 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Illusion of Intervention: Your LLM-Simulated Experiment is an Observational Study
May 20, 2026Large language models (LLMs) show potential as simulators of human behavior, offering a scalable way to study responses to interventions. However, because LLMs are trained largely on observational data, interventions in experiments with LLM-simulated synthetic users can induce unintended shifts in latent user attributes, causing user drift where the implicit simulated population differs across treatment conditions, potentially distorting effect estimates. We formalize the confounding or selection bias that can arise due to user drift and show how intervention-dependent shifts can inflate or attenuate observed differences in user responses under intervention. To diagnose confounding, we propose using negative control outcomes--attributes that should remain invariant under intervention--to identify distribution shifts across intervention conditions, providing evidence of user drift. To mitigate drift, we study adjusting the persona specification by eliciting additional confounders, finding that targeted, setting-relevant confounders can substantially reduce bias across survey-style and multi-turn agent evaluations.
Identity, Cooperation and Framing Effects within Groups of Real and Simulated Humans
Jan 22, 2026Humans act via a nuanced process that depends both on rational deliberation and also on identity and contextual factors. In this work, we study how large language models (LLMs) can simulate human action in the context of social dilemma games. While prior work has focused on "steering" (weak binding) of chat models to simulate personas, we analyze here how deep binding of base models with extended backstories leads to more faithful replication of identity-based behaviors. Our study has these findings: simulation fidelity vs human studies is improved by conditioning base LMs with rich context of narrative identities and checking consistency using instruction-tuned models. We show that LLMs can also model contextual factors such as time (year that a study was performed), question framing, and participant pool effects. LLMs, therefore, allow us to explore the details that affect human studies but which are often omitted from experiment descriptions, and which hamper accurate replication.
Conversational Planning for Personal Plans
Feb 26, 2025


The language generation and reasoning capabilities of large language models (LLMs) have enabled conversational systems with impressive performance in a variety of tasks, from code generation, to composing essays, to passing STEM and legal exams, to a new paradigm for knowledge search. Besides those short-term use applications, LLMs are increasingly used to help with real-life goals or tasks that take a long time to complete, involving multiple sessions across days, weeks, months, or even years. Thus to enable conversational systems for long term interactions and tasks, we need language-based agents that can plan for long horizons. Traditionally, such capabilities were addressed by reinforcement learning agents with hierarchical planning capabilities. In this work, we explore a novel architecture where the LLM acts as the meta-controller deciding the agent's next macro-action, and tool use augmented LLM-based option policies execute the selected macro-action. We instantiate this framework for a specific set of macro-actions enabling adaptive planning for users' personal plans through conversation and follow-up questions collecting user feedback. We show how this paradigm can be applicable in scenarios ranging from tutoring for academic and non-academic tasks to conversational coaching for personal health plans.
Sleepless Nights, Sugary Days: Creating Synthetic Users with Health Conditions for Realistic Coaching Agent Interactions
Feb 18, 2025We present an end-to-end framework for generating synthetic users for evaluating interactive agents designed to encourage positive behavior changes, such as in health and lifestyle coaching. The synthetic users are grounded in health and lifestyle conditions, specifically sleep and diabetes management in this study, to ensure realistic interactions with the health coaching agent. Synthetic users are created in two stages: first, structured data are generated grounded in real-world health and lifestyle factors in addition to basic demographics and behavioral attributes; second, full profiles of the synthetic users are developed conditioned on the structured data. Interactions between synthetic users and the coaching agent are simulated using generative agent-based models such as Concordia, or directly by prompting a language model. Using two independently-developed agents for sleep and diabetes coaching as case studies, the validity of this framework is demonstrated by analyzing the coaching agent's understanding of the synthetic users' needs and challenges. Finally, through multiple blinded evaluations of user-coach interactions by human experts, we demonstrate that our synthetic users with health and behavioral attributes more accurately portray real human users with the same attributes, compared to generic synthetic users not grounded in such attributes. The proposed framework lays the foundation for efficient development of conversational agents through extensive, realistic, and grounded simulated interactions.
Low-resourced Languages and Online Knowledge Repositories: A Need-Finding Study
May 26, 2024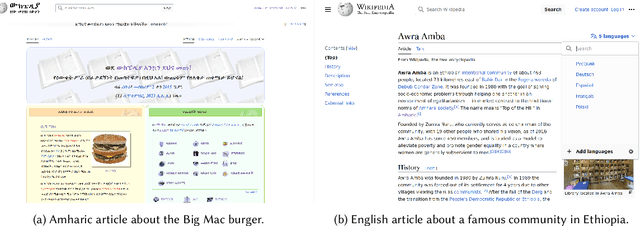



Online Knowledge Repositories (OKRs) like Wikipedia offer communities a way to share and preserve information about themselves and their ways of living. However, for communities with low-resourced languages -- including most African communities -- the quality and volume of content available are often inadequate. One reason for this lack of adequate content could be that many OKRs embody Western ways of knowledge preservation and sharing, requiring many low-resourced language communities to adapt to new interactions. To understand the challenges faced by low-resourced language contributors on the popular OKR Wikipedia, we conducted (1) a thematic analysis of Wikipedia forum discussions and (2) a contextual inquiry study with 14 novice contributors. We focused on three Ethiopian languages: Afan Oromo, Amharic, and Tigrinya. Our analysis revealed several recurring themes; for example, contributors struggle to find resources to corroborate their articles in low-resourced languages, and language technology support, like translation systems and spellcheck, result in several errors that waste contributors' time. We hope our study will support designers in making online knowledge repositories accessible to low-resourced language speakers.
ALOHa: A New Measure for Hallucination in Captioning Models
Apr 03, 2024



Despite recent advances in multimodal pre-training for visual description, state-of-the-art models still produce captions containing errors, such as hallucinating objects not present in a scene. The existing prominent metric for object hallucination, CHAIR, is limited to a fixed set of MS COCO objects and synonyms. In this work, we propose a modernized open-vocabulary metric, ALOHa, which leverages large language models (LLMs) to measure object hallucinations. Specifically, we use an LLM to extract groundable objects from a candidate caption, measure their semantic similarity to reference objects from captions and object detections, and use Hungarian matching to produce a final hallucination score. We show that ALOHa correctly identifies 13.6% more hallucinated objects than CHAIR on HAT, a new gold-standard subset of MS COCO Captions annotated for hallucinations, and 30.8% more on nocaps, where objects extend beyond MS COCO categories. Our code is available at https://davidmchan.github.io/aloha/.
A Human-Inspired Reading Agent with Gist Memory of Very Long Contexts
Feb 23, 2024Current Large Language Models (LLMs) are not only limited to some maximum context length, but also are not able to robustly consume long inputs. To address these limitations, we propose ReadAgent, an LLM agent system that increases effective context length up to 20x in our experiments. Inspired by how humans interactively read long documents, we implement ReadAgent as a simple prompting system that uses the advanced language capabilities of LLMs to (1) decide what content to store together in a memory episode, (2) compress those memory episodes into short episodic memories called gist memories, and (3) take actions to look up passages in the original text if ReadAgent needs to remind itself of relevant details to complete a task. We evaluate ReadAgent against baselines using retrieval methods, using the original long contexts, and using the gist memories. These evaluations are performed on three long-document reading comprehension tasks: QuALITY, NarrativeQA, and QMSum. ReadAgent outperforms the baselines on all three tasks while extending the effective context window by 3-20x.
Moral Foundations of Large Language Models
Oct 23, 2023



Moral foundations theory (MFT) is a psychological assessment tool that decomposes human moral reasoning into five factors, including care/harm, liberty/oppression, and sanctity/degradation (Graham et al., 2009). People vary in the weight they place on these dimensions when making moral decisions, in part due to their cultural upbringing and political ideology. As large language models (LLMs) are trained on datasets collected from the internet, they may reflect the biases that are present in such corpora. This paper uses MFT as a lens to analyze whether popular LLMs have acquired a bias towards a particular set of moral values. We analyze known LLMs and find they exhibit particular moral foundations, and show how these relate to human moral foundations and political affiliations. We also measure the consistency of these biases, or whether they vary strongly depending on the context of how the model is prompted. Finally, we show that we can adversarially select prompts that encourage the moral to exhibit a particular set of moral foundations, and that this can affect the model's behavior on downstream tasks. These findings help illustrate the potential risks and unintended consequences of LLMs assuming a particular moral stance.
CLAIR: Evaluating Image Captions with Large Language Models
Oct 19, 2023



The evaluation of machine-generated image captions poses an interesting yet persistent challenge. Effective evaluation measures must consider numerous dimensions of similarity, including semantic relevance, visual structure, object interactions, caption diversity, and specificity. Existing highly-engineered measures attempt to capture specific aspects, but fall short in providing a holistic score that aligns closely with human judgments. Here, we propose CLAIR, a novel method that leverages the zero-shot language modeling capabilities of large language models (LLMs) to evaluate candidate captions. In our evaluations, CLAIR demonstrates a stronger correlation with human judgments of caption quality compared to existing measures. Notably, on Flickr8K-Expert, CLAIR achieves relative correlation improvements over SPICE of 39.6% and over image-augmented methods such as RefCLIP-S of 18.3%. Moreover, CLAIR provides noisily interpretable results by allowing the language model to identify the underlying reasoning behind its assigned score. Code is available at https://davidmchan.github.io/clair/
$IC^3$: Image Captioning by Committee Consensus
Feb 16, 2023



If you ask a human to describe an image, they might do so in a thousand different ways. Traditionally, image captioning models are trained to approximate the reference distribution of image captions, however, doing so encourages captions that are viewpoint-impoverished. Such captions often focus on only a subset of the possible details, while ignoring potentially useful information in the scene. In this work, we introduce a simple, yet novel, method: "Image Captioning by Committee Consensus" ($IC^3$), designed to generate a single caption that captures high-level details from several viewpoints. Notably, humans rate captions produced by $IC^3$ at least as helpful as baseline SOTA models more than two thirds of the time, and $IC^3$ captions can improve the performance of SOTA automated recall systems by up to 84%, indicating significant material improvements over existing SOTA approaches for visual description. Our code is publicly available at https://github.com/DavidMChan/caption-by-committee