 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSYNERGY: Building Task Bots at Scale Using Symbolic Knowledge and Machine Teaching
Oct 21, 2021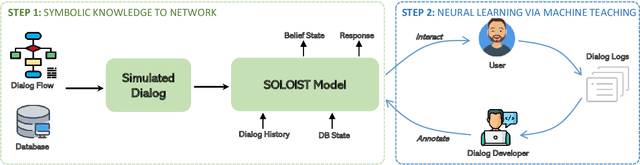

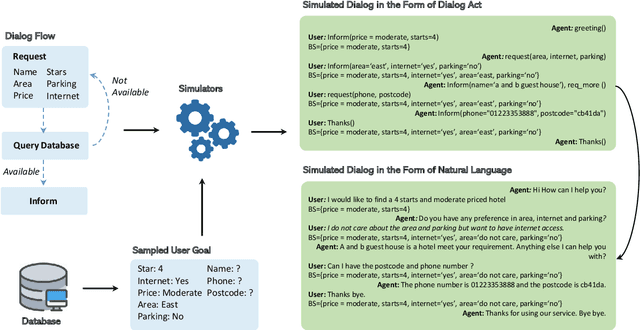
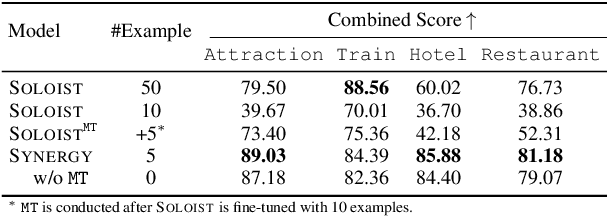
In this paper we explore the use of symbolic knowledge and machine teaching to reduce human data labeling efforts in building neural task bots. We propose SYNERGY, a hybrid learning framework where a task bot is developed in two steps: (i) Symbolic knowledge to neural networks: Large amounts of simulated dialog sessions are generated based on task-specific symbolic knowledge which is represented as a task schema consisting of dialog flows and task-oriented databases. Then a pre-trained neural dialog model, SOLOIST, is fine-tuned on the simulated dialogs to build a bot for the task. (ii) Neural learning: The fine-tuned neural dialog model is continually refined with a handful of real task-specific dialogs via machine teaching, where training samples are generated by human teachers interacting with the task bot. We validate SYNERGY on four dialog tasks. Experimental results show that SYNERGY maps task-specific knowledge into neural dialog models achieving greater diversity and coverage of dialog flows, and continually improves model performance with machine teaching, thus demonstrating strong synergistic effects of symbolic knowledge and machine teaching.
Focal Self-attention for Local-Global Interactions in Vision Transformers
Jul 01, 2021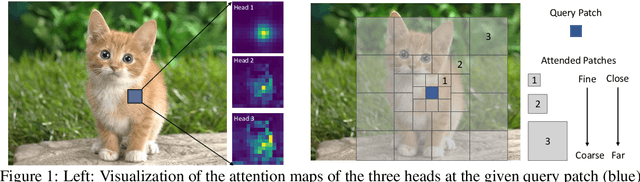
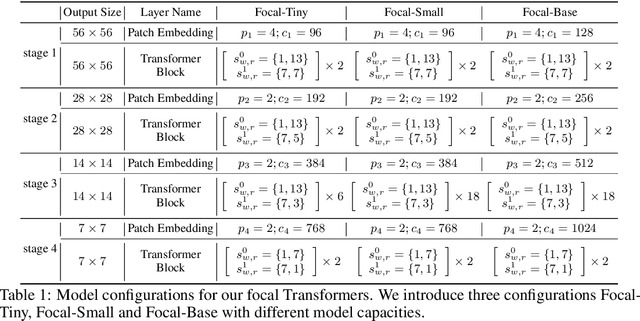
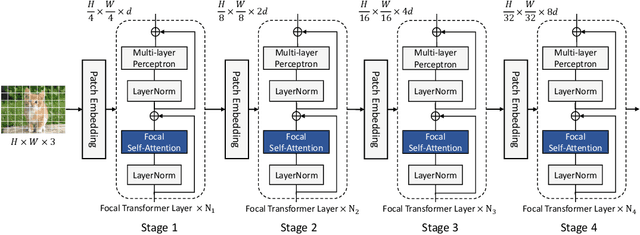
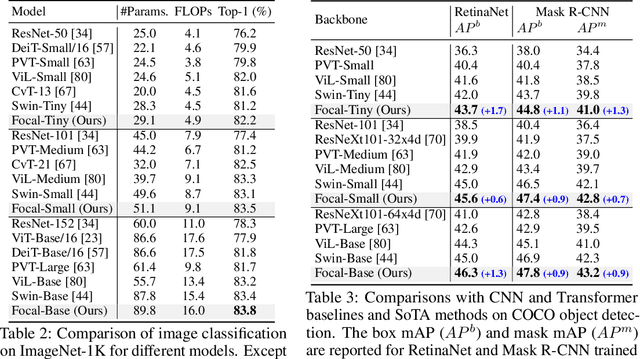
Recently, Vision Transformer and its variants have shown great promise on various computer vision tasks. The ability of capturing short- and long-range visual dependencies through self-attention is arguably the main source for the success. But it also brings challenges due to quadratic computational overhead, especially for the high-resolution vision tasks (e.g., object detection). In this paper, we present focal self-attention, a new mechanism that incorporates both fine-grained local and coarse-grained global interactions. Using this new mechanism, each token attends the closest surrounding tokens at fine granularity but the tokens far away at coarse granularity, and thus can capture both short- and long-range visual dependencies efficiently and effectively. With focal self-attention, we propose a new variant of Vision Transformer models, called Focal Transformer, which achieves superior performance over the state-of-the-art vision Transformers on a range of public image classification and object detection benchmarks. In particular, our Focal Transformer models with a moderate size of 51.1M and a larger size of 89.8M achieve 83.5 and 83.8 Top-1 accuracy, respectively, on ImageNet classification at 224x224 resolution. Using Focal Transformers as the backbones, we obtain consistent and substantial improvements over the current state-of-the-art Swin Transformers for 6 different object detection methods trained with standard 1x and 3x schedules. Our largest Focal Transformer yields 58.7/58.9 box mAPs and 50.9/51.3 mask mAPs on COCO mini-val/test-dev, and 55.4 mIoU on ADE20K for semantic segmentation, creating new SoTA on three of the most challenging computer vision tasks.
Efficient Self-supervised Vision Transformers for Representation Learning
Jun 17, 2021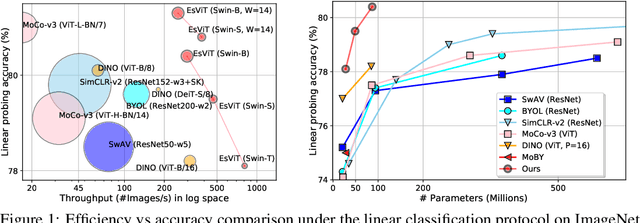
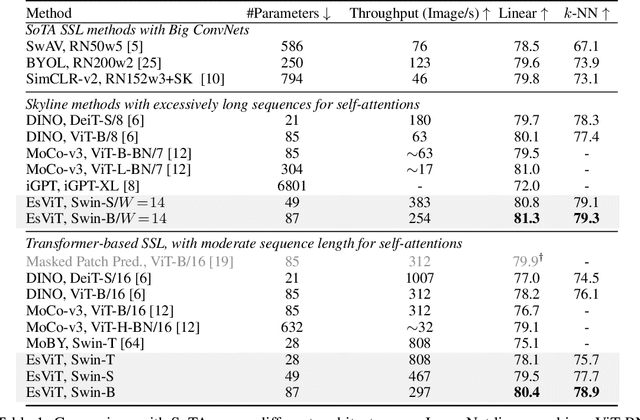
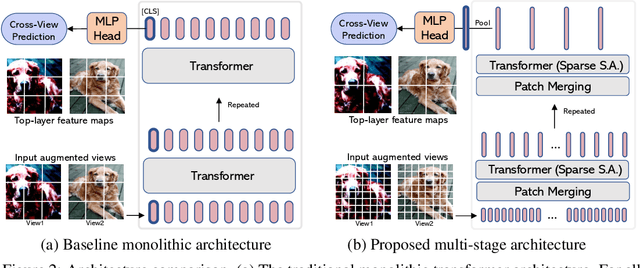

This paper investigates two techniques for developing efficient self-supervised vision transformers (EsViT) for visual representation learning. First, we show through a comprehensive empirical study that multi-stage architectures with sparse self-attentions can significantly reduce modeling complexity but with a cost of losing the ability to capture fine-grained correspondences between image regions. Second, we propose a new pre-training task of region matching which allows the model to capture fine-grained region dependencies and as a result significantly improves the quality of the learned vision representations. Our results show that combining the two techniques, EsViT achieves 81.3% top-1 on the ImageNet linear probe evaluation, outperforming prior arts with around an order magnitude of higher throughput. When transferring to downstream linear classification tasks, EsViT outperforms its supervised counterpart on 17 out of 18 datasets. The code and models will be publicly available.
Exploring Robustness of Unsupervised Domain Adaptation in Semantic Segmentation
May 23, 2021
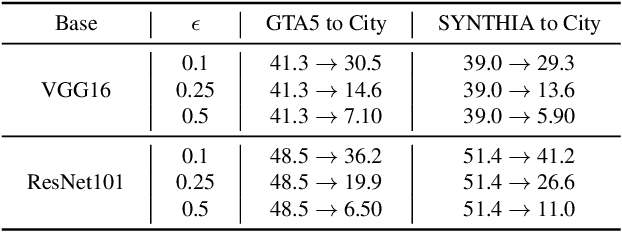
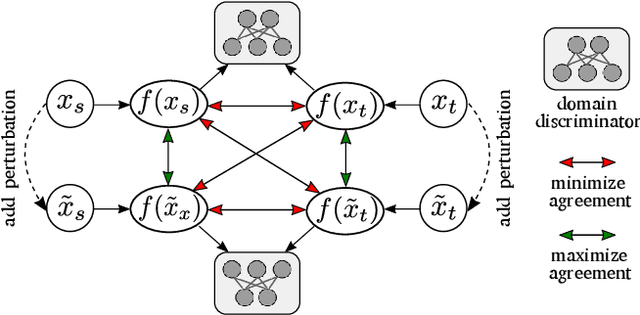
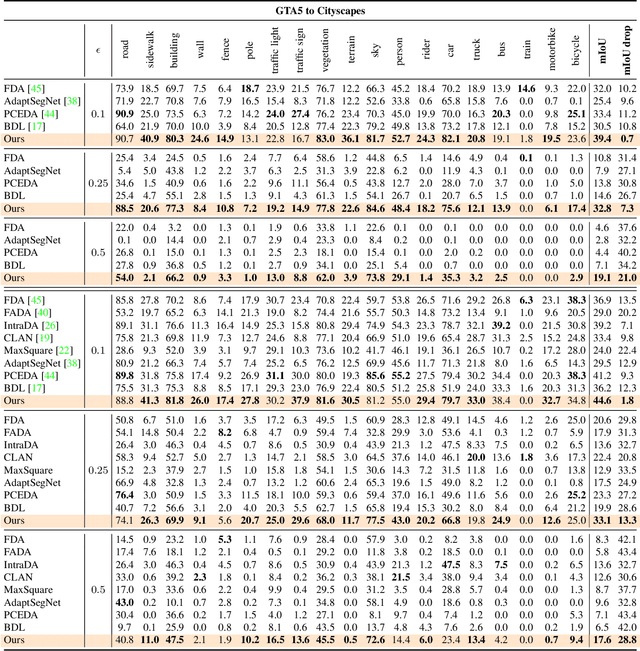
Recent studies imply that deep neural networks are vulnerable to adversarial examples -- inputs with a slight but intentional perturbation are incorrectly classified by the network. Such vulnerability makes it risky for some security-related applications (e.g., semantic segmentation in autonomous cars) and triggers tremendous concerns on the model reliability. For the first time, we comprehensively evaluate the robustness of existing UDA methods and propose a robust UDA approach. It is rooted in two observations: (i) the robustness of UDA methods in semantic segmentation remains unexplored, which pose a security concern in this field; and (ii) although commonly used self-supervision (e.g., rotation and jigsaw) benefits image tasks such as classification and recognition, they fail to provide the critical supervision signals that could learn discriminative representation for segmentation tasks. These observations motivate us to propose adversarial self-supervision UDA (or ASSUDA) that maximizes the agreement between clean images and their adversarial examples by a contrastive loss in the output space. Extensive empirical studies on commonly used benchmarks demonstrate that ASSUDA is resistant to adversarial attacks.
Contrastive Conditional Transport for Representation Learning
May 08, 2021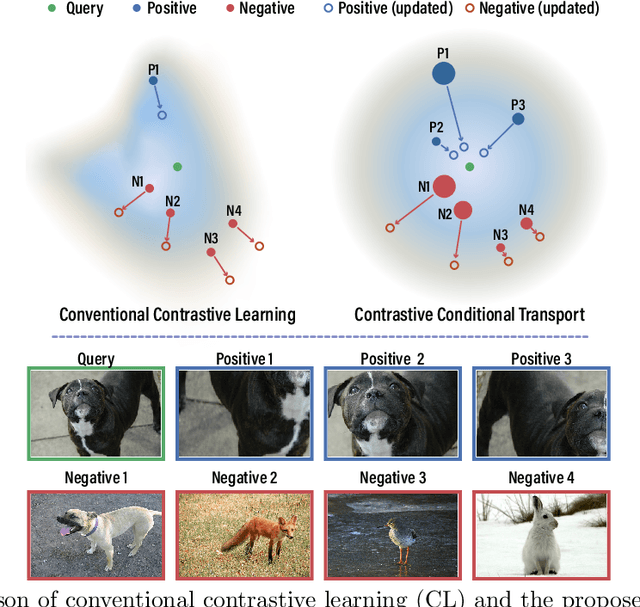
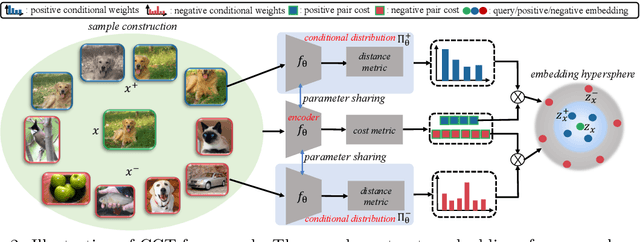
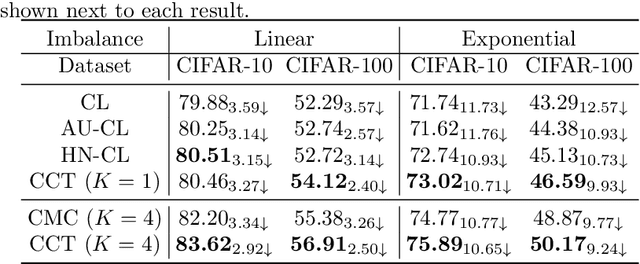
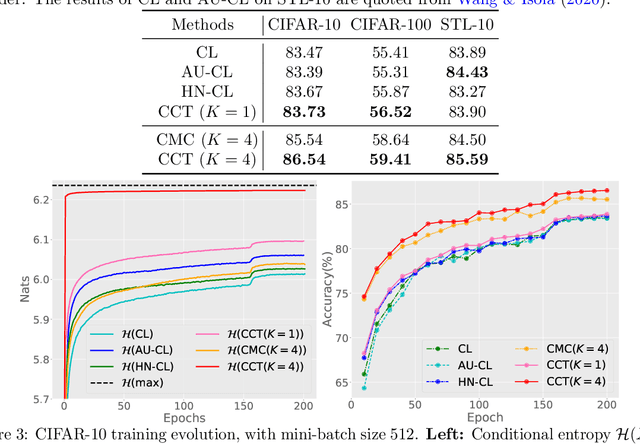
Contrastive learning (CL) has achieved remarkable success in learning data representations without label supervision. However, the conventional CL loss is sensitive to how many negative samples are included and how they are selected. This paper proposes contrastive conditional transport (CCT) that defines its CL loss over dependent sample-query pairs, which in practice is realized by drawing a random query, randomly selecting positive and negative samples, and contrastively reweighting these samples according to their distances to the query, exerting a greater force to both pull more distant positive samples towards the query and push closer negative samples away from the query. Theoretical analysis shows that this unique contrastive reweighting scheme helps in the representation space to both align the positive samples with the query and reduce the mutual information between the negative sample and query. Extensive large-scale experiments on standard vision tasks show that CCT not only consistently outperforms existing methods on benchmark datasets in contrastive representation learning but also provides interpretable contrastive weights and latent representations. PyTorch code will be provided.
Partition-Guided GANs
Apr 02, 2021
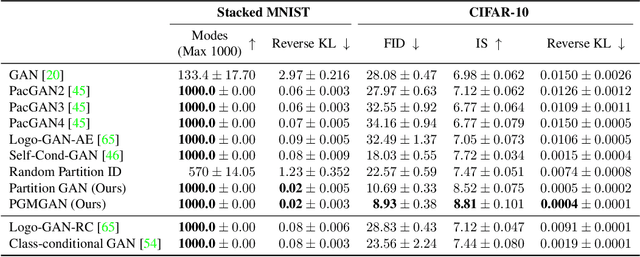
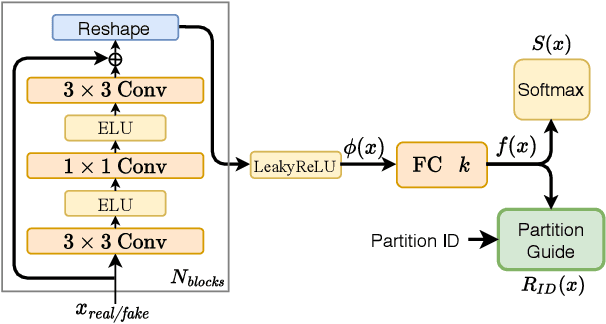

Despite the success of Generative Adversarial Networks (GANs), their training suffers from several well-known problems, including mode collapse and difficulties learning a disconnected set of manifolds. In this paper, we break down the challenging task of learning complex high dimensional distributions, supporting diverse data samples, to simpler sub-tasks. Our solution relies on designing a partitioner that breaks the space into smaller regions, each having a simpler distribution, and training a different generator for each partition. This is done in an unsupervised manner without requiring any labels. We formulate two desired criteria for the space partitioner that aid the training of our mixture of generators: 1) to produce connected partitions and 2) provide a proxy of distance between partitions and data samples, along with a direction for reducing that distance. These criteria are developed to avoid producing samples from places with non-existent data density, and also facilitate training by providing additional direction to the generators. We develop theoretical constraints for a space partitioner to satisfy the above criteria. Guided by our theoretical analysis, we design an effective neural architecture for the space partitioner that empirically assures these conditions. Experimental results on various standard benchmarks show that the proposed unsupervised model outperforms several recent methods.
Leveraging User Behavior History for Personalized Email Search
Mar 17, 2021
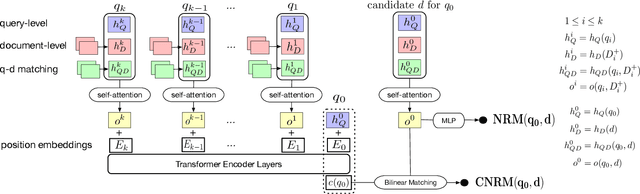
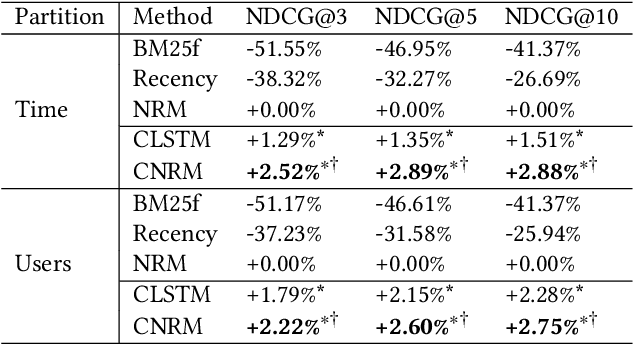
An effective email search engine can facilitate users' search tasks and improve their communication efficiency. Users could have varied preferences on various ranking signals of an email, such as relevance and recency based on their tasks at hand and even their jobs. Thus a uniform matching pattern is not optimal for all users. Instead, an effective email ranker should conduct personalized ranking by taking users' characteristics into account. Existing studies have explored user characteristics from various angles to make email search results personalized. However, little attention has been given to users' search history for characterizing users. Although users' historical behaviors have been shown to be beneficial as context in Web search, their effect in email search has not been studied and remains unknown. Given these observations, we propose to leverage user search history as query context to characterize users and build a context-aware ranking model for email search. In contrast to previous context-dependent ranking techniques that are based on raw texts, we use ranking features in the search history. This frees us from potential privacy leakage while giving a better generalization power to unseen users. Accordingly, we propose a context-dependent neural ranking model (CNRM) that encodes the ranking features in users' search history as query context and show that it can significantly outperform the baseline neural model without using the context. We also investigate the benefit of the query context vectors obtained from CNRM on the state-of-the-art learning-to-rank model LambdaMart by clustering the vectors and incorporating the cluster information. Experimental results show that significantly better results can be achieved on LambdaMart as well, indicating that the query clusters can characterize different users and effectively turn the ranking model personalized.
Self-supervised Pre-training with Hard Examples Improves Visual Representations
Jan 04, 2021
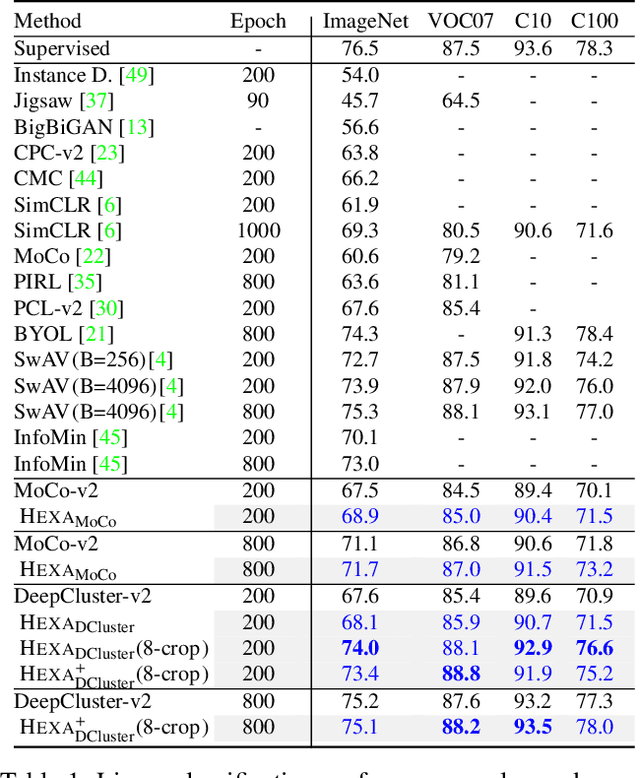
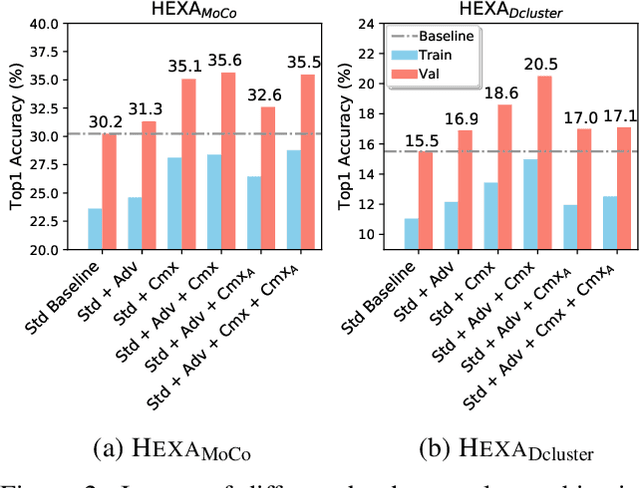
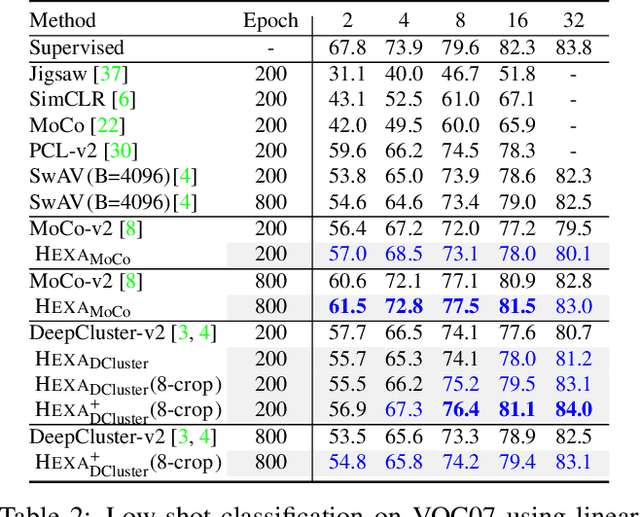
Self-supervised pre-training (SSP) employs random image transformations to generate training data for visual representation learning. In this paper, we first present a modeling framework that unifies existing SSP methods as learning to predict pseudo-labels. Then, we propose new data augmentation methods of generating training examples whose pseudo-labels are harder to predict than those generated via random image transformations. Specifically, we use adversarial training and CutMix to create hard examples (HEXA) to be used as augmented views for MoCo-v2 and DeepCluster-v2, leading to two variants HEXA_{MoCo} and HEXA_{DCluster}, respectively. In our experiments, we pre-train models on ImageNet and evaluate them on multiple public benchmarks. Our evaluation shows that the two new algorithm variants outperform their original counterparts, and achieve new state-of-the-art on a wide range of tasks where limited task supervision is available for fine-tuning. These results verify that hard examples are instrumental in improving the generalization of the pre-trained models.
SDA: Improving Text Generation with Self Data Augmentation
Jan 02, 2021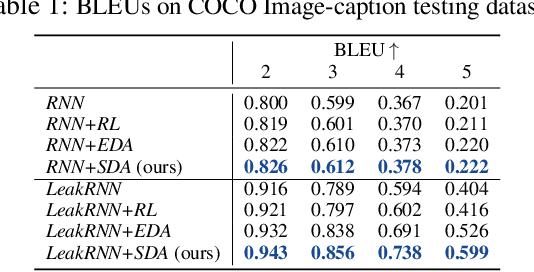
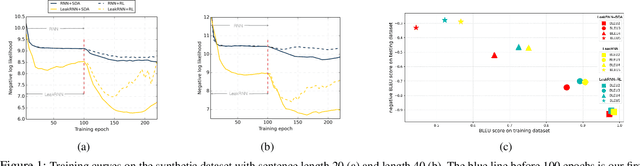
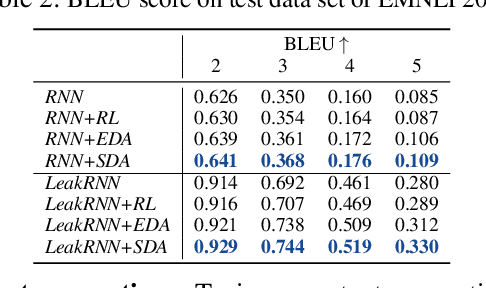

Data augmentation has been widely used to improve deep neural networks in many research fields, such as computer vision. However, less work has been done in the context of text, partially due to its discrete nature and the complexity of natural languages. In this paper, we propose to improve the standard maximum likelihood estimation (MLE) paradigm by incorporating a self-imitation-learning phase for automatic data augmentation. Unlike most existing sentence-level augmentation strategies, which are only applied to specific models, our method is more general and could be easily adapted to any MLE-based training procedure. In addition, our framework allows task-specific evaluation metrics to be designed to flexibly control the generated sentences, for example, in terms of controlling vocabulary usage and avoiding nontrivial repetitions. Extensive experimental results demonstrate the superiority of our method on two synthetic and several standard real datasets, significantly improving related baselines.
Few-Shot Named Entity Recognition: A Comprehensive Study
Dec 29, 2020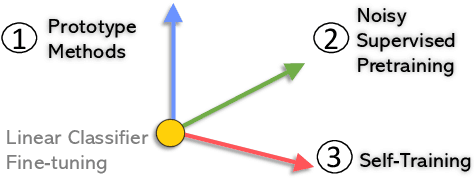

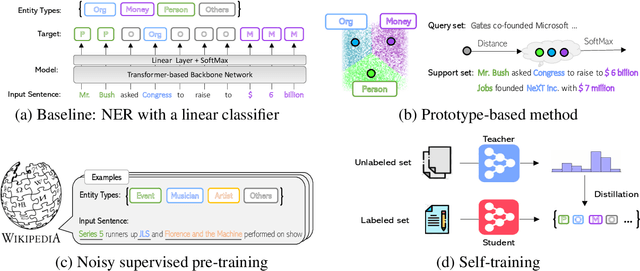
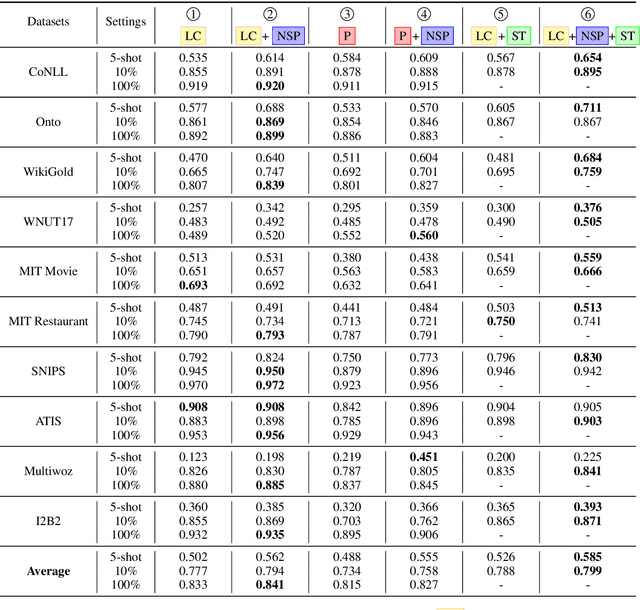
This paper presents a comprehensive study to efficiently build named entity recognition (NER) systems when a small number of in-domain labeled data is available. Based upon recent Transformer-based self-supervised pre-trained language models (PLMs), we investigate three orthogonal schemes to improve the model generalization ability for few-shot settings: (1) meta-learning to construct prototypes for different entity types, (2) supervised pre-training on noisy web data to extract entity-related generic representations and (3) self-training to leverage unlabeled in-domain data. Different combinations of these schemes are also considered. We perform extensive empirical comparisons on 10 public NER datasets with various proportions of labeled data, suggesting useful insights for future research. Our experiments show that (i) in the few-shot learning setting, the proposed NER schemes significantly improve or outperform the commonly used baseline, a PLM-based linear classifier fine-tuned on domain labels; (ii) We create new state-of-the-art results on both few-shot and training-free settings compared with existing methods. We will release our code and pre-trained models for reproducible research.