 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample what you cant compress
Sep 04, 2024



For learned image representations, basic autoencoders often produce blurry results. Reconstruction quality can be improved by incorporating additional penalties such as adversarial (GAN) and perceptual losses. Arguably, these approaches lack a principled interpretation. Concurrently, in generative settings diffusion has demonstrated a remarkable ability to create crisp, high quality results and has solid theoretical underpinnings (from variational inference to direct study as the Fisher Divergence). Our work combines autoencoder representation learning with diffusion and is, to our knowledge, the first to demonstrate the efficacy of jointly learning a continuous encoder and decoder under a diffusion-based loss. We demonstrate that this approach yields better reconstruction quality as compared to GAN-based autoencoders while being easier to tune. We also show that the resulting representation is easier to model with a latent diffusion model as compared to the representation obtained from a state-of-the-art GAN-based loss. Since our decoder is stochastic, it can generate details not encoded in the otherwise deterministic latent representation; we therefore name our approach "Sample what you can't compress", or SWYCC for short.
VideoPoet: A Large Language Model for Zero-Shot Video Generation
Dec 21, 2023



We present VideoPoet, a language model capable of synthesizing high-quality video, with matching audio, from a large variety of conditioning signals. VideoPoet employs a decoder-only transformer architecture that processes multimodal inputs -- including images, videos, text, and audio. The training protocol follows that of Large Language Models (LLMs), consisting of two stages: pretraining and task-specific adaptation. During pretraining, VideoPoet incorporates a mixture of multimodal generative objectives within an autoregressive Transformer framework. The pretrained LLM serves as a foundation that can be adapted for a range of video generation tasks. We present empirical results demonstrating the model's state-of-the-art capabilities in zero-shot video generation, specifically highlighting VideoPoet's ability to generate high-fidelity motions. Project page: http://sites.research.google/videopoet/
Finite Scalar Quantization: VQ-VAE Made Simple
Oct 12, 2023



We propose to replace vector quantization (VQ) in the latent representation of VQ-VAEs with a simple scheme termed finite scalar quantization (FSQ), where we project the VAE representation down to a few dimensions (typically less than 10). Each dimension is quantized to a small set of fixed values, leading to an (implicit) codebook given by the product of these sets. By appropriately choosing the number of dimensions and values each dimension can take, we obtain the same codebook size as in VQ. On top of such discrete representations, we can train the same models that have been trained on VQ-VAE representations. For example, autoregressive and masked transformer models for image generation, multimodal generation, and dense prediction computer vision tasks. Concretely, we employ FSQ with MaskGIT for image generation, and with UViM for depth estimation, colorization, and panoptic segmentation. Despite the much simpler design of FSQ, we obtain competitive performance in all these tasks. We emphasize that FSQ does not suffer from codebook collapse and does not need the complex machinery employed in VQ (commitment losses, codebook reseeding, code splitting, entropy penalties, etc.) to learn expressive discrete representations.
Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation
Oct 09, 2023While Large Language Models (LLMs) are the dominant models for generative tasks in language, they do not perform as well as diffusion models on image and video generation. To effectively use LLMs for visual generation, one crucial component is the visual tokenizer that maps pixel-space inputs to discrete tokens appropriate for LLM learning. In this paper, we introduce MAGVIT-v2, a video tokenizer designed to generate concise and expressive tokens for both videos and images using a common token vocabulary. Equipped with this new tokenizer, we show that LLMs outperform diffusion models on standard image and video generation benchmarks including ImageNet and Kinetics. In addition, we demonstrate that our tokenizer surpasses the previously top-performing video tokenizer on two more tasks: (1) video compression comparable to the next-generation video codec (VCC) according to human evaluations, and (2) learning effective representations for action recognition tasks.
Multi-Realism Image Compression with a Conditional Generator
Dec 28, 2022



By optimizing the rate-distortion-realism trade-off, generative compression approaches produce detailed, realistic images, even at low bit rates, instead of the blurry reconstructions produced by rate-distortion optimized models. However, previous methods do not explicitly control how much detail is synthesized, which results in a common criticism of these methods: users might be worried that a misleading reconstruction far from the input image is generated. In this work, we alleviate these concerns by training a decoder that can bridge the two regimes and navigate the distortion-realism trade-off. From a single compressed representation, the receiver can decide to either reconstruct a low mean squared error reconstruction that is close to the input, a realistic reconstruction with high perceptual quality, or anything in between. With our method, we set a new state-of-the-art in distortion-realism, pushing the frontier of achievable distortion-realism pairs, i.e., our method achieves better distortions at high realism and better realism at low distortion than ever before.
VCT: A Video Compression Transformer
Jun 15, 2022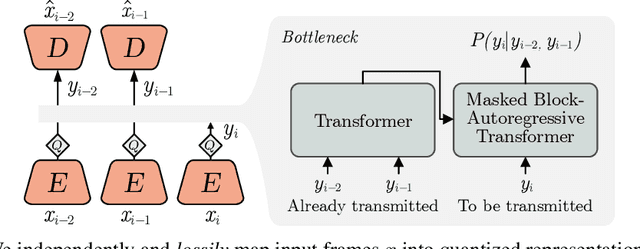

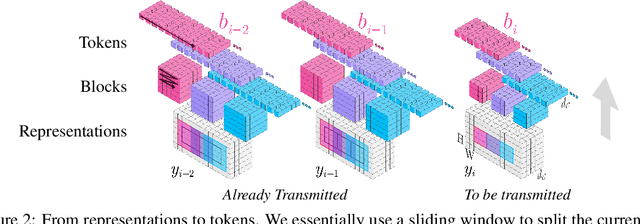
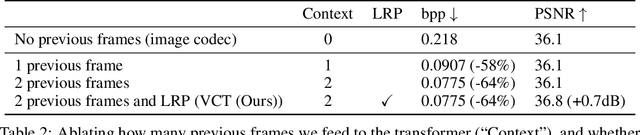
We show how transformers can be used to vastly simplify neural video compression. Previous methods have been relying on an increasing number of architectural biases and priors, including motion prediction and warping operations, resulting in complex models. Instead, we independently map input frames to representations and use a transformer to model their dependencies, letting it predict the distribution of future representations given the past. The resulting video compression transformer outperforms previous methods on standard video compression data sets. Experiments on synthetic data show that our model learns to handle complex motion patterns such as panning, blurring and fading purely from data. Our approach is easy to implement, and we release code to facilitate future research.
Towards Generative Video Compression
Jul 26, 2021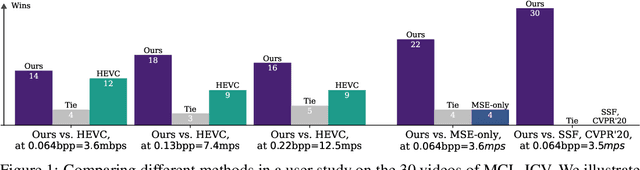
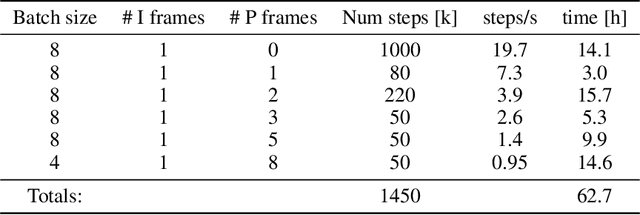
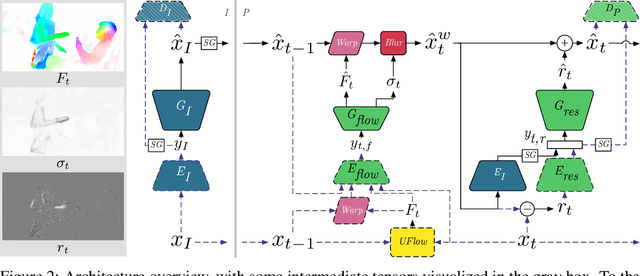
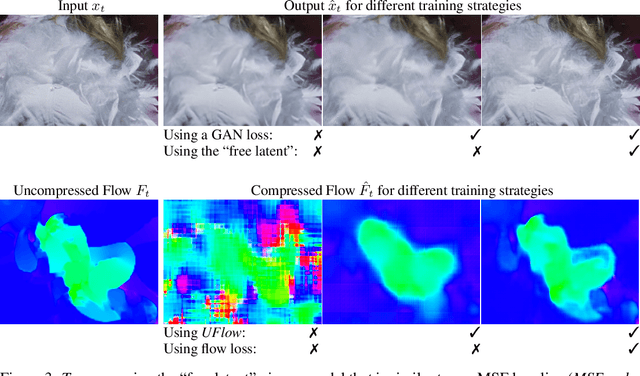
We present a neural video compression method based on generative adversarial networks (GANs) that outperforms previous neural video compression methods and is comparable to HEVC in a user study. We propose a technique to mitigate temporal error accumulation caused by recursive frame compression that uses randomized shifting and un-shifting, motivated by a spectral analysis. We present in detail the network design choices, their relative importance, and elaborate on the challenges of evaluating video compression methods in user studies.
Channel-wise Autoregressive Entropy Models for Learned Image Compression
Jul 17, 2020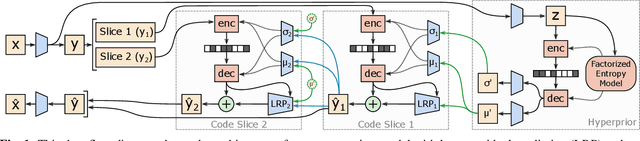

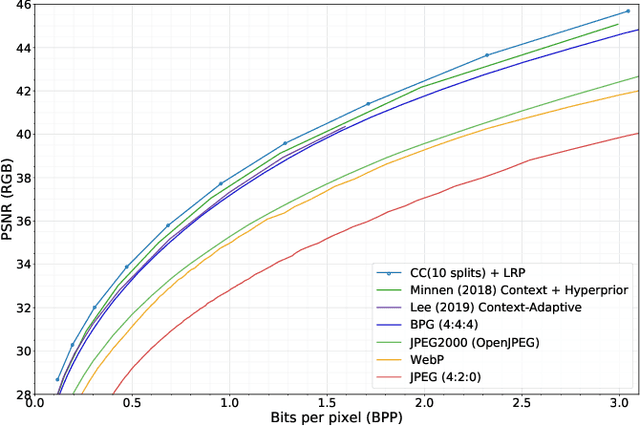
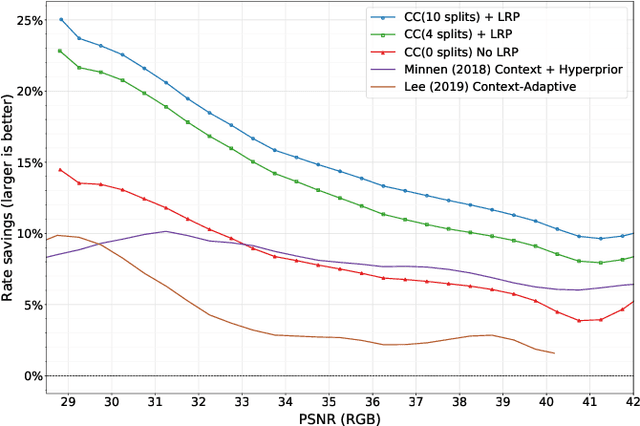
In learning-based approaches to image compression, codecs are developed by optimizing a computational model to minimize a rate-distortion objective. Currently, the most effective learned image codecs take the form of an entropy-constrained autoencoder with an entropy model that uses both forward and backward adaptation. Forward adaptation makes use of side information and can be efficiently integrated into a deep neural network. In contrast, backward adaptation typically makes predictions based on the causal context of each symbol, which requires serial processing that prevents efficient GPU / TPU utilization. We introduce two enhancements, channel-conditioning and latent residual prediction, that lead to network architectures with better rate-distortion performance than existing context-adaptive models while minimizing serial processing. Empirically, we see an average rate savings of 6.7% on the Kodak image set and 11.4% on the Tecnick image set compared to a context-adaptive baseline model. At low bit rates, where the improvements are most effective, our model saves up to 18% over the baseline and outperforms hand-engineered codecs like BPG by up to 25%.
Joint Autoregressive and Hierarchical Priors for Learned Image Compression
Sep 08, 2018

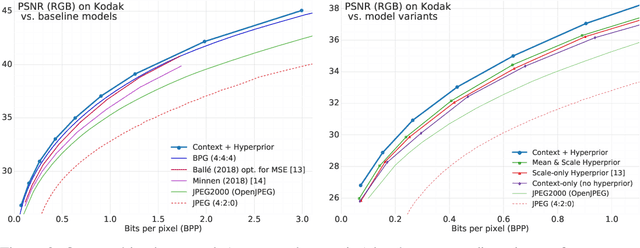
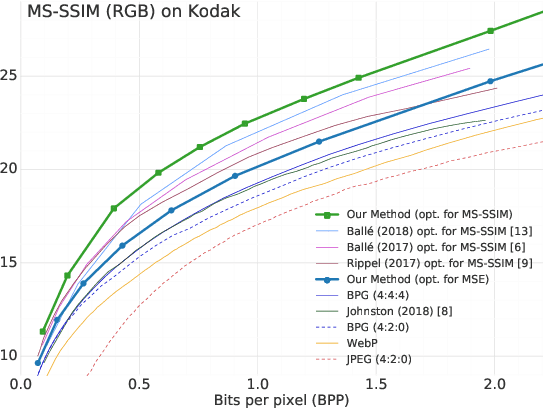
Recent models for learned image compression are based on autoencoders, learning approximately invertible mappings from pixels to a quantized latent representation. These are combined with an entropy model, a prior on the latent representation that can be used with standard arithmetic coding algorithms to yield a compressed bitstream. Recently, hierarchical entropy models have been introduced as a way to exploit more structure in the latents than simple fully factorized priors, improving compression performance while maintaining end-to-end optimization. Inspired by the success of autoregressive priors in probabilistic generative models, we examine autoregressive, hierarchical, as well as combined priors as alternatives, weighing their costs and benefits in the context of image compression. While it is well known that autoregressive models come with a significant computational penalty, we find that in terms of compression performance, autoregressive and hierarchical priors are complementary and, together, exploit the probabilistic structure in the latents better than all previous learned models. The combined model yields state-of-the-art rate--distortion performance, providing a 15.8% average reduction in file size over the previous state-of-the-art method based on deep learning, which corresponds to a 59.8% size reduction over JPEG, more than 35% reduction compared to WebP and JPEG2000, and bitstreams 8.4% smaller than BPG, the current state-of-the-art image codec. To the best of our knowledge, our model is the first learning-based method to outperform BPG on both PSNR and MS-SSIM distortion metrics.
Towards a Semantic Perceptual Image Metric
Aug 01, 2018
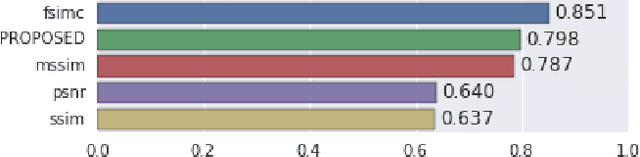
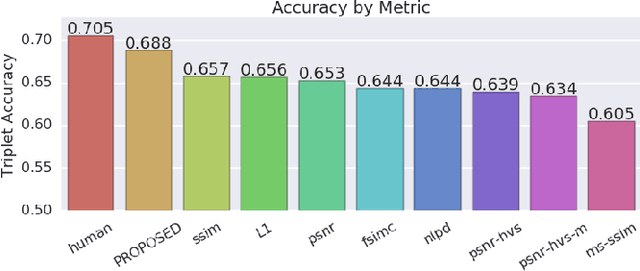

We present a full reference, perceptual image metric based on VGG-16, an artificial neural network trained on object classification. We fit the metric to a new database based on 140k unique images annotated with ground truth by human raters who received minimal instruction. The resulting metric shows competitive performance on TID 2013, a database widely used to assess image quality assessments methods. More interestingly, it shows strong responses to objects potentially carrying semantic relevance such as faces and text, which we demonstrate using a visualization technique and ablation experiments. In effect, the metric appears to model a higher influence of semantic context on judgments, which we observe particularly in untrained raters. As the vast majority of users of image processing systems are unfamiliar with Image Quality Assessment (IQA) tasks, these findings may have significant impact on real-world applications of perceptual metrics.