 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Guided Image Tokenization for Generation
Dec 08, 2024



Image tokenization, the process of transforming raw image pixels into a compact low-dimensional latent representation, has proven crucial for scalable and efficient image generation. However, mainstream image tokenization methods generally have limited compression rates, making high-resolution image generation computationally expensive. To address this challenge, we propose to leverage language for efficient image tokenization, and we call our method Text-Conditioned Image Tokenization (TexTok). TexTok is a simple yet effective tokenization framework that leverages language to provide high-level semantics. By conditioning the tokenization process on descriptive text captions, TexTok allows the tokenization process to focus on encoding fine-grained visual details into latent tokens, leading to enhanced reconstruction quality and higher compression rates. Compared to the conventional tokenizer without text conditioning, TexTok achieves average reconstruction FID improvements of 29.2% and 48.1% on ImageNet-256 and -512 benchmarks respectively, across varying numbers of tokens. These tokenization improvements consistently translate to 16.3% and 34.3% average improvements in generation FID. By simply replacing the tokenizer in Diffusion Transformer (DiT) with TexTok, our system can achieve a 93.5x inference speedup while still outperforming the original DiT using only 32 tokens on ImageNet-512. TexTok with a vanilla DiT generator achieves state-of-the-art FID scores of 1.46 and 1.62 on ImageNet-256 and -512 respectively. Furthermore, we demonstrate TexTok's superiority on the text-to-image generation task, effectively utilizing the off-the-shelf text captions in tokenization.
SceneCraft: An LLM Agent for Synthesizing 3D Scene as Blender Code
Mar 02, 2024



This paper introduces SceneCraft, a Large Language Model (LLM) Agent converting text descriptions into Blender-executable Python scripts which render complex scenes with up to a hundred 3D assets. This process requires complex spatial planning and arrangement. We tackle these challenges through a combination of advanced abstraction, strategic planning, and library learning. SceneCraft first models a scene graph as a blueprint, detailing the spatial relationships among assets in the scene. SceneCraft then writes Python scripts based on this graph, translating relationships into numerical constraints for asset layout. Next, SceneCraft leverages the perceptual strengths of vision-language foundation models like GPT-V to analyze rendered images and iteratively refine the scene. On top of this process, SceneCraft features a library learning mechanism that compiles common script functions into a reusable library, facilitating continuous self-improvement without expensive LLM parameter tuning. Our evaluation demonstrates that SceneCraft surpasses existing LLM-based agents in rendering complex scenes, as shown by its adherence to constraints and favorable human assessments. We also showcase the broader application potential of SceneCraft by reconstructing detailed 3D scenes from the Sintel movie and guiding a video generative model with generated scenes as intermediary control signal.
VideoPrism: A Foundational Visual Encoder for Video Understanding
Feb 20, 2024



We introduce VideoPrism, a general-purpose video encoder that tackles diverse video understanding tasks with a single frozen model. We pretrain VideoPrism on a heterogeneous corpus containing 36M high-quality video-caption pairs and 582M video clips with noisy parallel text (e.g., ASR transcripts). The pretraining approach improves upon masked autoencoding by global-local distillation of semantic video embeddings and a token shuffling scheme, enabling VideoPrism to focus primarily on the video modality while leveraging the invaluable text associated with videos. We extensively test VideoPrism on four broad groups of video understanding tasks, from web video question answering to CV for science, achieving state-of-the-art performance on 30 out of 33 video understanding benchmarks.
Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation
Oct 09, 2023While Large Language Models (LLMs) are the dominant models for generative tasks in language, they do not perform as well as diffusion models on image and video generation. To effectively use LLMs for visual generation, one crucial component is the visual tokenizer that maps pixel-space inputs to discrete tokens appropriate for LLM learning. In this paper, we introduce MAGVIT-v2, a video tokenizer designed to generate concise and expressive tokens for both videos and images using a common token vocabulary. Equipped with this new tokenizer, we show that LLMs outperform diffusion models on standard image and video generation benchmarks including ImageNet and Kinetics. In addition, we demonstrate that our tokenizer surpasses the previously top-performing video tokenizer on two more tasks: (1) video compression comparable to the next-generation video codec (VCC) according to human evaluations, and (2) learning effective representations for action recognition tasks.
SPAE: Semantic Pyramid AutoEncoder for Multimodal Generation with Frozen LLMs
Jul 03, 2023



In this work, we introduce Semantic Pyramid AutoEncoder (SPAE) for enabling frozen LLMs to perform both understanding and generation tasks involving non-linguistic modalities such as images or videos. SPAE converts between raw pixels and interpretable lexical tokens (or words) extracted from the LLM's vocabulary. The resulting tokens capture both the semantic meaning and the fine-grained details needed for visual reconstruction, effectively translating the visual content into a language comprehensible to the LLM, and empowering it to perform a wide array of multimodal tasks. Our approach is validated through in-context learning experiments with frozen PaLM 2 and GPT 3.5 on a diverse set of image understanding and generation tasks. Our method marks the first successful attempt to enable a frozen LLM to generate image content while surpassing state-of-the-art performance in image understanding tasks, under the same setting, by over 25%.
$IC^3$: Image Captioning by Committee Consensus
Feb 16, 2023



If you ask a human to describe an image, they might do so in a thousand different ways. Traditionally, image captioning models are trained to approximate the reference distribution of image captions, however, doing so encourages captions that are viewpoint-impoverished. Such captions often focus on only a subset of the possible details, while ignoring potentially useful information in the scene. In this work, we introduce a simple, yet novel, method: "Image Captioning by Committee Consensus" ($IC^3$), designed to generate a single caption that captures high-level details from several viewpoints. Notably, humans rate captions produced by $IC^3$ at least as helpful as baseline SOTA models more than two thirds of the time, and $IC^3$ captions can improve the performance of SOTA automated recall systems by up to 84%, indicating significant material improvements over existing SOTA approaches for visual description. Our code is publicly available at https://github.com/DavidMChan/caption-by-committee
Open-Vocabulary Temporal Action Detection with Off-the-Shelf Image-Text Features
Dec 20, 2022



Detecting actions in untrimmed videos should not be limited to a small, closed set of classes. We present a simple, yet effective strategy for open-vocabulary temporal action detection utilizing pretrained image-text co-embeddings. Despite being trained on static images rather than videos, we show that image-text co-embeddings enable openvocabulary performance competitive with fully-supervised models. We show that the performance can be further improved by ensembling the image-text features with features encoding local motion, like optical flow based features, or other modalities, like audio. In addition, we propose a more reasonable open-vocabulary evaluation setting for the ActivityNet data set, where the category splits are based on similarity rather than random assignment.
REVEAL: Retrieval-Augmented Visual-Language Pre-Training with Multi-Source Multimodal Knowledge Memory
Dec 10, 2022



In this paper, we propose an end-to-end Retrieval-Augmented Visual Language Model (REVEAL) that learns to encode world knowledge into a large-scale memory, and to retrieve from it to answer knowledge-intensive queries. REVEAL consists of four key components: the memory, the encoder, the retriever and the generator. The large-scale memory encodes various sources of multimodal world knowledge (e.g. image-text pairs, question answering pairs, knowledge graph triplets, etc) via a unified encoder. The retriever finds the most relevant knowledge entries in the memory, and the generator fuses the retrieved knowledge with the input query to produce the output. A key novelty in our approach is that the memory, encoder, retriever and generator are all pre-trained end-to-end on a massive amount of data. Furthermore, our approach can use a diverse set of multimodal knowledge sources, which is shown to result in significant gains. We show that REVEAL achieves state-of-the-art results on visual question answering and image captioning.
What's in a Caption? Dataset-Specific Linguistic Diversity and Its Effect on Visual Description Models and Metrics
May 12, 2022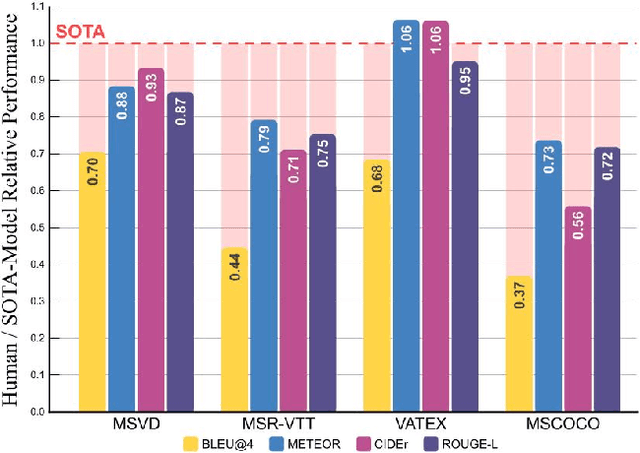
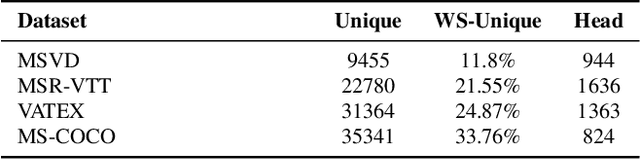
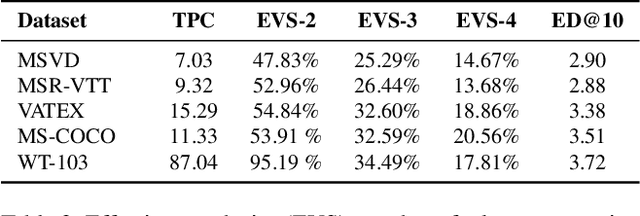
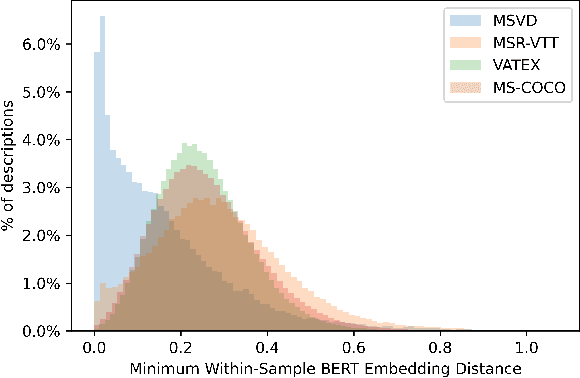
While there have been significant gains in the field of automated video description, the generalization performance of automated description models to novel domains remains a major barrier to using these systems in the real world. Most visual description methods are known to capture and exploit patterns in the training data leading to evaluation metric increases, but what are those patterns? In this work, we examine several popular visual description datasets, and capture, analyze, and understand the dataset-specific linguistic patterns that models exploit but do not generalize to new domains. At the token level, sample level, and dataset level, we find that caption diversity is a major driving factor behind the generation of generic and uninformative captions. We further show that state-of-the-art models even outperform held-out ground truth captions on modern metrics, and that this effect is an artifact of linguistic diversity in datasets. Understanding this linguistic diversity is key to building strong captioning models, we recommend several methods and approaches for maintaining diversity in the collection of new data, and dealing with the consequences of limited diversity when using current models and metrics.
Learn to Dance with AIST++: Music Conditioned 3D Dance Generation
Feb 02, 2021

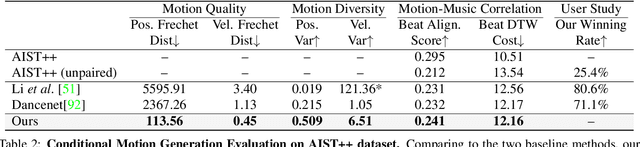

In this paper, we present a transformer-based learning framework for 3D dance generation conditioned on music. We carefully design our network architecture and empirically study the keys for obtaining qualitatively pleasing results. The critical components include a deep cross-modal transformer, which well learns the correlation between the music and dance motion; and the full-attention with future-N supervision mechanism which is essential in producing long-range non-freezing motion. In addition, we propose a new dataset of paired 3D motion and music called AIST++, which we reconstruct from the AIST multi-view dance videos. This dataset contains 1.1M frames of 3D dance motion in 1408 sequences, covering 10 genres of dance choreographies and accompanied with multi-view camera parameters. To our knowledge it is the largest dataset of this kind. Rich experiments on AIST++ demonstrate our method produces much better results than the state-of-the-art methods both qualitatively and quantitatively.