 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Explanations for Belief-Desire-Intention Robots: When and What to Explain
Jul 02, 2025When robots perform complex and context-dependent tasks in our daily lives, deviations from expectations can confuse users. Explanations of the robot's reasoning process can help users to understand the robot intentions. However, when to provide explanations and what they contain are important to avoid user annoyance. We have investigated user preferences for explanation demand and content for a robot that helps with daily cleaning tasks in a kitchen. Our results show that users want explanations in surprising situations and prefer concise explanations that clearly state the intention behind the confusing action and the contextual factors that were relevant to this decision. Based on these findings, we propose two algorithms to identify surprising actions and to construct effective explanations for Belief-Desire-Intention (BDI) robots. Our algorithms can be easily integrated in the BDI reasoning process and pave the way for better human-robot interaction with context- and user-specific explanations.
Breaking Bad Molecules: Are MLLMs Ready for Structure-Level Molecular Detoxification?
Jun 12, 2025Toxicity remains a leading cause of early-stage drug development failure. Despite advances in molecular design and property prediction, the task of molecular toxicity repair - generating structurally valid molecular alternatives with reduced toxicity - has not yet been systematically defined or benchmarked. To fill this gap, we introduce ToxiMol, the first benchmark task for general-purpose Multimodal Large Language Models (MLLMs) focused on molecular toxicity repair. We construct a standardized dataset covering 11 primary tasks and 560 representative toxic molecules spanning diverse mechanisms and granularities. We design a prompt annotation pipeline with mechanism-aware and task-adaptive capabilities, informed by expert toxicological knowledge. In parallel, we propose an automated evaluation framework, ToxiEval, which integrates toxicity endpoint prediction, synthetic accessibility, drug-likeness, and structural similarity into a high-throughput evaluation chain for repair success. We systematically assess nearly 30 mainstream general-purpose MLLMs and design multiple ablation studies to analyze key factors such as evaluation criteria, candidate diversity, and failure attribution. Experimental results show that although current MLLMs still face significant challenges on this task, they begin to demonstrate promising capabilities in toxicity understanding, semantic constraint adherence, and structure-aware molecule editing.
HiBerNAC: Hierarchical Brain-emulated Robotic Neural Agent Collective for Disentangling Complex Manipulation
Jun 11, 2025



Recent advances in multimodal vision-language-action (VLA) models have revolutionized traditional robot learning, enabling systems to interpret vision, language, and action in unified frameworks for complex task planning. However, mastering complex manipulation tasks remains an open challenge, constrained by limitations in persistent contextual memory, multi-agent coordination under uncertainty, and dynamic long-horizon planning across variable sequences. To address this challenge, we propose \textbf{HiBerNAC}, a \textbf{Hi}erarchical \textbf{B}rain-\textbf{e}mulated \textbf{r}obotic \textbf{N}eural \textbf{A}gent \textbf{C}ollective, inspired by breakthroughs in neuroscience, particularly in neural circuit mechanisms and hierarchical decision-making. Our framework combines: (1) multimodal VLA planning and reasoning with (2) neuro-inspired reflection and multi-agent mechanisms, specifically designed for complex robotic manipulation tasks. By leveraging neuro-inspired functional modules with decentralized multi-agent collaboration, our approach enables robust and enhanced real-time execution of complex manipulation tasks. In addition, the agentic system exhibits scalable collective intelligence via dynamic agent specialization, adapting its coordination strategy to variable task horizons and complexity. Through extensive experiments on complex manipulation tasks compared with state-of-the-art VLA models, we demonstrate that \textbf{HiBerNAC} reduces average long-horizon task completion time by 23\%, and achieves non-zero success rates (12\textendash 31\%) on multi-path tasks where prior state-of-the-art VLA models consistently fail. These results provide indicative evidence for bridging biological cognition and robotic learning mechanisms.
RedRFT: A Light-Weight Benchmark for Reinforcement Fine-Tuning-Based Red Teaming
Jun 04, 2025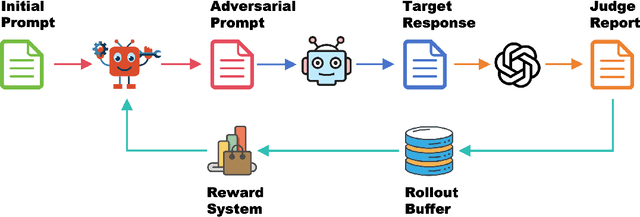

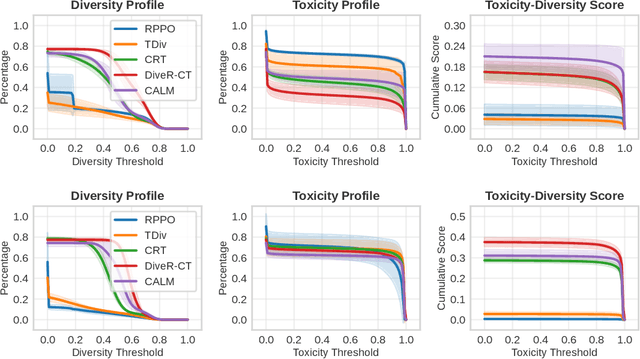
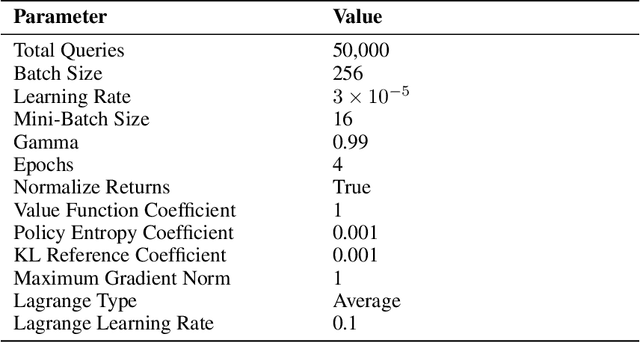
Red teaming has proven to be an effective method for identifying and mitigating vulnerabilities in Large Language Models (LLMs). Reinforcement Fine-Tuning (RFT) has emerged as a promising strategy among existing red teaming techniques. However, a lack of a unified benchmark hinders current RFT-based red teaming methods. Implementation details, especially in Proximal Policy Optimization (PPO)-based RFT, significantly affect outcome stability and reproducibility. To address this issue, we introduce RedRFT, a lightweight benchmark designed to simplify and standardize the implementation and evaluation of RFT-based red teaming. RedRFT combines the design strengths of both single-file CleanRL and highly modularized Tianshou, offering high-quality single-file red teaming implementations and modular PPO core components, such as the General Advantage Estimator. It supports a variety of token and sentence diversity metrics, featuring modularized intrinsic reward computation that facilitates plug-and-play experimentation. To clarify their influence on RFT performance, we conducted an extensive ablation study on key components, including Low-Rank Adaptation (LoRA), Kullback-Leibler (KL) divergence, and Lagrange Multiplier. We hope this work contributes to 1) gaining a comprehensive understanding of the implementation nuances of RFT-based red teaming algorithms, and 2) enabling rapid prototyping of innovative features for RFT-based red teaming. Code for the benchmark can be accessed at https://github.com/x-zheng16/RedRFT.git.
Deep Learning-Driven Ultra-High-Definition Image Restoration: A Survey
May 22, 2025Ultra-high-definition (UHD) image restoration aims to specifically solve the problem of quality degradation in ultra-high-resolution images. Recent advancements in this field are predominantly driven by deep learning-based innovations, including enhancements in dataset construction, network architecture, sampling strategies, prior knowledge integration, and loss functions. In this paper, we systematically review recent progress in UHD image restoration, covering various aspects ranging from dataset construction to algorithm design. This serves as a valuable resource for understanding state-of-the-art developments in the field. We begin by summarizing degradation models for various image restoration subproblems, such as super-resolution, low-light enhancement, deblurring, dehazing, deraining, and desnowing, and emphasizing the unique challenges of their application to UHD image restoration. We then highlight existing UHD benchmark datasets and organize the literature according to degradation types and dataset construction methods. Following this, we showcase major milestones in deep learning-driven UHD image restoration, reviewing the progression of restoration tasks, technological developments, and evaluations of existing methods. We further propose a classification framework based on network architectures and sampling strategies, helping to clearly organize existing methods. Finally, we share insights into the current research landscape and propose directions for further advancements. A related repository is available at https://github.com/wlydlut/UHD-Image-Restoration-Survey.
Contrastive Prompting Enhances Sentence Embeddings in LLMs through Inference-Time Steering
May 19, 2025Extracting sentence embeddings from large language models (LLMs) is a practical direction, as it requires neither additional data nor fine-tuning. Previous studies usually focus on prompt engineering to guide LLMs to encode the core semantic information of the sentence into the embedding of the last token. However, the last token in these methods still encodes an excess of non-essential information, such as stop words, limiting its encoding capacity. To this end, we propose a Contrastive Prompting (CP) method that introduces an extra auxiliary prompt to elicit better sentence embedding. By contrasting with the auxiliary prompt, CP can steer existing prompts to encode the core semantics of the sentence, rather than non-essential information. CP is a plug-and-play inference-time intervention method that can be combined with various prompt-based methods. Extensive experiments on Semantic Textual Similarity (STS) tasks and downstream classification tasks demonstrate that our method can improve the performance of existing prompt-based methods across different LLMs. Our code will be released at https://github.com/zifengcheng/CP.
Review-Instruct: A Review-Driven Multi-Turn Conversations Generation Method for Large Language Models
May 16, 2025



The effectiveness of large language models (LLMs) in conversational AI is hindered by their reliance on single-turn supervised fine-tuning (SFT) data, which limits contextual coherence in multi-turn dialogues. Existing methods for generating multi-turn dialogue data struggle to ensure both diversity and quality in instructions. To address this, we propose Review-Instruct, a novel framework that synthesizes multi-turn conversations through an iterative "Ask-Respond-Review" process involving three agent roles: a Candidate, multiple Reviewers, and a Chairman. The framework iteratively refines instructions by incorporating Reviewer feedback, enhancing dialogue diversity and difficulty. We construct a multi-turn dataset using the Alpaca dataset and fine-tune the LLaMA2-13B model. Evaluations on MT-Bench, MMLU-Pro, and Auto-Arena demonstrate significant improvements, achieving absolute gains of 2.9\% on MMLU-Pro and 2\% on MT-Bench compared to prior state-of-the-art models based on LLaMA2-13B. Ablation studies confirm the critical role of the Review stage and the use of multiple Reviewers in boosting instruction diversity and difficulty. Our work highlights the potential of review-driven, multi-agent frameworks for generating high-quality conversational data at scale.
IMAGGarment-1: Fine-Grained Garment Generation for Controllable Fashion Design
Apr 17, 2025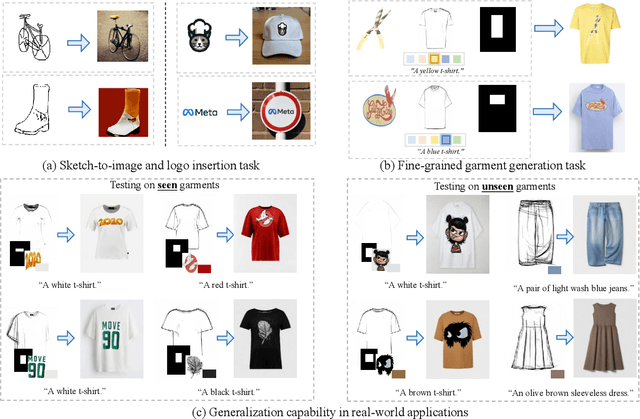
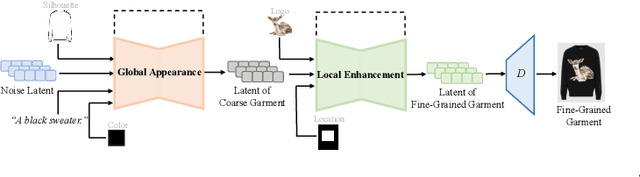
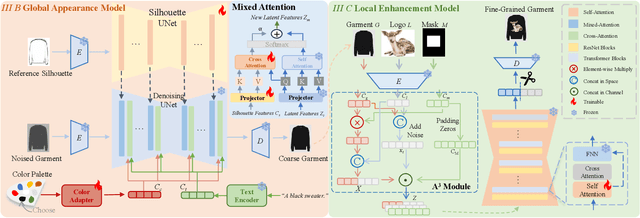

This paper presents IMAGGarment-1, a fine-grained garment generation (FGG) framework that enables high-fidelity garment synthesis with precise control over silhouette, color, and logo placement. Unlike existing methods that are limited to single-condition inputs, IMAGGarment-1 addresses the challenges of multi-conditional controllability in personalized fashion design and digital apparel applications. Specifically, IMAGGarment-1 employs a two-stage training strategy to separately model global appearance and local details, while enabling unified and controllable generation through end-to-end inference. In the first stage, we propose a global appearance model that jointly encodes silhouette and color using a mixed attention module and a color adapter. In the second stage, we present a local enhancement model with an adaptive appearance-aware module to inject user-defined logos and spatial constraints, enabling accurate placement and visual consistency. To support this task, we release GarmentBench, a large-scale dataset comprising over 180K garment samples paired with multi-level design conditions, including sketches, color references, logo placements, and textual prompts. Extensive experiments demonstrate that our method outperforms existing baselines, achieving superior structural stability, color fidelity, and local controllability performance. The code and model are available at https://github.com/muzishen/IMAGGarment-1.
ControlNET: A Firewall for RAG-based LLM System
Apr 13, 2025Retrieval-Augmented Generation (RAG) has significantly enhanced the factual accuracy and domain adaptability of Large Language Models (LLMs). This advancement has enabled their widespread deployment across sensitive domains such as healthcare, finance, and enterprise applications. RAG mitigates hallucinations by integrating external knowledge, yet introduces privacy risk and security risk, notably data breaching risk and data poisoning risk. While recent studies have explored prompt injection and poisoning attacks, there remains a significant gap in comprehensive research on controlling inbound and outbound query flows to mitigate these threats. In this paper, we propose an AI firewall, ControlNET, designed to safeguard RAG-based LLM systems from these vulnerabilities. ControlNET controls query flows by leveraging activation shift phenomena to detect adversarial queries and mitigate their impact through semantic divergence. We conduct comprehensive experiments on four different benchmark datasets including Msmarco, HotpotQA, FinQA, and MedicalSys using state-of-the-art open source LLMs (Llama3, Vicuna, and Mistral). Our results demonstrate that ControlNET achieves over 0.909 AUROC in detecting and mitigating security threats while preserving system harmlessness. Overall, ControlNET offers an effective, robust, harmless defense mechanism, marking a significant advancement toward the secure deployment of RAG-based LLM systems.
Scaling Laws of Scientific Discovery with AI and Robot Scientists
Mar 28, 2025



The rapid evolution of scientific inquiry highlights an urgent need for groundbreaking methodologies that transcend the limitations of traditional research. Conventional approaches, bogged down by manual processes and siloed expertise, struggle to keep pace with the demands of modern discovery. We envision an autonomous generalist scientist (AGS) system-a fusion of agentic AI and embodied robotics-that redefines the research lifecycle. This system promises to autonomously navigate physical and digital realms, weaving together insights from disparate disciplines with unprecedented efficiency. By embedding advanced AI and robot technologies into every phase-from hypothesis formulation to peer-ready manuscripts-AGS could slash the time and resources needed for scientific research in diverse field. We foresee a future where scientific discovery follows new scaling laws, driven by the proliferation and sophistication of such systems. As these autonomous agents and robots adapt to extreme environments and leverage a growing reservoir of knowledge, they could spark a paradigm shift, pushing the boundaries of what's possible and ushering in an era of relentless innovation.