 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVITA-VLA: Efficiently Teaching Vision-Language Models to Act via Action Expert Distillation
Oct 10, 2025Vision-Language Action (VLA) models significantly advance robotic manipulation by leveraging the strong perception capabilities of pretrained vision-language models (VLMs). By integrating action modules into these pretrained models, VLA methods exhibit improved generalization. However, training them from scratch is costly. In this work, we propose a simple yet effective distillation-based framework that equips VLMs with action-execution capability by transferring knowledge from pretrained small action models. Our architecture retains the original VLM structure, adding only an action token and a state encoder to incorporate physical inputs. To distill action knowledge, we adopt a two-stage training strategy. First, we perform lightweight alignment by mapping VLM hidden states into the action space of the small action model, enabling effective reuse of its pretrained action decoder and avoiding expensive pretraining. Second, we selectively fine-tune the language model, state encoder, and action modules, enabling the system to integrate multimodal inputs with precise action generation. Specifically, the action token provides the VLM with a direct handle for predicting future actions, while the state encoder allows the model to incorporate robot dynamics not captured by vision alone. This design yields substantial efficiency gains over training large VLA models from scratch. Compared with previous state-of-the-art methods, our method achieves 97.3% average success rate on LIBERO (11.8% improvement) and 93.5% on LIBERO-LONG (24.5% improvement). In real-world experiments across five manipulation tasks, our method consistently outperforms the teacher model, achieving 82.0% success rate (17% improvement), which demonstrate that action distillation effectively enables VLMs to generate precise actions while substantially reducing training costs.
Progressive Gaussian Transformer with Anisotropy-aware Sampling for Open Vocabulary Occupancy Prediction
Oct 06, 2025
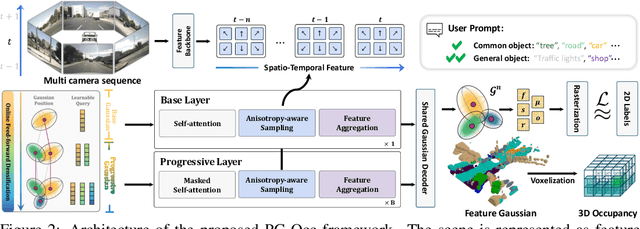


The 3D occupancy prediction task has witnessed remarkable progress in recent years, playing a crucial role in vision-based autonomous driving systems. While traditional methods are limited to fixed semantic categories, recent approaches have moved towards predicting text-aligned features to enable open-vocabulary text queries in real-world scenes. However, there exists a trade-off in text-aligned scene modeling: sparse Gaussian representation struggles to capture small objects in the scene, while dense representation incurs significant computational overhead. To address these limitations, we present PG-Occ, an innovative Progressive Gaussian Transformer Framework that enables open-vocabulary 3D occupancy prediction. Our framework employs progressive online densification, a feed-forward strategy that gradually enhances the 3D Gaussian representation to capture fine-grained scene details. By iteratively enhancing the representation, the framework achieves increasingly precise and detailed scene understanding. Another key contribution is the introduction of an anisotropy-aware sampling strategy with spatio-temporal fusion, which adaptively assigns receptive fields to Gaussians at different scales and stages, enabling more effective feature aggregation and richer scene information capture. Through extensive evaluations, we demonstrate that PG-Occ achieves state-of-the-art performance with a relative 14.3% mIoU improvement over the previous best performing method. Code and pretrained models will be released upon publication on our project page: https://yanchi-3dv.github.io/PG-Occ
AerialVG: A Challenging Benchmark for Aerial Visual Grounding by Exploring Positional Relations
Apr 10, 2025Visual grounding (VG) aims to localize target objects in an image based on natural language descriptions. In this paper, we propose AerialVG, a new task focusing on visual grounding from aerial views. Compared to traditional VG, AerialVG poses new challenges, \emph{e.g.}, appearance-based grounding is insufficient to distinguish among multiple visually similar objects, and positional relations should be emphasized. Besides, existing VG models struggle when applied to aerial imagery, where high-resolution images cause significant difficulties. To address these challenges, we introduce the first AerialVG dataset, consisting of 5K real-world aerial images, 50K manually annotated descriptions, and 103K objects. Particularly, each annotation in AerialVG dataset contains multiple target objects annotated with relative spatial relations, requiring models to perform comprehensive spatial reasoning. Furthermore, we propose an innovative model especially for the AerialVG task, where a Hierarchical Cross-Attention is devised to focus on target regions, and a Relation-Aware Grounding module is designed to infer positional relations. Experimental results validate the effectiveness of our dataset and method, highlighting the importance of spatial reasoning in aerial visual grounding. The code and dataset will be released.
Implicit Event-RGBD Neural SLAM
Nov 21, 2023Implicit neural SLAM has achieved remarkable progress recently. Nevertheless, existing methods face significant challenges in non-ideal scenarios, such as motion blur or lighting variation, which often leads to issues like convergence failures, localization drifts, and distorted mapping. To address these challenges, we propose $\textbf{EN-SLAM}$, the first event-RGBD implicit neural SLAM framework, which effectively leverages the high rate and high dynamic range advantages of event data for tracking and mapping. Specifically, EN-SLAM proposes a differentiable CRF (Camera Response Function) rendering technique to generate distinct RGB and event camera data via a shared radiance field, which is optimized by learning a unified implicit representation with the captured event and RGBD supervision. Moreover, based on the temporal difference property of events, we propose a temporal aggregating optimization strategy for the event joint tracking and global bundle adjustment, capitalizing on the consecutive difference constraints of events, significantly enhancing tracking accuracy and robustness. Finally, we construct the simulated dataset $\textbf{DEV-Indoors}$ and real captured dataset $\textbf{DEV-Reals}$ containing 6 scenes, 17 sequences with practical motion blur and lighting changes for evaluations. Experimental results show that our method outperforms the SOTA methods in both tracking ATE and mapping ACC with a real-time $17$ FPS in various challenging environments. The code and dataset will be released soon.
GS-SLAM: Dense Visual SLAM with 3D Gaussian Splatting
Nov 21, 2023



In this paper, we introduce $\textbf{GS-SLAM}$ that first utilizes 3D Gaussian representation in the Simultaneous Localization and Mapping (SLAM) system. It facilitates a better balance between efficiency and accuracy. Compared to recent SLAM methods employing neural implicit representations, our method utilizes a real-time differentiable splatting rendering pipeline that offers significant speedup to map optimization and RGB-D re-rendering. Specifically, we propose an adaptive expansion strategy that adds new or deletes noisy 3D Gaussian in order to efficiently reconstruct new observed scene geometry and improve the mapping of previously observed areas. This strategy is essential to extend 3D Gaussian representation to reconstruct the whole scene rather than synthesize a static object in existing methods. Moreover, in the pose tracking process, an effective coarse-to-fine technique is designed to select reliable 3D Gaussian representations to optimize camera pose, resulting in runtime reduction and robust estimation. Our method achieves competitive performance compared with existing state-of-the-art real-time methods on the Replica, TUM-RGBD datasets. The source code will be released soon.