 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizable and Animatable 3D Full-Head Gaussian Avatar from a Single Image
Jan 19, 2026Building 3D animatable head avatars from a single image is an important yet challenging problem. Existing methods generally collapse under large camera pose variations, compromising the realism of 3D avatars. In this work, we propose a new framework to tackle the novel setting of one-shot 3D full-head animatable avatar reconstruction in a single feed-forward pass, enabling real-time animation and simultaneous 360$^\circ$ rendering views. To facilitate efficient animation control, we model 3D head avatars with Gaussian primitives embedded on the surface of a parametric face model within the UV space. To obtain knowledge of full-head geometry and textures, we leverage rich 3D full-head priors within a pretrained 3D generative adversarial network (GAN) for global full-head feature extraction and multi-view supervision. To increase the fidelity of the 3D reconstruction of the input image, we take advantage of the symmetric nature of the UV space and human faces to fuse local fine-grained input image features with the global full-head textures. Extensive experiments demonstrate the effectiveness of our method, achieving high-quality 3D full-head modeling as well as real-time animation, thereby improving the realism of 3D talking avatars.
N3D-VLM: Native 3D Grounding Enables Accurate Spatial Reasoning in Vision-Language Models
Dec 18, 2025While current multimodal models can answer questions based on 2D images, they lack intrinsic 3D object perception, limiting their ability to comprehend spatial relationships and depth cues in 3D scenes. In this work, we propose N3D-VLM, a novel unified framework that seamlessly integrates native 3D object perception with 3D-aware visual reasoning, enabling both precise 3D grounding and interpretable spatial understanding. Unlike conventional end-to-end models that directly predict answers from RGB/RGB-D inputs, our approach equips the model with native 3D object perception capabilities, enabling it to directly localize objects in 3D space based on textual descriptions. Building upon accurate 3D object localization, the model further performs explicit reasoning in 3D, achieving more interpretable and structured spatial understanding. To support robust training for these capabilities, we develop a scalable data construction pipeline that leverages depth estimation to lift large-scale 2D annotations into 3D space, significantly increasing the diversity and coverage for 3D object grounding data, yielding over six times larger than the largest existing single-image 3D detection dataset. Moreover, the pipeline generates spatial question-answering datasets that target chain-of-thought (CoT) reasoning in 3D, facilitating joint training for both 3D object localization and 3D spatial reasoning. Experimental results demonstrate that our unified framework not only achieves state-of-the-art performance on 3D grounding tasks, but also consistently surpasses existing methods in 3D spatial reasoning in vision-language model.
TSkel-Mamba: Temporal Dynamic Modeling via State Space Model for Human Skeleton-based Action Recognition
Dec 12, 2025Skeleton-based action recognition has garnered significant attention in the computer vision community. Inspired by the recent success of the selective state-space model (SSM) Mamba in modeling 1D temporal sequences, we propose TSkel-Mamba, a hybrid Transformer-Mamba framework that effectively captures both spatial and temporal dynamics. In particular, our approach leverages Spatial Transformer for spatial feature learning while utilizing Mamba for temporal modeling. Mamba, however, employs separate SSM blocks for individual channels, which inherently limits its ability to model inter-channel dependencies. To better adapt Mamba for skeleton data and enhance Mamba`s ability to model temporal dependencies, we introduce a Temporal Dynamic Modeling (TDM) block, which is a versatile plug-and-play component that integrates a novel Multi-scale Temporal Interaction (MTI) module. The MTI module employs multi-scale Cycle operators to capture cross-channel temporal interactions, a critical factor in action recognition. Extensive experiments on NTU-RGB+D 60, NTU-RGB+D 120, NW-UCLA and UAV-Human datasets demonstrate that TSkel-Mamba achieves state-of-the-art performance while maintaining low inference time, making it both efficient and highly effective.
Are We Ready for RL in Text-to-3D Generation? A Progressive Investigation
Dec 11, 2025Reinforcement learning (RL), earlier proven to be effective in large language and multi-modal models, has been successfully extended to enhance 2D image generation recently. However, applying RL to 3D generation remains largely unexplored due to the higher spatial complexity of 3D objects, which require globally consistent geometry and fine-grained local textures. This makes 3D generation significantly sensitive to reward designs and RL algorithms. To address these challenges, we conduct the first systematic study of RL for text-to-3D autoregressive generation across several dimensions. (1) Reward designs: We evaluate reward dimensions and model choices, showing that alignment with human preference is crucial, and that general multi-modal models provide robust signal for 3D attributes. (2) RL algorithms: We study GRPO variants, highlighting the effectiveness of token-level optimization, and further investigate the scaling of training data and iterations. (3) Text-to-3D Benchmarks: Since existing benchmarks fail to measure implicit reasoning abilities in 3D generation models, we introduce MME-3DR. (4) Advanced RL paradigms: Motivated by the natural hierarchy of 3D generation, we propose Hi-GRPO, which optimizes the global-to-local hierarchical 3D generation through dedicated reward ensembles. Based on these insights, we develop AR3D-R1, the first RL-enhanced text-to-3D model, expert from coarse shape to texture refinement. We hope this study provides insights into RL-driven reasoning for 3D generation. Code is released at https://github.com/Ivan-Tang-3D/3DGen-R1.
FullPart: Generating each 3D Part at Full Resolution
Oct 30, 2025Part-based 3D generation holds great potential for various applications. Previous part generators that represent parts using implicit vector-set tokens often suffer from insufficient geometric details. Another line of work adopts an explicit voxel representation but shares a global voxel grid among all parts; this often causes small parts to occupy too few voxels, leading to degraded quality. In this paper, we propose FullPart, a novel framework that combines both implicit and explicit paradigms. It first derives the bounding box layout through an implicit box vector-set diffusion process, a task that implicit diffusion handles effectively since box tokens contain little geometric detail. Then, it generates detailed parts, each within its own fixed full-resolution voxel grid. Instead of sharing a global low-resolution space, each part in our method - even small ones - is generated at full resolution, enabling the synthesis of intricate details. We further introduce a center-point encoding strategy to address the misalignment issue when exchanging information between parts of different actual sizes, thereby maintaining global coherence. Moreover, to tackle the scarcity of reliable part data, we present PartVerse-XL, the largest human-annotated 3D part dataset to date with 40K objects and 320K parts. Extensive experiments demonstrate that FullPart achieves state-of-the-art results in 3D part generation. We will release all code, data, and model to benefit future research in 3D part generation.
CVD-STORM: Cross-View Video Diffusion with Spatial-Temporal Reconstruction Model for Autonomous Driving
Oct 09, 2025Generative models have been widely applied to world modeling for environment simulation and future state prediction. With advancements in autonomous driving, there is a growing demand not only for high-fidelity video generation under various controls, but also for producing diverse and meaningful information such as depth estimation. To address this, we propose CVD-STORM, a cross-view video diffusion model utilizing a spatial-temporal reconstruction Variational Autoencoder (VAE) that generates long-term, multi-view videos with 4D reconstruction capabilities under various control inputs. Our approach first fine-tunes the VAE with an auxiliary 4D reconstruction task, enhancing its ability to encode 3D structures and temporal dynamics. Subsequently, we integrate this VAE into the video diffusion process to significantly improve generation quality. Experimental results demonstrate that our model achieves substantial improvements in both FID and FVD metrics. Additionally, the jointly-trained Gaussian Splatting Decoder effectively reconstructs dynamic scenes, providing valuable geometric information for comprehensive scene understanding.
Progressive Gaussian Transformer with Anisotropy-aware Sampling for Open Vocabulary Occupancy Prediction
Oct 06, 2025
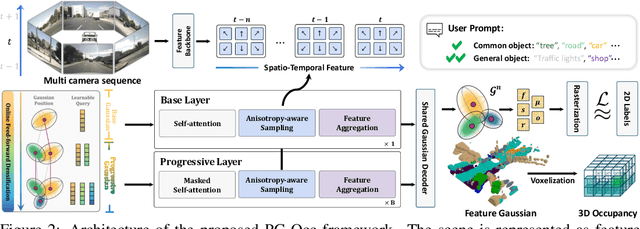


The 3D occupancy prediction task has witnessed remarkable progress in recent years, playing a crucial role in vision-based autonomous driving systems. While traditional methods are limited to fixed semantic categories, recent approaches have moved towards predicting text-aligned features to enable open-vocabulary text queries in real-world scenes. However, there exists a trade-off in text-aligned scene modeling: sparse Gaussian representation struggles to capture small objects in the scene, while dense representation incurs significant computational overhead. To address these limitations, we present PG-Occ, an innovative Progressive Gaussian Transformer Framework that enables open-vocabulary 3D occupancy prediction. Our framework employs progressive online densification, a feed-forward strategy that gradually enhances the 3D Gaussian representation to capture fine-grained scene details. By iteratively enhancing the representation, the framework achieves increasingly precise and detailed scene understanding. Another key contribution is the introduction of an anisotropy-aware sampling strategy with spatio-temporal fusion, which adaptively assigns receptive fields to Gaussians at different scales and stages, enabling more effective feature aggregation and richer scene information capture. Through extensive evaluations, we demonstrate that PG-Occ achieves state-of-the-art performance with a relative 14.3% mIoU improvement over the previous best performing method. Code and pretrained models will be released upon publication on our project page: https://yanchi-3dv.github.io/PG-Occ
Rep-MTL: Unleashing the Power of Representation-level Task Saliency for Multi-Task Learning
Jul 28, 2025Despite the promise of Multi-Task Learning in leveraging complementary knowledge across tasks, existing multi-task optimization (MTO) techniques remain fixated on resolving conflicts via optimizer-centric loss scaling and gradient manipulation strategies, yet fail to deliver consistent gains. In this paper, we argue that the shared representation space, where task interactions naturally occur, offers rich information and potential for operations complementary to existing optimizers, especially for facilitating the inter-task complementarity, which is rarely explored in MTO. This intuition leads to Rep-MTL, which exploits the representation-level task saliency to quantify interactions between task-specific optimization and shared representation learning. By steering these saliencies through entropy-based penalization and sample-wise cross-task alignment, Rep-MTL aims to mitigate negative transfer by maintaining the effective training of individual tasks instead pure conflict-solving, while explicitly promoting complementary information sharing. Experiments are conducted on four challenging MTL benchmarks covering both task-shift and domain-shift scenarios. The results show that Rep-MTL, even paired with the basic equal weighting policy, achieves competitive performance gains with favorable efficiency. Beyond standard performance metrics, Power Law exponent analysis demonstrates Rep-MTL's efficacy in balancing task-specific learning and cross-task sharing. The project page is available at HERE.
UniMC: Taming Diffusion Transformer for Unified Keypoint-Guided Multi-Class Image Generation
Jul 03, 2025Although significant advancements have been achieved in the progress of keypoint-guided Text-to-Image diffusion models, existing mainstream keypoint-guided models encounter challenges in controlling the generation of more general non-rigid objects beyond humans (e.g., animals). Moreover, it is difficult to generate multiple overlapping humans and animals based on keypoint controls solely. These challenges arise from two main aspects: the inherent limitations of existing controllable methods and the lack of suitable datasets. First, we design a DiT-based framework, named UniMC, to explore unifying controllable multi-class image generation. UniMC integrates instance- and keypoint-level conditions into compact tokens, incorporating attributes such as class, bounding box, and keypoint coordinates. This approach overcomes the limitations of previous methods that struggled to distinguish instances and classes due to their reliance on skeleton images as conditions. Second, we propose HAIG-2.9M, a large-scale, high-quality, and diverse dataset designed for keypoint-guided human and animal image generation. HAIG-2.9M includes 786K images with 2.9M instances. This dataset features extensive annotations such as keypoints, bounding boxes, and fine-grained captions for both humans and animals, along with rigorous manual inspection to ensure annotation accuracy. Extensive experiments demonstrate the high quality of HAIG-2.9M and the effectiveness of UniMC, particularly in heavy occlusions and multi-class scenarios.
HAMF: A Hybrid Attention-Mamba Framework for Joint Scene Context Understanding and Future Motion Representation Learning
May 21, 2025



Motion forecasting represents a critical challenge in autonomous driving systems, requiring accurate prediction of surrounding agents' future trajectories. While existing approaches predict future motion states with the extracted scene context feature from historical agent trajectories and road layouts, they suffer from the information degradation during the scene feature encoding. To address the limitation, we propose HAMF, a novel motion forecasting framework that learns future motion representations with the scene context encoding jointly, to coherently combine the scene understanding and future motion state prediction. We first embed the observed agent states and map information into 1D token sequences, together with the target multi-modal future motion features as a set of learnable tokens. Then we design a unified Attention-based encoder, which synergistically combines self-attention and cross-attention mechanisms to model the scene context information and aggregate future motion features jointly. Complementing the encoder, we implement the Mamba module in the decoding stage to further preserve the consistency and correlations among the learned future motion representations, to generate the accurate and diverse final trajectories. Extensive experiments on Argoverse 2 benchmark demonstrate that our hybrid Attention-Mamba model achieves state-of-the-art motion forecasting performance with the simple and lightweight architecture.