 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStream3D-VLM: Online 3D Spatial Understanding with Incremental Geometry Priors
Jun 05, 2026Despite advances in 3D scene understanding, existing 3D Large Multimodal Models operate in offline settings, requiring complete scene observations or predefined video clips. In this paper, we present an online 3D vision-language model that enables real-time spatial understanding from streaming video. Our approach adopts an autoregressive streaming control modeling based on the LLM's next-token prediction objective to learn when to respond, and employs a lightweight Visual-Spatial Feature Integration (VSFI) module to incrementally inject temporally aligned geometry priors into the visual stream. To alleviate long-context decoding overhead, we propose a plug-and-play Geometry-Adaptive Voxel Compression (GAVC) module for efficient visual token compression. To address the scarcity of streaming 3D-language data, we further develop a scalable data generation pipeline that curates over 1M online spatio-temporal 3D QA pairs and establishes a comprehensive benchmark spanning 29 tasks. Extensive experiments show that our approach significantly outperforms both proprietary and open-source models across online and offline 3D spatial understanding, reasoning, and grounding tasks. The project page is available at https://stream3d-vlm.github.io/
VisionTrim: Unified Vision Token Compression for Training-Free MLLM Acceleration
Jan 30, 2026Multimodal large language models (MLLMs) suffer from high computational costs due to excessive visual tokens, particularly in high-resolution and video-based scenarios. Existing token reduction methods typically focus on isolated pipeline components and often neglect textual alignment, leading to performance degradation. In this paper, we propose VisionTrim, a unified framework for training-free MLLM acceleration, integrating two effective plug-and-play modules: 1) the Dominant Vision Token Selection (DVTS) module, which preserves essential visual tokens via a global-local view, and 2) the Text-Guided Vision Complement (TGVC) module, which facilitates context-aware token merging guided by textual cues. Extensive experiments across diverse image and video multimodal benchmarks demonstrate the performance superiority of our VisionTrim, advancing practical MLLM deployment in real-world applications. The code is available at: https://github.com/hanxunyu/VisionTrim.
N3D-VLM: Native 3D Grounding Enables Accurate Spatial Reasoning in Vision-Language Models
Dec 18, 2025While current multimodal models can answer questions based on 2D images, they lack intrinsic 3D object perception, limiting their ability to comprehend spatial relationships and depth cues in 3D scenes. In this work, we propose N3D-VLM, a novel unified framework that seamlessly integrates native 3D object perception with 3D-aware visual reasoning, enabling both precise 3D grounding and interpretable spatial understanding. Unlike conventional end-to-end models that directly predict answers from RGB/RGB-D inputs, our approach equips the model with native 3D object perception capabilities, enabling it to directly localize objects in 3D space based on textual descriptions. Building upon accurate 3D object localization, the model further performs explicit reasoning in 3D, achieving more interpretable and structured spatial understanding. To support robust training for these capabilities, we develop a scalable data construction pipeline that leverages depth estimation to lift large-scale 2D annotations into 3D space, significantly increasing the diversity and coverage for 3D object grounding data, yielding over six times larger than the largest existing single-image 3D detection dataset. Moreover, the pipeline generates spatial question-answering datasets that target chain-of-thought (CoT) reasoning in 3D, facilitating joint training for both 3D object localization and 3D spatial reasoning. Experimental results demonstrate that our unified framework not only achieves state-of-the-art performance on 3D grounding tasks, but also consistently surpasses existing methods in 3D spatial reasoning in vision-language model.
StreamingAssistant: Efficient Visual Token Pruning for Accelerating Online Video Understanding
Dec 14, 2025Online video understanding is essential for applications like public surveillance and AI glasses. However, applying Multimodal Large Language Models (MLLMs) to this domain is challenging due to the large number of video frames, resulting in high GPU memory usage and computational latency. To address these challenges, we propose token pruning as a means to reduce context length while retaining critical information. Specifically, we introduce a novel redundancy metric, Maximum Similarity to Spatially Adjacent Video Tokens (MSSAVT), which accounts for both token similarity and spatial position. To mitigate the bidirectional dependency between pruning and redundancy, we further design a masked pruning strategy that ensures only mutually unadjacent tokens are pruned. We also integrate an existing temporal redundancy-based pruning method to eliminate temporal redundancy of the video modality. Experimental results on multiple online and offline video understanding benchmarks demonstrate that our method significantly improves the accuracy (i.e., by 4\% at most) while incurring a negligible pruning latency (i.e., less than 1ms). Our full implementation will be made publicly available.
Physical Adversarial Attack meets Computer Vision: A Decade Survey
Sep 30, 2022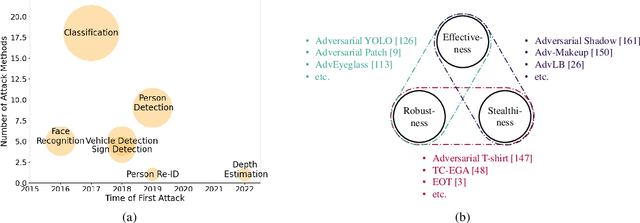
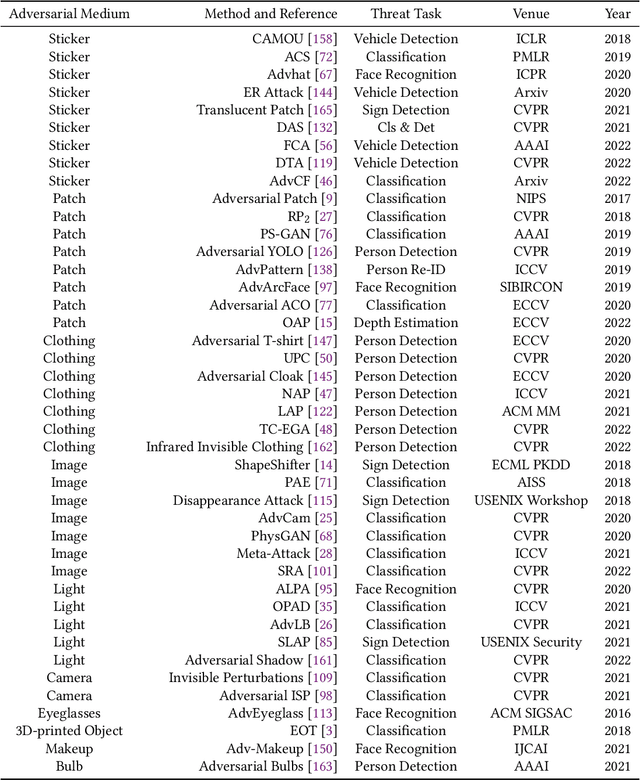

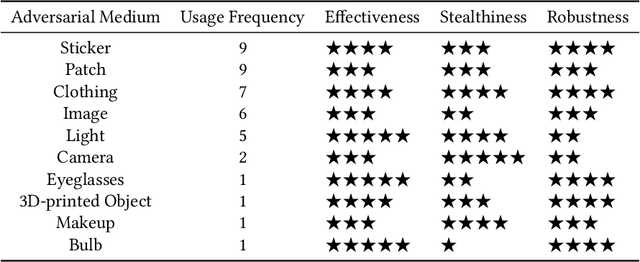
Although Deep Neural Networks (DNNs) have achieved impressive results in computer vision, their exposed vulnerability to adversarial attacks remains a serious concern. A series of works has shown that by adding elaborate perturbations to images, DNNs could have catastrophic degradation in performance metrics. And this phenomenon does not only exist in the digital space but also in the physical space. Therefore, estimating the security of these DNNs-based systems is critical for safely deploying them in the real world, especially for security-critical applications, e.g., autonomous cars, video surveillance, and medical diagnosis. In this paper, we focus on physical adversarial attacks and provide a comprehensive survey of over 150 existing papers. We first clarify the concept of the physical adversarial attack and analyze its characteristics. Then, we define the adversarial medium, essential to perform attacks in the physical world. Next, we present the physical adversarial attack methods in task order: classification, detection, and re-identification, and introduce their performance in solving the trilemma: effectiveness, stealthiness, and robustness. In the end, we discuss the current challenges and potential future directions.