice, the labeled data are difficult to obtain because the AQA annotation process requires domain-specific expertise. In this paper, we propose a novel semi-supervised method, which can be utilized for better assessment of the AQA task by exploiting a large amount of unlabeled data and a small portion of labeled data. Differing from the traditional teacher-student network, we propose a teacher-reference-student architecture to learn both unlabeled and labeled data, where the teacher network and the reference network are used to generate pseudo-labels for unlabeled data to supervise the student network. Specifically, the teacher predicts pseudo-labels by capturing high-level features of unlabeled data. The reference network provides adequate supervision of the student network by referring to additional action information. Moreover, we introduce confidence memory to improve the reliability of pseudo-labels by storing the most accurate ever output of the teacher network and reference network. To validate our method, we conduct extensive experiments on three AQA benchmark datasets. Experimental results show that our method achieves significant improvements and outperforms existing semi-supervised AQA methods.
FD-GAN: Face-demorphing generative adversarial network for restoring accomplice's facial image
Nov 19, 2018
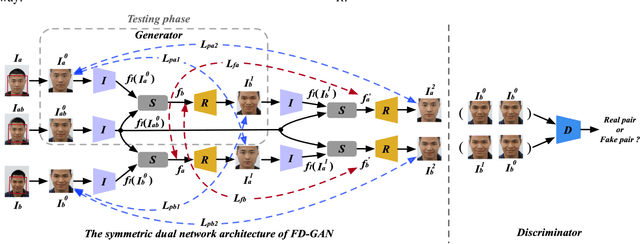
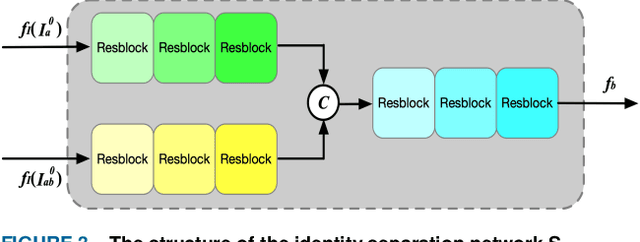

Face morphing attack is proved to be a serious threat to the existing face recognition systems. Although a few face morphing detection methods have been put forward, the face morphing accomplice's facial restoration remains a challenging problem. In this paper, a face-demorphing generative adversarial network (FD-GAN) is proposed to restore the accomplice's facial image. It utilizes a symmetric dual network architecture and two levels of restoration losses to separate the identity feature of the morphing accomplice. By exploiting the captured face image (containing the criminal's identity) from the face recognition system and the morphed image stored in the e-passport system (containing both criminal and accomplice's identities), the FD-GAN can effectively restore the accomplice's facial image. Experimental results and analysis demonstrate the effectiveness of the proposed scheme. It has great potential to be implemented for detecting the face morphing accomplice in a real identity verification scenario.