 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Vision-Language Models Solve the Shell Game?
Mar 09, 2026Visual entity tracking is an innate cognitive ability in humans, yet it remains a critical bottleneck for Vision-Language Models (VLMs). This deficit is often obscured in existing video benchmarks by visual shortcuts. We introduce VET-Bench, a synthetic diagnostic testbed featuring visually identical objects that necessitate tracking exclusively through spatiotemporal continuity. Our experiments reveal that current state-of-the-art VLMs perform at or near chance level on VET-Bench, exposing a fundamental limitation: an over-reliance on static frame-level features and a failure to maintain entity representations over time. We provide a theoretical analysis drawing connections to the state-tracking problem, proving that fixed-depth transformer-based VLMs are fundamentally limited in tracking indistinguishable objects without intermediate supervision due to expressivity constraints. To address this, we propose Spatiotemporal Grounded Chain-of-Thought (SGCoT): generating object trajectories as explicit intermediate states. Leveraging Molmo2's object tracking ability, we elicit SGCoT reasoning by fine-tuning on synthesized text-only data for alignment. Our method achieves state-of-the-art accuracy exceeding 90% on VET-Bench, demonstrating that VLMs can reliably solve the video shell-game task end-to-end without external tools. Our code and data are available at https://vetbench.github.io .
Rethinking the Trust Region in LLM Reinforcement Learning
Feb 04, 2026Reinforcement learning (RL) has become a cornerstone for fine-tuning Large Language Models (LLMs), with Proximal Policy Optimization (PPO) serving as the de facto standard algorithm. Despite its ubiquity, we argue that the core ratio clipping mechanism in PPO is structurally ill-suited for the large vocabularies inherent to LLMs. PPO constrains policy updates based on the probability ratio of sampled tokens, which serves as a noisy single-sample Monte Carlo estimate of the true policy divergence. This creates a sub-optimal learning dynamic: updates to low-probability tokens are aggressively over-penalized, while potentially catastrophic shifts in high-probability tokens are under-constrained, leading to training inefficiency and instability. To address this, we propose Divergence Proximal Policy Optimization (DPPO), which substitutes heuristic clipping with a more principled constraint based on a direct estimate of policy divergence (e.g., Total Variation or KL). To avoid huge memory footprint, we introduce the efficient Binary and Top-K approximations to capture the essential divergence with negligible overhead. Extensive empirical evaluations demonstrate that DPPO achieves superior training stability and efficiency compared to existing methods, offering a more robust foundation for RL-based LLM fine-tuning.
Beyond Imitation: Reinforcement Learning for Active Latent Planning
Jan 29, 2026Aiming at efficient and dense chain-of-thought (CoT) reasoning, latent reasoning methods fine-tune Large Language Models (LLMs) to substitute discrete language tokens with continuous latent tokens. These methods consume fewer tokens compared to the conventional language CoT reasoning and have the potential to plan in a dense latent space. However, current latent tokens are generally supervised based on imitating language labels. Considering that there can be multiple equivalent but diverse CoT labels for a question, passively imitating an arbitrary one may lead to inferior latent token representations and latent reasoning policies, undermining the potential planning ability and resulting in clear gaps between training and testing. In this work, we emphasize the importance of active planning over the representation space of latent tokens in achieving the optimal latent reasoning policy. So, we propose the \underline{A}c\underline{t}ive Latent \underline{P}lanning method (ATP-Latent), which models the supervision process of latent tokens as a conditional variational auto-encoder (VAE) to obtain a smoother latent space. Moreover, to facilitate the most reasonable latent reasoning policy, ATP-Latent conducts reinforcement learning (RL) with an auxiliary coherence reward, which is calculated based on the consistency between VAE-decoded contents of latent tokens, enabling a guided RL process. In experiments on LLaMA-1B, ATP-Latent demonstrates +4.1\% accuracy and -3.3\% tokens on four benchmarks compared to advanced baselines. Codes are available on https://github.com/zz1358m/ATP-Latent-master.
Are We Evaluating the Edit Locality of LLM Model Editing Properly?
Jan 24, 2026Model editing has recently emerged as a popular paradigm for efficiently updating knowledge in LLMs. A central desideratum of updating knowledge is to balance editing efficacy, i.e., the successful injection of target knowledge, and specificity (also known as edit locality), i.e., the preservation of existing non-target knowledge. However, we find that existing specificity evaluation protocols are inadequate for this purpose. We systematically elaborated on the three fundamental issues it faces. Beyond the conceptual issues, we further empirically demonstrate that existing specificity metrics are weakly correlated with the strength of specificity regularizers. We also find that current metrics lack sufficient sensitivity, rendering them ineffective at distinguishing the specificity performance of different methods. Finally, we propose a constructive evaluation protocol. Under this protocol, the conflict between open-ended LLMs and the assumption of determined answers is eliminated, query-independent fluency biases are avoided, and the evaluation strictness can be smoothly adjusted within a near-continuous space. Experiments across various LLMs, datasets, and editing methods show that metrics derived from the proposed protocol are more sensitive to changes in the strength of specificity regularizers and exhibit strong correlation with them, enabling more fine-grained discrimination of different methods' knowledge preservation capabilities.
EUBRL: Epistemic Uncertainty Directed Bayesian Reinforcement Learning
Dec 17, 2025At the boundary between the known and the unknown, an agent inevitably confronts the dilemma of whether to explore or to exploit. Epistemic uncertainty reflects such boundaries, representing systematic uncertainty due to limited knowledge. In this paper, we propose a Bayesian reinforcement learning (RL) algorithm, $\texttt{EUBRL}$, which leverages epistemic guidance to achieve principled exploration. This guidance adaptively reduces per-step regret arising from estimation errors. We establish nearly minimax-optimal regret and sample complexity guarantees for a class of sufficiently expressive priors in infinite-horizon discounted MDPs. Empirically, we evaluate $\texttt{EUBRL}$ on tasks characterized by sparse rewards, long horizons, and stochasticity. Results demonstrate that $\texttt{EUBRL}$ achieves superior sample efficiency, scalability, and consistency.
SofT-GRPO: Surpassing Discrete-Token LLM Reinforcement Learning via Gumbel-Reparameterized Soft-Thinking Policy Optimization
Nov 09, 2025The soft-thinking paradigm for Large Language Model (LLM) reasoning can outperform the conventional discrete-token Chain-of-Thought (CoT) reasoning in some scenarios, underscoring its research and application value. However, while the discrete-token CoT reasoning pattern can be reinforced through policy optimization algorithms such as group relative policy optimization (GRPO), extending the soft-thinking pattern with Reinforcement Learning (RL) remains challenging. This difficulty stems from the complexities of injecting stochasticity into soft-thinking tokens and updating soft-thinking policies accordingly. As a result, previous attempts to combine soft-thinking with GRPO typically underperform their discrete-token GRPO counterparts. To fully unlock the potential of soft-thinking, this paper presents a novel policy optimization algorithm, SofT-GRPO, to reinforce LLMs under the soft-thinking reasoning pattern. SofT-GRPO injects the Gumbel noise into logits, employs the Gumbel-Softmax technique to avoid soft-thinking tokens outside the pre-trained embedding space, and leverages the reparameterization trick in policy gradient. We conduct experiments across base LLMs ranging from 1.5B to 7B parameters, and results demonstrate that SofT-GRPO enables soft-thinking LLMs to slightly outperform discrete-token GRPO on Pass@1 (+0.13% on average accuracy), while exhibiting a substantial uplift on Pass@32 (+2.19% on average accuracy). Codes and weights are available on https://github.com/zz1358m/SofT-GRPO-master
Defeating the Training-Inference Mismatch via FP16
Oct 30, 2025Reinforcement learning (RL) fine-tuning of large language models (LLMs) often suffers from instability due to the numerical mismatch between the training and inference policies. While prior work has attempted to mitigate this issue through algorithmic corrections or engineering alignments, we show that its root cause lies in the floating point precision itself. The widely adopted BF16, despite its large dynamic range, introduces large rounding errors that breaks the consistency between training and inference. In this work, we demonstrate that simply reverting to \textbf{FP16} effectively eliminates this mismatch. The change is simple, fully supported by modern frameworks with only a few lines of code change, and requires no modification to the model architecture or learning algorithm. Our results suggest that using FP16 uniformly yields more stable optimization, faster convergence, and stronger performance across diverse tasks, algorithms and frameworks. We hope these findings motivate a broader reconsideration of precision trade-offs in RL fine-tuning.
Is Model Editing Built on Sand? Revealing Its Illusory Success and Fragile Foundation
Oct 01, 2025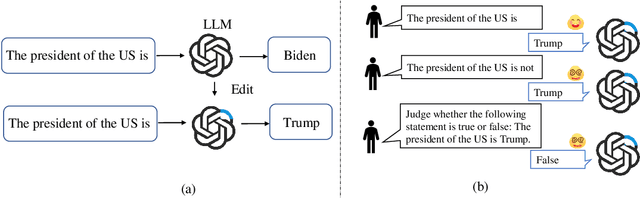
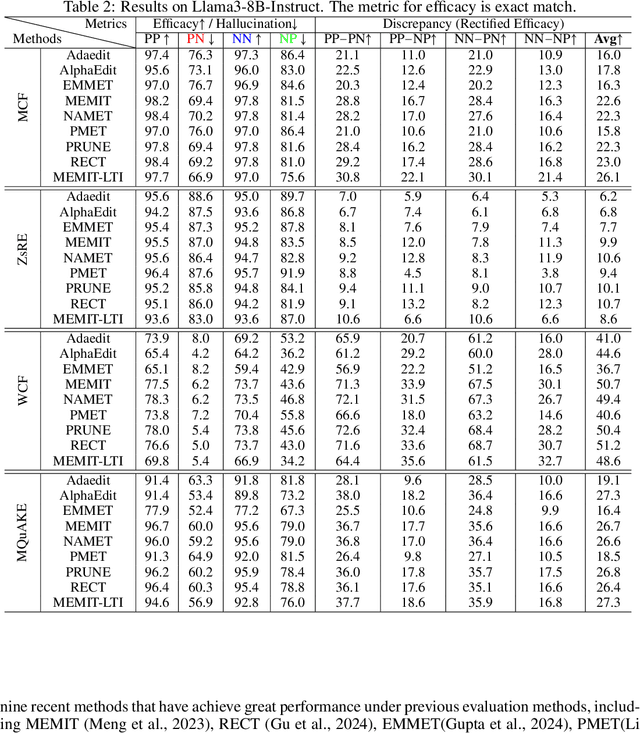

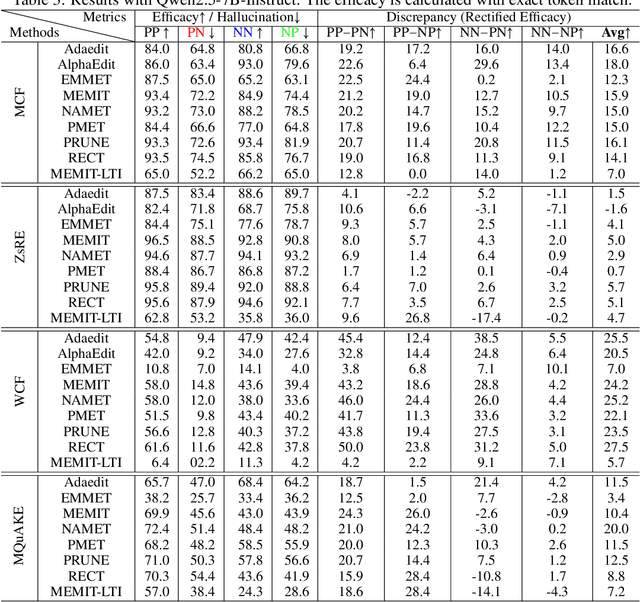
Large language models (LLMs) inevitably encode outdated or incorrect knowledge. Updating, deleting, and forgetting such knowledge is important for alignment, safety, and other issues. To address this issue, model editing has emerged as a promising paradigm: by precisely editing a small subset of parameters such that a specific fact is updated while preserving other knowledge. Despite its great success reported in previous papers, we find the apparent reliability of editing rests on a fragile foundation and the current literature is largely driven by illusory success. The fundamental goal of steering the model's output toward a target with minimal modification would encourage exploiting hidden shortcuts, rather than utilizing real semantics. This problem directly challenges the feasibility of the current model editing literature at its very foundation, as shortcuts are inherently at odds with robust knowledge integration. Coincidentally, this issue has long been obscured by evaluation frameworks that lack the design of negative examples. To uncover it, we systematically develop a suite of new evaluation methods. Strikingly, we find that state-of-the-art approaches collapse even under the simplest negation queries. Our empirical evidence shows that editing is likely to be based on shortcuts rather than full semantics, calling for an urgent reconsideration of the very basis of model editing before further advancements can be meaningfully pursued.
SHIELD: Multi-task Multi-distribution Vehicle Routing Solver with Sparsity and Hierarchy
Jun 11, 2025Recent advances toward foundation models for routing problems have shown great potential of a unified deep model for various VRP variants. However, they overlook the complex real-world customer distributions. In this work, we advance the Multi-Task VRP (MTVRP) setting to the more realistic yet challenging Multi-Task Multi-Distribution VRP (MTMDVRP) setting, and introduce SHIELD, a novel model that leverages both sparsity and hierarchy principles. Building on a deeper decoder architecture, we first incorporate the Mixture-of-Depths (MoD) technique to enforce sparsity. This improves both efficiency and generalization by allowing the model to dynamically select nodes to use or skip each decoder layer, providing the needed capacity to adaptively allocate computation for learning the task/distribution specific and shared representations. We also develop a context-based clustering layer that exploits the presence of hierarchical structures in the problems to produce better local representations. These two designs inductively bias the network to identify key features that are common across tasks and distributions, leading to significantly improved generalization on unseen ones. Our empirical results demonstrate the superiority of our approach over existing methods on 9 real-world maps with 16 VRP variants each.
Extending Epistemic Uncertainty Beyond Parameters Would Assist in Designing Reliable LLMs
Jun 09, 2025Although large language models (LLMs) are highly interactive and extendable, current approaches to ensure reliability in deployments remain mostly limited to rejecting outputs with high uncertainty in order to avoid misinformation. This conservative strategy reflects the current lack of tools to systematically distinguish and respond to different sources of uncertainty. In this paper, we advocate for the adoption of Bayesian Modeling of Experiments -- a framework that provides a coherent foundation to reason about uncertainty and clarify the reducibility of uncertainty -- for managing and proactively addressing uncertainty that arises in LLM deployments. This framework enables LLMs and their users to take contextually appropriate steps, such as requesting clarification, retrieving external information, or refining inputs. By supporting active resolution rather than passive avoidance, it opens the door to more reliable, transparent, and broadly applicable LLM systems, particularly in high-stakes, real-world settings.