 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSZTU-CMU at MER2024: Improving Emotion-LLaMA with Conv-Attention for Multimodal Emotion Recognition
Aug 21, 2024



This paper presents our winning approach for the MER-NOISE and MER-OV tracks of the MER2024 Challenge on multimodal emotion recognition. Our system leverages the advanced emotional understanding capabilities of Emotion-LLaMA to generate high-quality annotations for unlabeled samples, addressing the challenge of limited labeled data. To enhance multimodal fusion while mitigating modality-specific noise, we introduce Conv-Attention, a lightweight and efficient hybrid framework. Extensive experimentation vali-dates the effectiveness of our approach. In the MER-NOISE track, our system achieves a state-of-the-art weighted average F-score of 85.30%, surpassing the second and third-place teams by 1.47% and 1.65%, respectively. For the MER-OV track, our utilization of Emotion-LLaMA for open-vocabulary annotation yields an 8.52% improvement in average accuracy and recall compared to GPT-4V, securing the highest score among all participating large multimodal models. The code and model for Emotion-LLaMA are available at https://github.com/ZebangCheng/Emotion-LLaMA.
MetaDesigner: Advancing Artistic Typography through AI-Driven, User-Centric, and Multilingual WordArt Synthesis
Jun 28, 2024



MetaDesigner revolutionizes artistic typography synthesis by leveraging the strengths of Large Language Models (LLMs) to drive a design paradigm centered around user engagement. At the core of this framework lies a multi-agent system comprising the Pipeline, Glyph, and Texture agents, which collectively enable the creation of customized WordArt, ranging from semantic enhancements to the imposition of complex textures. MetaDesigner incorporates a comprehensive feedback mechanism that harnesses insights from multimodal models and user evaluations to refine and enhance the design process iteratively. Through this feedback loop, the system adeptly tunes hyperparameters to align with user-defined stylistic and thematic preferences, generating WordArt that not only meets but exceeds user expectations of visual appeal and contextual relevance. Empirical validations highlight MetaDesigner's capability to effectively serve diverse WordArt applications, consistently producing aesthetically appealing and context-sensitive results.
Human-Aware Vision-and-Language Navigation: Bridging Simulation to Reality with Dynamic Human Interactions
Jun 27, 2024



Vision-and-Language Navigation (VLN) aims to develop embodied agents that navigate based on human instructions. However, current VLN frameworks often rely on static environments and optimal expert supervision, limiting their real-world applicability. To address this, we introduce Human-Aware Vision-and-Language Navigation (HA-VLN), extending traditional VLN by incorporating dynamic human activities and relaxing key assumptions. We propose the Human-Aware 3D (HA3D) simulator, which combines dynamic human activities with the Matterport3D dataset, and the Human-Aware Room-to-Room (HA-R2R) dataset, extending R2R with human activity descriptions. To tackle HA-VLN challenges, we present the Expert-Supervised Cross-Modal (VLN-CM) and Non-Expert-Supervised Decision Transformer (VLN-DT) agents, utilizing cross-modal fusion and diverse training strategies for effective navigation in dynamic human environments. A comprehensive evaluation, including metrics considering human activities, and systematic analysis of HA-VLN's unique challenges, underscores the need for further research to enhance HA-VLN agents' real-world robustness and adaptability. Ultimately, this work provides benchmarks and insights for future research on embodied AI and Sim2Real transfer, paving the way for more realistic and applicable VLN systems in human-populated environments.
MM-TTS: A Unified Framework for Multimodal, Prompt-Induced Emotional Text-to-Speech Synthesis
Apr 29, 2024



Emotional Text-to-Speech (E-TTS) synthesis has gained significant attention in recent years due to its potential to enhance human-computer interaction. However, current E-TTS approaches often struggle to capture the complexity of human emotions, primarily relying on oversimplified emotional labels or single-modality inputs. To address these limitations, we propose the Multimodal Emotional Text-to-Speech System (MM-TTS), a unified framework that leverages emotional cues from multiple modalities to generate highly expressive and emotionally resonant speech. MM-TTS consists of two key components: (1) the Emotion Prompt Alignment Module (EP-Align), which employs contrastive learning to align emotional features across text, audio, and visual modalities, ensuring a coherent fusion of multimodal information; and (2) the Emotion Embedding-Induced TTS (EMI-TTS), which integrates the aligned emotional embeddings with state-of-the-art TTS models to synthesize speech that accurately reflects the intended emotions. Extensive evaluations across diverse datasets demonstrate the superior performance of MM-TTS compared to traditional E-TTS models. Objective metrics, including Word Error Rate (WER) and Character Error Rate (CER), show significant improvements on ESD dataset, with MM-TTS achieving scores of 7.35% and 3.07%, respectively. Subjective assessments further validate that MM-TTS generates speech with emotional fidelity and naturalness comparable to human speech. Our code and pre-trained models are publicly available at https://anonymous.4open.science/r/MMTTS-D214
Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation
Oct 09, 2023While Large Language Models (LLMs) are the dominant models for generative tasks in language, they do not perform as well as diffusion models on image and video generation. To effectively use LLMs for visual generation, one crucial component is the visual tokenizer that maps pixel-space inputs to discrete tokens appropriate for LLM learning. In this paper, we introduce MAGVIT-v2, a video tokenizer designed to generate concise and expressive tokens for both videos and images using a common token vocabulary. Equipped with this new tokenizer, we show that LLMs outperform diffusion models on standard image and video generation benchmarks including ImageNet and Kinetics. In addition, we demonstrate that our tokenizer surpasses the previously top-performing video tokenizer on two more tasks: (1) video compression comparable to the next-generation video codec (VCC) according to human evaluations, and (2) learning effective representations for action recognition tasks.
SPAE: Semantic Pyramid AutoEncoder for Multimodal Generation with Frozen LLMs
Jul 03, 2023



In this work, we introduce Semantic Pyramid AutoEncoder (SPAE) for enabling frozen LLMs to perform both understanding and generation tasks involving non-linguistic modalities such as images or videos. SPAE converts between raw pixels and interpretable lexical tokens (or words) extracted from the LLM's vocabulary. The resulting tokens capture both the semantic meaning and the fine-grained details needed for visual reconstruction, effectively translating the visual content into a language comprehensible to the LLM, and empowering it to perform a wide array of multimodal tasks. Our approach is validated through in-context learning experiments with frozen PaLM 2 and GPT 3.5 on a diverse set of image understanding and generation tasks. Our method marks the first successful attempt to enable a frozen LLM to generate image content while surpassing state-of-the-art performance in image understanding tasks, under the same setting, by over 25%.
Document Entity Retrieval with Massive and Noisy Pre-training
Jun 15, 2023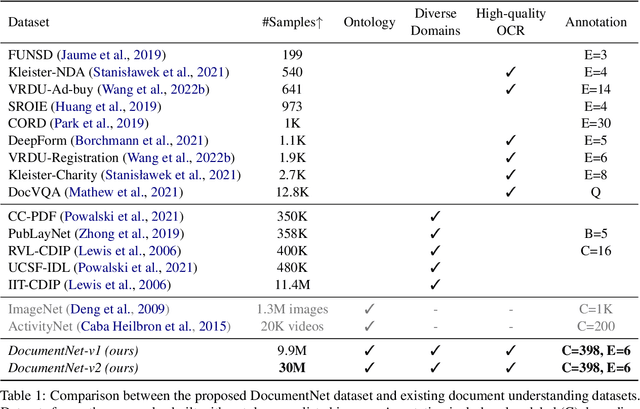

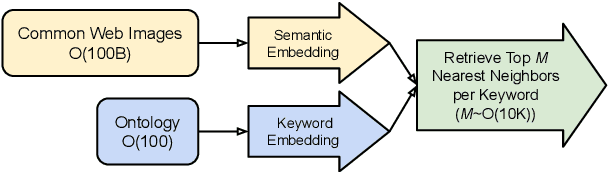

Visually-Rich Document Entity Retrieval (VDER) is a type of machine learning task that aims at recovering text spans in the documents for each of the entities in question. VDER has gained significant attention in recent years thanks to its broad applications in enterprise AI. Unfortunately, as document images often contain personally identifiable information (PII), publicly available data have been scarce, not only because of privacy constraints but also the costs of acquiring annotations. To make things worse, each dataset would often define its own sets of entities, and the non-overlapping entity spaces between datasets make it difficult to transfer knowledge between documents. In this paper, we propose a method to collect massive-scale, noisy, and weakly labeled data from the web to benefit the training of VDER models. Such a method will generate a huge amount of document image data to compensate for the lack of training data in many VDER settings. Moreover, the collected dataset named DocuNet would not need to be dependent on specific document types or entity sets, making it universally applicable to all VDER tasks. Empowered by DocuNet, we present a lightweight multimodal architecture named UniFormer, which can learn a unified representation from text, layout, and image crops without needing extra visual pertaining. We experiment with our methods on popular VDER models in various settings and show the improvements when this massive dataset is incorporated with UniFormer on both classic entity retrieval and few-shot learning settings.
ChartReader: A Unified Framework for Chart Derendering and Comprehension without Heuristic Rules
Apr 05, 2023



Charts are a powerful tool for visually conveying complex data, but their comprehension poses a challenge due to the diverse chart types and intricate components. Existing chart comprehension methods suffer from either heuristic rules or an over-reliance on OCR systems, resulting in suboptimal performance. To address these issues, we present ChartReader, a unified framework that seamlessly integrates chart derendering and comprehension tasks. Our approach includes a transformer-based chart component detection module and an extended pre-trained vision-language model for chart-to-X tasks. By learning the rules of charts automatically from annotated datasets, our approach eliminates the need for manual rule-making, reducing effort and enhancing accuracy.~We also introduce a data variable replacement technique and extend the input and position embeddings of the pre-trained model for cross-task training. We evaluate ChartReader on Chart-to-Table, ChartQA, and Chart-to-Text tasks, demonstrating its superiority over existing methods. Our proposed framework can significantly reduce the manual effort involved in chart analysis, providing a step towards a universal chart understanding model. Moreover, our approach offers opportunities for plug-and-play integration with mainstream LLMs such as T5 and TaPas, extending their capability to chart comprehension tasks. The code is available at https://github.com/zhiqic/ChartReader.
MAGVIT: Masked Generative Video Transformer
Dec 10, 2022



We introduce the MAsked Generative VIdeo Transformer, MAGVIT, to tackle various video synthesis tasks with a single model. We introduce a 3D tokenizer to quantize a video into spatial-temporal visual tokens and propose an embedding method for masked video token modeling to facilitate multi-task learning. We conduct extensive experiments to demonstrate the quality, efficiency, and flexibility of MAGVIT. Our experiments show that (i) MAGVIT performs favorably against state-of-the-art approaches and establishes the best-published FVD on three video generation benchmarks, including the challenging Kinetics-600. (ii) MAGVIT outperforms existing methods in inference time by two orders of magnitude against diffusion models and by 60x against autoregressive models. (iii) A single MAGVIT model supports ten diverse generation tasks and generalizes across videos from different visual domains. The source code and trained models will be released to the public at https://magvit.cs.cmu.edu.
Rethinking Spatial Invariance of Convolutional Networks for Object Counting
Jun 10, 2022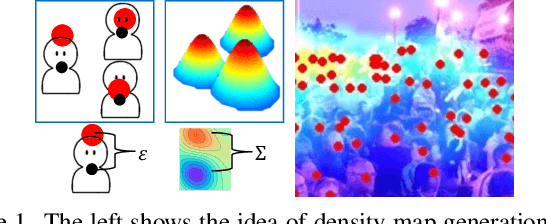
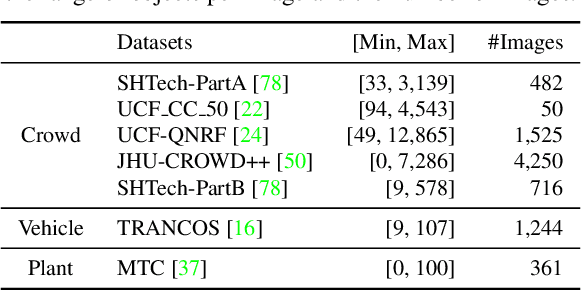
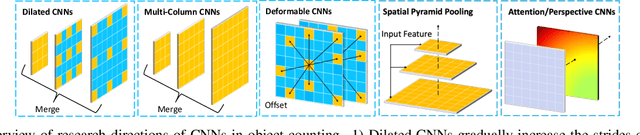
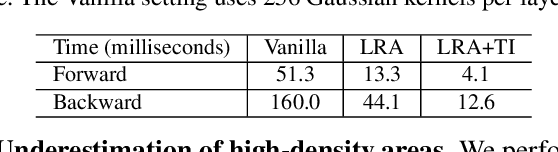
Previous work generally believes that improving the spatial invariance of convolutional networks is the key to object counting. However, after verifying several mainstream counting networks, we surprisingly found too strict pixel-level spatial invariance would cause overfit noise in the density map generation. In this paper, we try to use locally connected Gaussian kernels to replace the original convolution filter to estimate the spatial position in the density map. The purpose of this is to allow the feature extraction process to potentially stimulate the density map generation process to overcome the annotation noise. Inspired by previous work, we propose a low-rank approximation accompanied with translation invariance to favorably implement the approximation of massive Gaussian convolution. Our work points a new direction for follow-up research, which should investigate how to properly relax the overly strict pixel-level spatial invariance for object counting. We evaluate our methods on 4 mainstream object counting networks (i.e., MCNN, CSRNet, SANet, and ResNet-50). Extensive experiments were conducted on 7 popular benchmarks for 3 applications (i.e., crowd, vehicle, and plant counting). Experimental results show that our methods significantly outperform other state-of-the-art methods and achieve promising learning of the spatial position of objects.