 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhaseCoder: Microphone Geometry-Agnostic Spatial Audio Understanding for Multimodal LLMs
Jan 28, 2026Current multimodal LLMs process audio as a mono stream, ignoring the rich spatial information essential for embodied AI. Existing spatial audio models, conversely, are constrained to fixed microphone geometries, preventing deployment across diverse devices. We present PhaseCoder, a transformer-only spatial audio encoder that is agnostic to microphone geometry. PhaseCoder takes raw multichannel audio and microphone coordinates as inputs to perform localization and produces robust spatial embeddings. We demonstrate that Gemma 3n LLM can be fine-tuned to reason over "Spatial Audio Tokens" produced by PhaseCoder. We show our encoder achieves state-of-the-art results on microphone-invariant localization benchmarks and, for the first time, enables an LLM to perform complex spatial reasoning and targeted transcription tasks from an arbitrary microphone array.
Predator Prey Scavenger Model using Holling's Functional Response of Type III and Physics-Informed Deep Neural Networks
Dec 24, 2024



Nonlinear mathematical models introduce the relation between various physical and biological interactions present in nature. One of the most famous models is the Lotka-Volterra model which defined the interaction between predator and prey species present in nature. However, predators, scavengers, and prey populations coexist in a natural system where scavengers can additionally rely on the dead bodies of predators present in the system. Keeping this in mind, the formulation and simulation of the predator prey scavenger model is introduced in this paper. For the predation response, respective prey species are assumed to have Holling's functional response of type III. The proposed model is tested for various simulations and is found to be showing satisfactory results in different scenarios. After simulations, the American forest dataset is taken for parameter estimation which imitates the real-world case. For parameter estimation, a physics-informed deep neural network is used with the Adam backpropagation method which prevents the avalanche effect in trainable parameters updation. For neural networks, mean square error and physics-informed informed error are considered. After the neural network, the hence-found parameters are fine-tuned using the Broyden-Fletcher-Goldfarb-Shanno algorithm. Finally, the hence-found parameters using a natural dataset are tested for stability using Jacobian stability analysis. Future research work includes minimization of error induced by parameters, bifurcation analysis, and sensitivity analysis of the parameters.
Unlocking LLMs: Addressing Scarce Data and Bias Challenges in Mental Health
Dec 17, 2024



Large language models (LLMs) have shown promising capabilities in healthcare analysis but face several challenges like hallucinations, parroting, and bias manifestation. These challenges are exacerbated in complex, sensitive, and low-resource domains. Therefore, in this work we introduce IC-AnnoMI, an expert-annotated motivational interviewing (MI) dataset built upon AnnoMI by generating in-context conversational dialogues leveraging LLMs, particularly ChatGPT. IC-AnnoMI employs targeted prompts accurately engineered through cues and tailored information, taking into account therapy style (empathy, reflection), contextual relevance, and false semantic change. Subsequently, the dialogues are annotated by experts, strictly adhering to the Motivational Interviewing Skills Code (MISC), focusing on both the psychological and linguistic dimensions of MI dialogues. We comprehensively evaluate the IC-AnnoMI dataset and ChatGPT's emotional reasoning ability and understanding of domain intricacies by modeling novel classification tasks employing several classical machine learning and current state-of-the-art transformer approaches. Finally, we discuss the effects of progressive prompting strategies and the impact of augmented data in mitigating the biases manifested in IC-AnnoM. Our contributions provide the MI community with not only a comprehensive dataset but also valuable insights for using LLMs in empathetic text generation for conversational therapy in supervised settings.
Apple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
PhilHumans: Benchmarking Machine Learning for Personal Health
May 04, 2024



The use of machine learning in Healthcare has the potential to improve patient outcomes as well as broaden the reach and affordability of Healthcare. The history of other application areas indicates that strong benchmarks are essential for the development of intelligent systems. We present Personal Health Interfaces Leveraging HUman-MAchine Natural interactions (PhilHumans), a holistic suite of benchmarks for machine learning across different Healthcare settings - talk therapy, diet coaching, emergency care, intensive care, obstetric sonography - as well as different learning settings, such as action anticipation, timeseries modeling, insight mining, language modeling, computer vision, reinforcement learning and program synthesis
Ask the experts: sourcing high-quality datasets for nutritional counselling through Human-AI collaboration
Jan 16, 2024Large Language Models (LLMs), with their flexible generation abilities, can be powerful data sources in domains with few or no available corpora. However, problems like hallucinations and biases limit such applications. In this case study, we pick nutrition counselling, a domain lacking any public resource, and show that high-quality datasets can be gathered by combining LLMs, crowd-workers and nutrition experts. We first crowd-source and cluster a novel dataset of diet-related issues, then work with experts to prompt ChatGPT into producing related supportive text. Finally, we let the experts evaluate the safety of the generated text. We release HAI-coaching, the first expert-annotated nutrition counselling dataset containing ~2.4K dietary struggles from crowd workers, and ~97K related supportive texts generated by ChatGPT. Extensive analysis shows that ChatGPT while producing highly fluent and human-like text, also manifests harmful behaviours, especially in sensitive topics like mental health, making it unsuitable for unsupervised use.
VISU at WASSA 2023 Shared Task: Detecting Emotions in Reaction to News Stories Leveraging BERT and Stacked Embeddings
Jul 27, 2023



Our system, VISU, participated in the WASSA 2023 Shared Task (3) of Emotion Classification from essays written in reaction to news articles. Emotion detection from complex dialogues is challenging and often requires context/domain understanding. Therefore in this research, we have focused on developing deep learning (DL) models using the combination of word embedding representations with tailored prepossessing strategies to capture the nuances of emotions expressed. Our experiments used static and contextual embeddings (individual and stacked) with Bidirectional Long short-term memory (BiLSTM) and Transformer based models. We occupied rank tenth in the emotion detection task by scoring a Macro F1-Score of 0.2717, validating the efficacy of our implemented approaches for small and imbalanced datasets with mixed categories of target emotions.
SPAE: Semantic Pyramid AutoEncoder for Multimodal Generation with Frozen LLMs
Jul 03, 2023



In this work, we introduce Semantic Pyramid AutoEncoder (SPAE) for enabling frozen LLMs to perform both understanding and generation tasks involving non-linguistic modalities such as images or videos. SPAE converts between raw pixels and interpretable lexical tokens (or words) extracted from the LLM's vocabulary. The resulting tokens capture both the semantic meaning and the fine-grained details needed for visual reconstruction, effectively translating the visual content into a language comprehensible to the LLM, and empowering it to perform a wide array of multimodal tasks. Our approach is validated through in-context learning experiments with frozen PaLM 2 and GPT 3.5 on a diverse set of image understanding and generation tasks. Our method marks the first successful attempt to enable a frozen LLM to generate image content while surpassing state-of-the-art performance in image understanding tasks, under the same setting, by over 25%.
The MABe22 Benchmarks for Representation Learning of Multi-Agent Behavior
Jul 21, 2022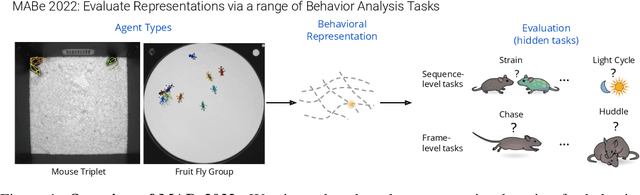
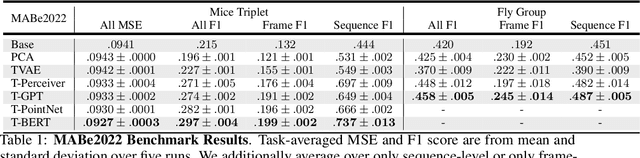
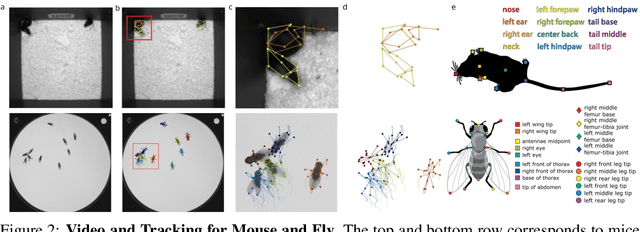
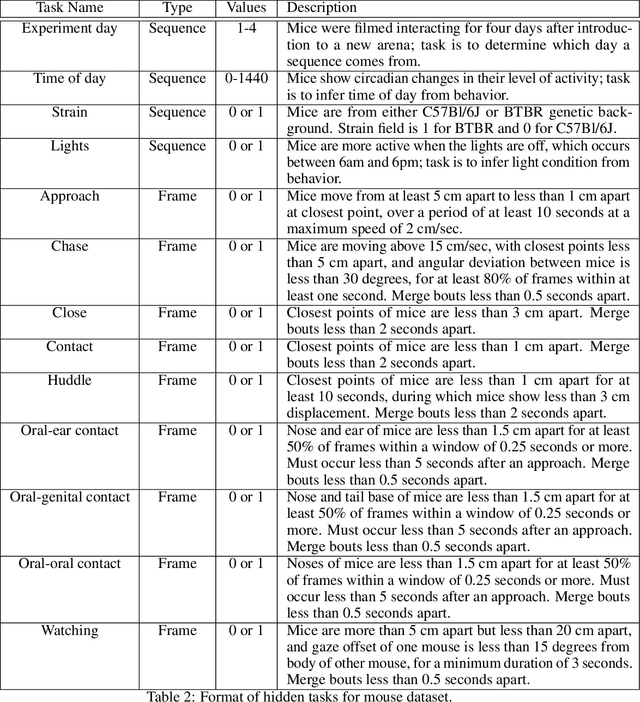
Real-world behavior is often shaped by complex interactions between multiple agents. To scalably study multi-agent behavior, advances in unsupervised and self-supervised learning have enabled a variety of different behavioral representations to be learned from trajectory data. To date, there does not exist a unified set of benchmarks that can enable comparing methods quantitatively and systematically across a broad set of behavior analysis settings. We aim to address this by introducing a large-scale, multi-agent trajectory dataset from real-world behavioral neuroscience experiments that covers a range of behavior analysis tasks. Our dataset consists of trajectory data from common model organisms, with 9.6 million frames of mouse data and 4.4 million frames of fly data, in a variety of experimental settings, such as different strains, lengths of interaction, and optogenetic stimulation. A subset of the frames also consist of expert-annotated behavior labels. Improvements on our dataset corresponds to behavioral representations that work across multiple organisms and is able to capture differences for common behavior analysis tasks.
Practice Makes a Solver Perfect: Data Augmentation for Math Word Problem Solvers
Apr 30, 2022
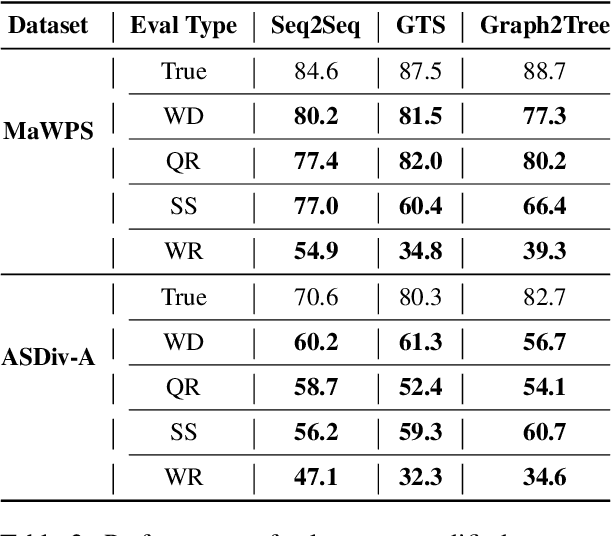
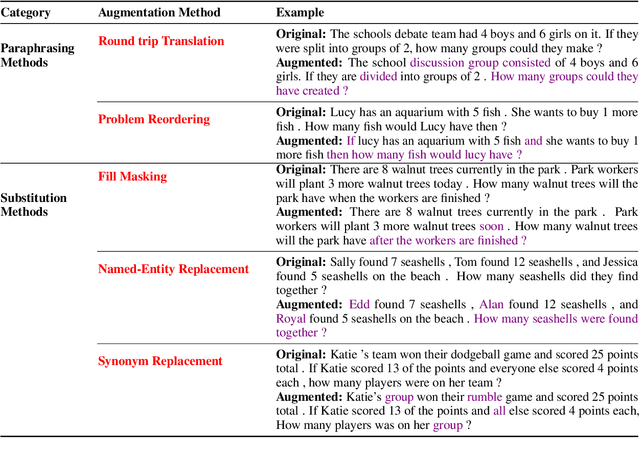
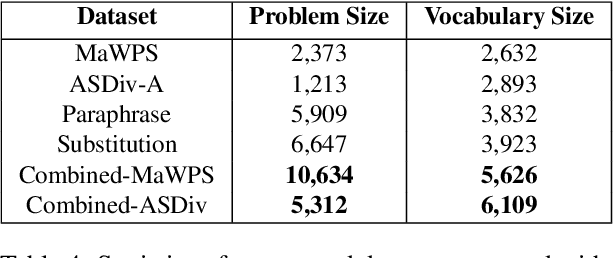
Existing Math Word Problem (MWP) solvers have achieved high accuracy on benchmark datasets. However, prior works have shown that such solvers do not generalize well and rely on superficial cues to achieve high performance. In this paper, we first conduct experiments to showcase that this behaviour is mainly associated with the limited size and diversity present in existing MWP datasets. Next, we propose several data augmentation techniques broadly categorized into Substitution and Paraphrasing based methods. By deploying these methods we increase the size of existing datasets by five folds. Extensive experiments on two benchmark datasets across three state-of-the-art MWP solvers show that proposed methods increase the generalization and robustness of existing solvers. On average, proposed methods significantly increase the state-of-the-art results by over five percentage points on benchmark datasets. Further, the solvers trained on the augmented dataset perform comparatively better on the challenge test set. We also show the effectiveness of proposed techniques through ablation studies and verify the quality of augmented samples through human evaluation.