 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Models Judge Themselves: Unsupervised Self-Evolution for Multimodal Reasoning
Mar 22, 2026Recent progress in multimodal large language models has led to strong performance on reasoning tasks, but these improvements largely rely on high-quality annotated data or teacher-model distillation, both of which are costly and difficult to scale.To address this, we propose an unsupervised self-evolution training framework for multimodal reasoning that achieves stable performance improvements without using human-annotated answers or external reward models. For each input, we sample multiple reasoning trajectories and jointly model their within group structure.We use the Actor's self-consistency signal as a training prior, and introduce a bounded Judge based modulation to continuously reweight trajectories of different quality.We further model the modulated scores as a group level distribution and convert absolute scores into relative advantages within each group, enabling more robust policy updates. Trained with Group Relative Policy Optimization (GRPO) on unlabeled data, our method consistently improves reasoning performance and generalization on five mathematical reasoning benchmarks, offering a scalable path toward self-evolving multimodal models.The code are available at https://dingwu1021.github.io/SelfJudge/.
UAQFact: Evaluating Factual Knowledge Utilization of LLMs on Unanswerable Questions
May 29, 2025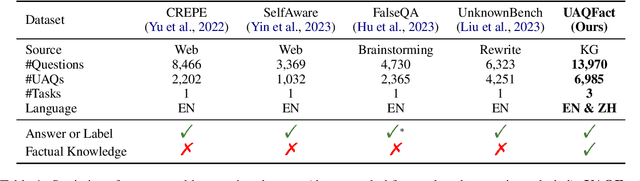



Handling unanswerable questions (UAQ) is crucial for LLMs, as it helps prevent misleading responses in complex situations. While previous studies have built several datasets to assess LLMs' performance on UAQ, these datasets lack factual knowledge support, which limits the evaluation of LLMs' ability to utilize their factual knowledge when handling UAQ. To address the limitation, we introduce a new unanswerable question dataset UAQFact, a bilingual dataset with auxiliary factual knowledge created from a Knowledge Graph. Based on UAQFact, we further define two new tasks to measure LLMs' ability to utilize internal and external factual knowledge, respectively. Our experimental results across multiple LLM series show that UAQFact presents significant challenges, as LLMs do not consistently perform well even when they have factual knowledge stored. Additionally, we find that incorporating external knowledge may enhance performance, but LLMs still cannot make full use of the knowledge which may result in incorrect responses.
Review-Instruct: A Review-Driven Multi-Turn Conversations Generation Method for Large Language Models
May 16, 2025



The effectiveness of large language models (LLMs) in conversational AI is hindered by their reliance on single-turn supervised fine-tuning (SFT) data, which limits contextual coherence in multi-turn dialogues. Existing methods for generating multi-turn dialogue data struggle to ensure both diversity and quality in instructions. To address this, we propose Review-Instruct, a novel framework that synthesizes multi-turn conversations through an iterative "Ask-Respond-Review" process involving three agent roles: a Candidate, multiple Reviewers, and a Chairman. The framework iteratively refines instructions by incorporating Reviewer feedback, enhancing dialogue diversity and difficulty. We construct a multi-turn dataset using the Alpaca dataset and fine-tune the LLaMA2-13B model. Evaluations on MT-Bench, MMLU-Pro, and Auto-Arena demonstrate significant improvements, achieving absolute gains of 2.9\% on MMLU-Pro and 2\% on MT-Bench compared to prior state-of-the-art models based on LLaMA2-13B. Ablation studies confirm the critical role of the Review stage and the use of multiple Reviewers in boosting instruction diversity and difficulty. Our work highlights the potential of review-driven, multi-agent frameworks for generating high-quality conversational data at scale.
Monadic Deep Learning
Jul 23, 2023The Java and Scala community has built a very successful big data ecosystem. However, most of neural networks running on it are modeled in dynamically typed programming languages. These dynamically typed deep learning frameworks treat neural networks as differentiable expressions that contain many trainable variable, and perform automatic differentiation on those expressions when training them. Until 2019, none of the learning frameworks in statically typed languages provided the expressive power of traditional frameworks. Their users are not able to use custom algorithms unless creating plenty of boilerplate code for hard-coded back-propagation. We solved this problem in DeepLearning.scala 2. Our contributions are: 1. We discovered a novel approach to perform automatic differentiation in reverse mode for statically typed functions that contain multiple trainable variable, and can interoperate freely with the metalanguage. 2. We designed a set of monads and monad transformers, which allow users to create monadic expressions that represent dynamic neural networks. 3. Along with these monads, we provide some applicative functors, to perform multiple calculations in parallel. With these features, users of DeepLearning.scala were able to create complex neural networks in an intuitive and concise way, and still maintain type safety.