 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReview-Instruct: A Review-Driven Multi-Turn Conversations Generation Method for Large Language Models
May 16, 2025



The effectiveness of large language models (LLMs) in conversational AI is hindered by their reliance on single-turn supervised fine-tuning (SFT) data, which limits contextual coherence in multi-turn dialogues. Existing methods for generating multi-turn dialogue data struggle to ensure both diversity and quality in instructions. To address this, we propose Review-Instruct, a novel framework that synthesizes multi-turn conversations through an iterative "Ask-Respond-Review" process involving three agent roles: a Candidate, multiple Reviewers, and a Chairman. The framework iteratively refines instructions by incorporating Reviewer feedback, enhancing dialogue diversity and difficulty. We construct a multi-turn dataset using the Alpaca dataset and fine-tune the LLaMA2-13B model. Evaluations on MT-Bench, MMLU-Pro, and Auto-Arena demonstrate significant improvements, achieving absolute gains of 2.9\% on MMLU-Pro and 2\% on MT-Bench compared to prior state-of-the-art models based on LLaMA2-13B. Ablation studies confirm the critical role of the Review stage and the use of multiple Reviewers in boosting instruction diversity and difficulty. Our work highlights the potential of review-driven, multi-agent frameworks for generating high-quality conversational data at scale.
Low-Resource Named Entity Recognition Based on Multi-hop Dependency Trigger
Sep 15, 2021
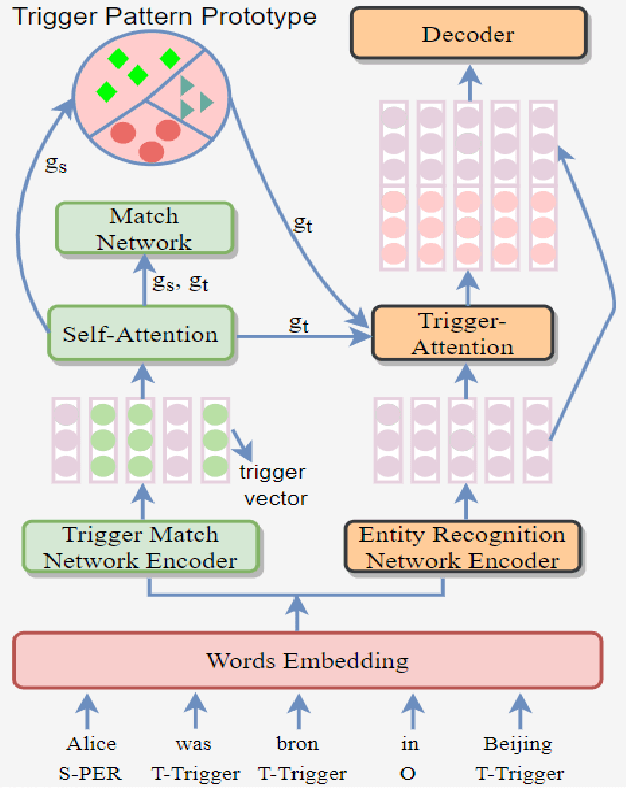


This paper presents a simple and effective approach in low-resource named entity recognition (NER) based on multi-hop dependency trigger. Dependency trigger refer to salient nodes relative to a entity in the dependency graph of a context sentence. Our main observation is that there often exists trigger which play an important role to recognize the location and type of entity in sentence. Previous research has used manual labelling of trigger. Our main contribution is to propose use a syntactic parser to automatically annotate trigger. Experiments on two English datasets (CONLL 2003 and BC5CDR) show that the proposed method is comparable to the previous trigger-based NER model.