 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlack-Box Guardrail Reverse-engineering Attack
Nov 06, 2025Large language models (LLMs) increasingly employ guardrails to enforce ethical, legal, and application-specific constraints on their outputs. While effective at mitigating harmful responses, these guardrails introduce a new class of vulnerabilities by exposing observable decision patterns. In this work, we present the first study of black-box LLM guardrail reverse-engineering attacks. We propose Guardrail Reverse-engineering Attack (GRA), a reinforcement learning-based framework that leverages genetic algorithm-driven data augmentation to approximate the decision-making policy of victim guardrails. By iteratively collecting input-output pairs, prioritizing divergence cases, and applying targeted mutations and crossovers, our method incrementally converges toward a high-fidelity surrogate of the victim guardrail. We evaluate GRA on three widely deployed commercial systems, namely ChatGPT, DeepSeek, and Qwen3, and demonstrate that it achieves an rule matching rate exceeding 0.92 while requiring less than $85 in API costs. These findings underscore the practical feasibility of guardrail extraction and highlight significant security risks for current LLM safety mechanisms. Our findings expose critical vulnerabilities in current guardrail designs and highlight the urgent need for more robust defense mechanisms in LLM deployment.
SoK: Large Language Model Copyright Auditing via Fingerprinting
Aug 27, 2025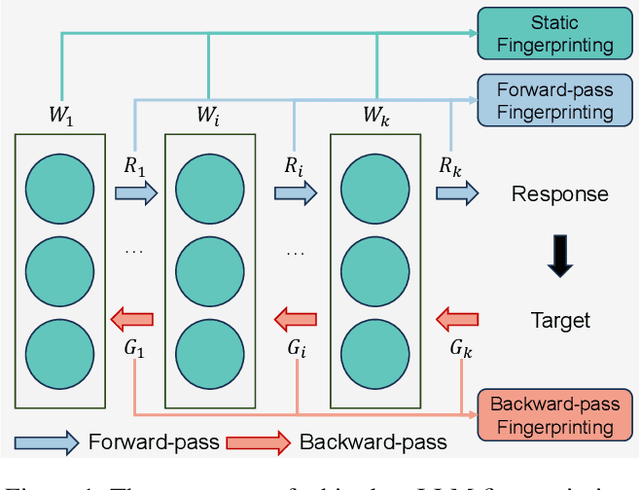

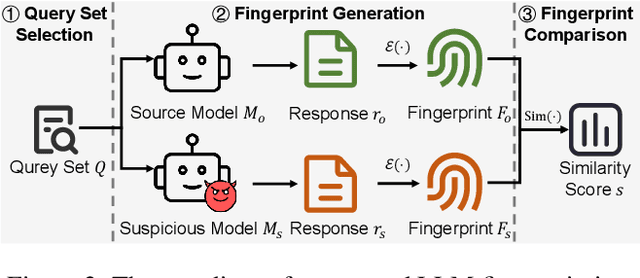

The broad capabilities and substantial resources required to train Large Language Models (LLMs) make them valuable intellectual property, yet they remain vulnerable to copyright infringement, such as unauthorized use and model theft. LLM fingerprinting, a non-intrusive technique that extracts and compares the distinctive features from LLMs to identify infringements, offers a promising solution to copyright auditing. However, its reliability remains uncertain due to the prevalence of diverse model modifications and the lack of standardized evaluation. In this SoK, we present the first comprehensive study of LLM fingerprinting. We introduce a unified framework and formal taxonomy that categorizes existing methods into white-box and black-box approaches, providing a structured overview of the state of the art. We further propose LeaFBench, the first systematic benchmark for evaluating LLM fingerprinting under realistic deployment scenarios. Built upon mainstream foundation models and comprising 149 distinct model instances, LeaFBench integrates 13 representative post-development techniques, spanning both parameter-altering methods (e.g., fine-tuning, quantization) and parameter-independent mechanisms (e.g., system prompts, RAG). Extensive experiments on LeaFBench reveal the strengths and weaknesses of existing methods, thereby outlining future research directions and critical open problems in this emerging field. The code is available at https://github.com/shaoshuo-ss/LeaFBench.
Quantifying Conversation Drift in MCP via Latent Polytope
Aug 08, 2025The Model Context Protocol (MCP) enhances large language models (LLMs) by integrating external tools, enabling dynamic aggregation of real-time data to improve task execution. However, its non-isolated execution context introduces critical security and privacy risks. In particular, adversarially crafted content can induce tool poisoning or indirect prompt injection, leading to conversation hijacking, misinformation propagation, or data exfiltration. Existing defenses, such as rule-based filters or LLM-driven detection, remain inadequate due to their reliance on static signatures, computational inefficiency, and inability to quantify conversational hijacking. To address these limitations, we propose SecMCP, a secure framework that detects and quantifies conversation drift, deviations in latent space trajectories induced by adversarial external knowledge. By modeling LLM activation vectors within a latent polytope space, SecMCP identifies anomalous shifts in conversational dynamics, enabling proactive detection of hijacking, misleading, and data exfiltration. We evaluate SecMCP on three state-of-the-art LLMs (Llama3, Vicuna, Mistral) across benchmark datasets (MS MARCO, HotpotQA, FinQA), demonstrating robust detection with AUROC scores exceeding 0.915 while maintaining system usability. Our contributions include a systematic categorization of MCP security threats, a novel latent polytope-based methodology for quantifying conversation drift, and empirical validation of SecMCP's efficacy.
ControlNET: A Firewall for RAG-based LLM System
Apr 13, 2025Retrieval-Augmented Generation (RAG) has significantly enhanced the factual accuracy and domain adaptability of Large Language Models (LLMs). This advancement has enabled their widespread deployment across sensitive domains such as healthcare, finance, and enterprise applications. RAG mitigates hallucinations by integrating external knowledge, yet introduces privacy risk and security risk, notably data breaching risk and data poisoning risk. While recent studies have explored prompt injection and poisoning attacks, there remains a significant gap in comprehensive research on controlling inbound and outbound query flows to mitigate these threats. In this paper, we propose an AI firewall, ControlNET, designed to safeguard RAG-based LLM systems from these vulnerabilities. ControlNET controls query flows by leveraging activation shift phenomena to detect adversarial queries and mitigate their impact through semantic divergence. We conduct comprehensive experiments on four different benchmark datasets including Msmarco, HotpotQA, FinQA, and MedicalSys using state-of-the-art open source LLMs (Llama3, Vicuna, and Mistral). Our results demonstrate that ControlNET achieves over 0.909 AUROC in detecting and mitigating security threats while preserving system harmlessness. Overall, ControlNET offers an effective, robust, harmless defense mechanism, marking a significant advancement toward the secure deployment of RAG-based LLM systems.
FIT-Print: Towards False-claim-resistant Model Ownership Verification via Targeted Fingerprint
Jan 26, 2025Model fingerprinting is a widely adopted approach to safeguard the intellectual property rights of open-source models by preventing their unauthorized reuse. It is promising and convenient since it does not necessitate modifying the protected model. In this paper, we revisit existing fingerprinting methods and reveal that they are vulnerable to false claim attacks where adversaries falsely assert ownership of any third-party model. We demonstrate that this vulnerability mostly stems from their untargeted nature, where they generally compare the outputs of given samples on different models instead of the similarities to specific references. Motivated by these findings, we propose a targeted fingerprinting paradigm (i.e., FIT-Print) to counteract false claim attacks. Specifically, FIT-Print transforms the fingerprint into a targeted signature via optimization. Building on the principles of FIT-Print, we develop bit-wise and list-wise black-box model fingerprinting methods, i.e., FIT-ModelDiff and FIT-LIME, which exploit the distance between model outputs and the feature attribution of specific samples as the fingerprint, respectively. Extensive experiments on benchmark models and datasets verify the effectiveness, conferrability, and resistance to false claim attacks of our FIT-Print.
Mitigating Privacy Risks in LLM Embeddings from Embedding Inversion
Nov 06, 2024



Embeddings have become a cornerstone in the functionality of large language models (LLMs) due to their ability to transform text data into rich, dense numerical representations that capture semantic and syntactic properties. These embedding vector databases serve as the long-term memory of LLMs, enabling efficient handling of a wide range of natural language processing tasks. However, the surge in popularity of embedding vector databases in LLMs has been accompanied by significant concerns about privacy leakage. Embedding vector databases are particularly vulnerable to embedding inversion attacks, where adversaries can exploit the embeddings to reverse-engineer and extract sensitive information from the original text data. Existing defense mechanisms have shown limitations, often struggling to balance security with the performance of downstream tasks. To address these challenges, we introduce Eguard, a novel defense mechanism designed to mitigate embedding inversion attacks. Eguard employs a transformer-based projection network and text mutual information optimization to safeguard embeddings while preserving the utility of LLMs. Our approach significantly reduces privacy risks, protecting over 95% of tokens from inversion while maintaining high performance across downstream tasks consistent with original embeddings.
TAPI: Towards Target-Specific and Adversarial Prompt Injection against Code LLMs
Jul 12, 2024



Recently, code-oriented large language models (Code LLMs) have been widely and successfully used to simplify and facilitate code programming. With these tools, developers can easily generate desired complete functional codes based on incomplete code and natural language prompts. However, a few pioneering works revealed that these Code LLMs are also vulnerable, e.g., against backdoor and adversarial attacks. The former could induce LLMs to respond to triggers to insert malicious code snippets by poisoning the training data or model parameters, while the latter can craft malicious adversarial input codes to reduce the quality of generated codes. However, both attack methods have underlying limitations: backdoor attacks rely on controlling the model training process, while adversarial attacks struggle with fulfilling specific malicious purposes. To inherit the advantages of both backdoor and adversarial attacks, this paper proposes a new attack paradigm, i.e., target-specific and adversarial prompt injection (TAPI), against Code LLMs. TAPI generates unreadable comments containing information about malicious instructions and hides them as triggers in the external source code. When users exploit Code LLMs to complete codes containing the trigger, the models will generate attacker-specified malicious code snippets at specific locations. We evaluate our TAPI attack on four representative LLMs under three representative malicious objectives and seven cases. The results show that our method is highly threatening (achieving an attack success rate of up to 89.3\%) and stealthy (saving an average of 53.1\% of tokens in the trigger design). In particular, we successfully attack some famous deployed code completion integrated applications, including CodeGeex and Github Copilot. This further confirms the realistic threat of our attack.
Explanation as a Watermark: Towards Harmless and Multi-bit Model Ownership Verification via Watermarking Feature Attribution
May 08, 2024



Ownership verification is currently the most critical and widely adopted post-hoc method to safeguard model copyright. In general, model owners exploit it to identify whether a given suspicious third-party model is stolen from them by examining whether it has particular properties `inherited' from their released models. Currently, backdoor-based model watermarks are the primary and cutting-edge methods to implant such properties in the released models. However, backdoor-based methods have two fatal drawbacks, including harmfulness and ambiguity. The former indicates that they introduce maliciously controllable misclassification behaviors ($i.e.$, backdoor) to the watermarked released models. The latter denotes that malicious users can easily pass the verification by finding other misclassified samples, leading to ownership ambiguity. In this paper, we argue that both limitations stem from the `zero-bit' nature of existing watermarking schemes, where they exploit the status ($i.e.$, misclassified) of predictions for verification. Motivated by this understanding, we design a new watermarking paradigm, $i.e.$, Explanation as a Watermark (EaaW), that implants verification behaviors into the explanation of feature attribution instead of model predictions. Specifically, EaaW embeds a `multi-bit' watermark into the feature attribution explanation of specific trigger samples without changing the original prediction. We correspondingly design the watermark embedding and extraction algorithms inspired by explainable artificial intelligence. In particular, our approach can be used for different tasks ($e.g.$, image classification and text generation). Extensive experiments verify the effectiveness and harmlessness of our EaaW and its resistance to potential attacks.
PoisonPrompt: Backdoor Attack on Prompt-based Large Language Models
Oct 19, 2023



Prompts have significantly improved the performance of pretrained Large Language Models (LLMs) on various downstream tasks recently, making them increasingly indispensable for a diverse range of LLM application scenarios. However, the backdoor vulnerability, a serious security threat that can maliciously alter the victim model's normal predictions, has not been sufficiently explored for prompt-based LLMs. In this paper, we present POISONPROMPT, a novel backdoor attack capable of successfully compromising both hard and soft prompt-based LLMs. We evaluate the effectiveness, fidelity, and robustness of POISONPROMPT through extensive experiments on three popular prompt methods, using six datasets and three widely used LLMs. Our findings highlight the potential security threats posed by backdoor attacks on prompt-based LLMs and emphasize the need for further research in this area.
RemovalNet: DNN Fingerprint Removal Attacks
Aug 31, 2023With the performance of deep neural networks (DNNs) remarkably improving, DNNs have been widely used in many areas. Consequently, the DNN model has become a valuable asset, and its intellectual property is safeguarded by ownership verification techniques (e.g., DNN fingerprinting). However, the feasibility of the DNN fingerprint removal attack and its potential influence remains an open problem. In this paper, we perform the first comprehensive investigation of DNN fingerprint removal attacks. Generally, the knowledge contained in a DNN model can be categorized into general semantic and fingerprint-specific knowledge. To this end, we propose a min-max bilevel optimization-based DNN fingerprint removal attack named RemovalNet, to evade model ownership verification. The lower-level optimization is designed to remove fingerprint-specific knowledge. While in the upper-level optimization, we distill the victim model's general semantic knowledge to maintain the surrogate model's performance. We conduct extensive experiments to evaluate the fidelity, effectiveness, and efficiency of the RemovalNet against four advanced defense methods on six metrics. The empirical results demonstrate that (1) the RemovalNet is effective. After our DNN fingerprint removal attack, the model distance between the target and surrogate models is x100 times higher than that of the baseline attacks, (2) the RemovalNet is efficient. It uses only 0.2% (400 samples) of the substitute dataset and 1,000 iterations to conduct our attack. Besides, compared with advanced model stealing attacks, the RemovalNet saves nearly 85% of computational resources at most, (3) the RemovalNet achieves high fidelity that the created surrogate model maintains high accuracy after the DNN fingerprint removal process. Our code is available at: https://github.com/grasses/RemovalNet.