 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat's in a Caption? Dataset-Specific Linguistic Diversity and Its Effect on Visual Description Models and Metrics
May 12, 2022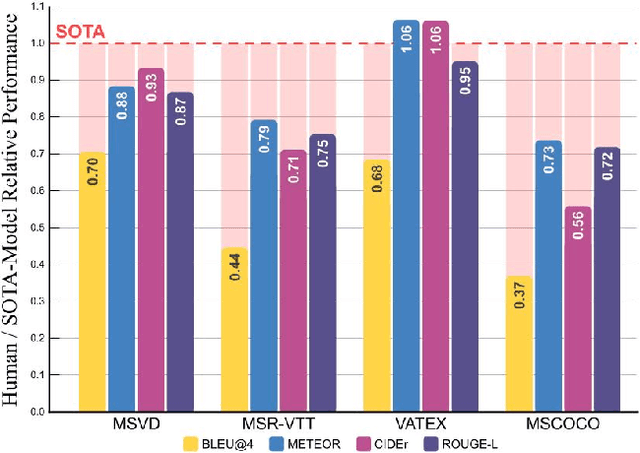
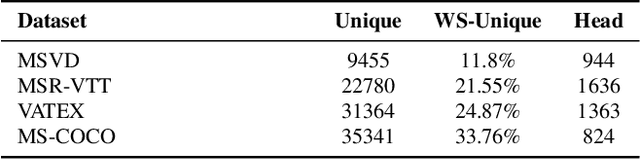
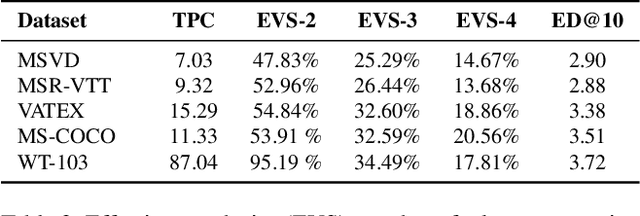
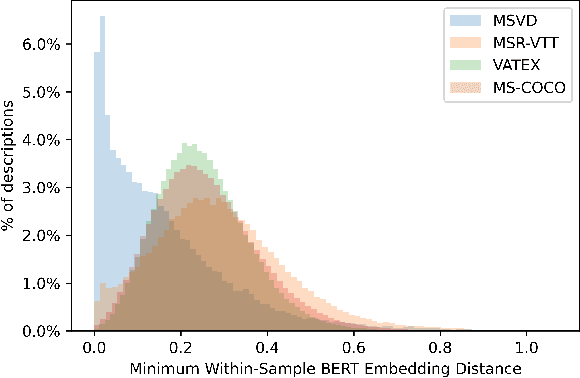
While there have been significant gains in the field of automated video description, the generalization performance of automated description models to novel domains remains a major barrier to using these systems in the real world. Most visual description methods are known to capture and exploit patterns in the training data leading to evaluation metric increases, but what are those patterns? In this work, we examine several popular visual description datasets, and capture, analyze, and understand the dataset-specific linguistic patterns that models exploit but do not generalize to new domains. At the token level, sample level, and dataset level, we find that caption diversity is a major driving factor behind the generation of generic and uninformative captions. We further show that state-of-the-art models even outperform held-out ground truth captions on modern metrics, and that this effect is an artifact of linguistic diversity in datasets. Understanding this linguistic diversity is key to building strong captioning models, we recommend several methods and approaches for maintaining diversity in the collection of new data, and dealing with the consequences of limited diversity when using current models and metrics.
Creating User Interface Mock-ups from High-Level Text Descriptions with Deep-Learning Models
Oct 14, 2021

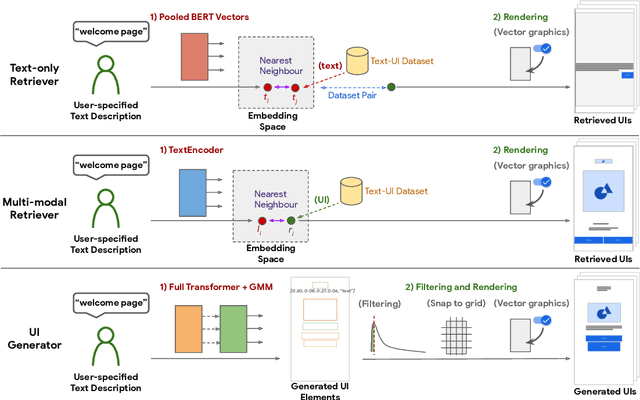
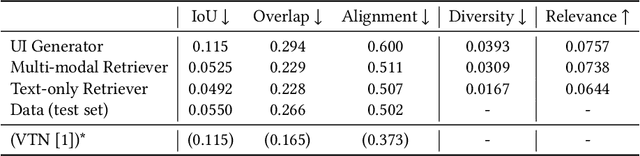
The design process of user interfaces (UIs) often begins with articulating high-level design goals. Translating these high-level design goals into concrete design mock-ups, however, requires extensive effort and UI design expertise. To facilitate this process for app designers and developers, we introduce three deep-learning techniques to create low-fidelity UI mock-ups from a natural language phrase that describes the high-level design goal (e.g. "pop up displaying an image and other options"). In particular, we contribute two retrieval-based methods and one generative method, as well as pre-processing and post-processing techniques to ensure the quality of the created UI mock-ups. We quantitatively and qualitatively compare and contrast each method's ability in suggesting coherent, diverse and relevant UI design mock-ups. We further evaluate these methods with 15 professional UI designers and practitioners to understand each method's advantages and disadvantages. The designers responded positively to the potential of these methods for assisting the design process.
Sketchforme: Composing Sketched Scenes from Text Descriptions for Interactive Applications
Apr 08, 2019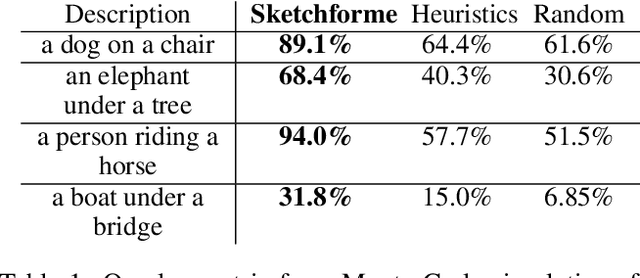
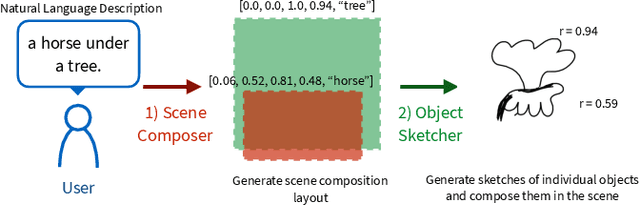
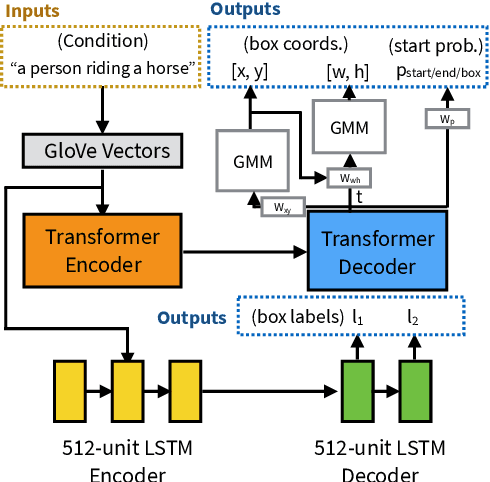
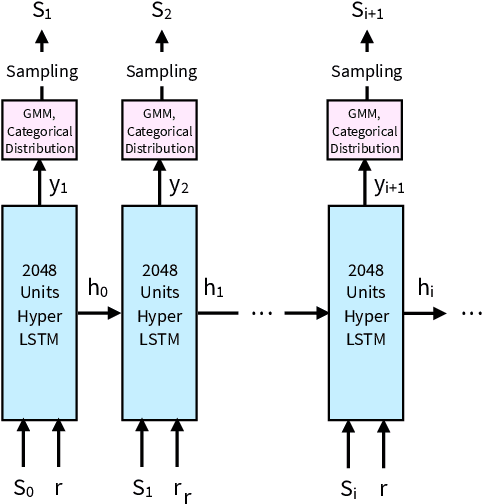
Sketching and natural languages are effective communication media for interactive applications. We introduce Sketchforme, the first neural-network-based system that can generate sketches based on text descriptions specified by users. Sketchforme is capable of gaining high-level and low-level understanding of multi-object sketched scenes without being trained on sketched scene datasets annotated with text descriptions. The sketches composed by Sketchforme are expressive and realistic: we show in our user study that these sketches convey descriptions better than human-generated sketches in multiple cases, and 36.5% of those sketches are considered to be human-generated. We develop multiple interactive applications using these generated sketches, and show that Sketchforme can significantly improve language learning applications and support intelligent language-based sketching assistants.
Diagnostic Visualization for Deep Neural Networks Using Stochastic Gradient Langevin Dynamics
Dec 11, 2018

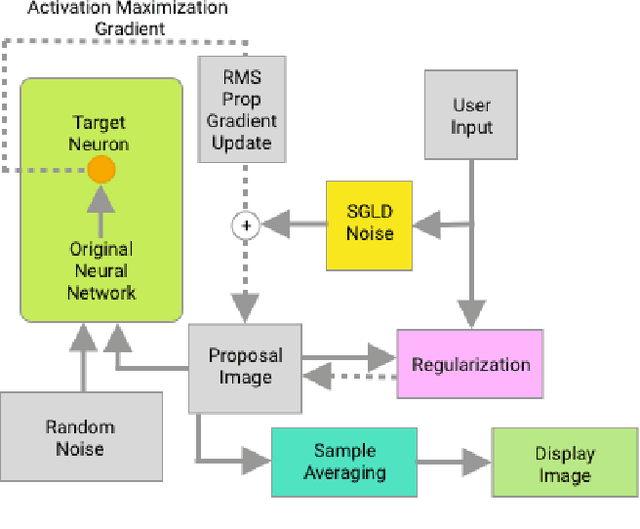

The internal states of most deep neural networks are difficult to interpret, which makes diagnosis and debugging during training challenging. Activation maximization methods are widely used, but lead to multiple optima and are hard to interpret (appear noise-like) for complex neurons. Image-based methods use maximally-activating image regions which are easier to interpret, but do not provide pixel-level insight into why the neuron responds to them. In this work we introduce an MCMC method: Langevin Dynamics Activation Maximization (LDAM), which is designed for diagnostic visualization. LDAM provides two affordances in combination: the ability to explore the set of maximally activating pre-images, and the ability to trade-off interpretability and pixel-level accuracy using a GAN-style discriminator as a regularizer. We present case studies on MNIST, CIFAR and ImageNet datasets exploring these trade-offs. Finally we show that diagnostic visualization using LDAM leads to a novel insight into the parameter averaging method for deep net training.
t-SNE-CUDA: GPU-Accelerated t-SNE and its Applications to Modern Data
Jul 31, 2018
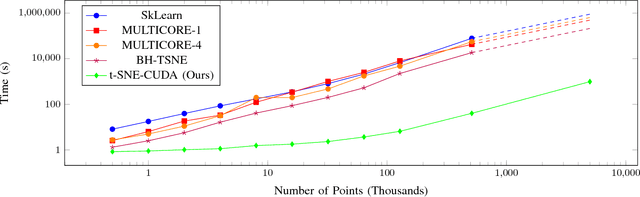
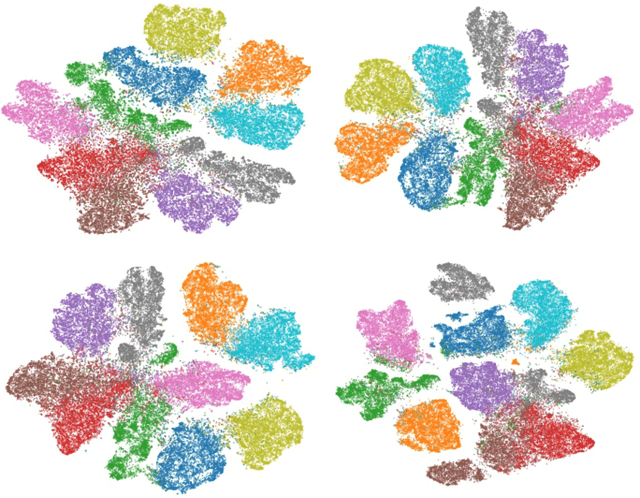

Modern datasets and models are notoriously difficult to explore and analyze due to their inherent high dimensionality and massive numbers of samples. Existing visualization methods which employ dimensionality reduction to two or three dimensions are often inefficient and/or ineffective for these datasets. This paper introduces t-SNE-CUDA, a GPU-accelerated implementation of t-distributed Symmetric Neighbor Embedding (t-SNE) for visualizing datasets and models. t-SNE-CUDA significantly outperforms current implementations with 50-700x speedups on the CIFAR-10 and MNIST datasets. These speedups enable, for the first time, visualization of the neural network activations on the entire ImageNet dataset - a feat that was previously computationally intractable. We also demonstrate visualization performance in the NLP domain by visualizing the GloVe embedding vectors. From these visualizations, we can draw interesting conclusions about using the L2 metric in these embedding spaces. t-SNE-CUDA is publicly available at https://github.com/CannyLab/tsne-cuda