 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Benefits of Free Exploration for Regret Minimization in Multi-Armed Bandits
May 25, 2026We study a stochastic multi-armed bandit problem where an agent is granted a free exploration budget before regret accumulates, a setting not captured by the classic regret minimization or pure exploration paradigms. The goal is to design an adaptive policy that strategically explores the bandit instance in the initial free exploration phase and minimizes the cumulative regret in the subsequent phase. We formalize this regret minimization with free exploration problem and identify an interesting regime where the free exploration budget scales logarithmically with the time horizon. To quantify the amount of regret saved with high probability as a result of the availability of the free exploration phase, we introduce a novel set of policies known as $(α,β)$-probably saving policies. We propose a two-phase, probably saving algorithm, UFE-KLUCB-H, which consists of a principled free exploration policy, UFE, and a history-aware regret minimization policy KLUCB-H. Instance-dependent upper bounds on UFE-KLUCB-H are derived, showing that UFE-KLUCB-H accumulates strictly less regret than policies that do not have access to a free exploration phase. Complementarily, we derive instance-dependent lower bounds based on novel multi-instance perturbation arguments tailored to the free-exploration setting, demonstrating the near-optimality of UFE-KLUCB-H for two-valued bandits. Our upper and lower bounds reveal sharp phase transitions in the accumulated regret depending on the amount of available free exploration. Simulations are conducted to demonstrate that forced exploration and adaptivity in the algorithm lead to greater regret savings.
How Many Different Outputs Can a Transformer Generate?
May 21, 2026We study how we can leverage only a handful of characteristics of a transformer's architecture to closely predict the number of different sequences it can output, both qualitatively and quantitatively. We provide an upper bound depending on the length of the prompt, which we show empirically to be tight up to a factor less than 10, across architectures and model sizes. Our analysis also provides a theoretical explanation for previously observed empirical failures of transformers on simple sequence tasks, such as copying and cramming. Formally, we prove that (i) the maximal length of accessible sequences (those that the transformer can output for some prompt) grows linearly with the prompt length, (ii) beyond a critical threshold, the proportion of accessible sequences decays exponentially with sequence length, and (iii) the linear coefficient relating prompt length to accessible sequence length admits a theoretical upper bound. Notably, these results hold even with unbounded context and computation time.
Bandit Convex Optimization with Gradient Prediction Adaptivity
May 21, 2026Bandit convex optimization (BCO) is a fundamental online learning framework with partial feedback, where the learner observes only the loss incurred at the chosen decision point in each round. In this work, we investigate whether optimistic gradient predictions can improve worst-case regret guarantees in a prediction-adaptive manner. Specifically, given gradient predictions $m_t$, we seek regret bounds that scale with the cumulative prediction error $S_T=\sum_{t=1}^T \|\nabla f_t(x_t)-m_t\|^2.$ We first establish a negative result: under the single-point feedback protocol, an unavoidable $Ω(\sqrt{T})$ regret lower bound persists even when $S_T=o(T)$, showing that the variance of gradient estimation fundamentally obscures the benefit of accurate predictions. To overcome this barrier, we propose \emph{Two-Point Variance-Reduced Optimistic Gradient Descent} (TP-VR-OPT) for the two-point feedback setting. The key idea is a novel variance-reduced gradient estimator whose variance scales with the prediction error rather than the gradient norm. This yields a regret bound of $O\big(\sqrt{d\,\mathbb{E}[S_T]}\big),$ where $d$ is the decision dimension. Complementing this result, we establish an information-theoretic lower bound that scales as $Ω(\sqrt{\mathbb{E}[S_T]})$, providing a fundamental characterization of the best achievable prediction-adaptive regret and showing that TP-VR-OPT is optimal up to a factor of $\sqrt d$. We further develop adaptive variants that eliminate the need for prior knowledge of $\mathbb{E}[S_T]$ or the horizon $T$, and extend our framework to non-stationary environments, establishing dynamic regret guarantees that adapt simultaneously to the cumulative prediction error and the comparator path length.
ODELoRA: Training Low-Rank Adaptation by Solving Ordinary Differential Equations
Feb 07, 2026Low-rank adaptation (LoRA) has emerged as a widely adopted parameter-efficient fine-tuning method in deep transfer learning, due to its reduced number of trainable parameters and lower memory requirements enabled by Burer-Monteiro factorization on adaptation matrices. However, classical LoRA training methods treat the low-rank factor matrices individually and optimize them using standard gradient-based algorithms. Such decoupled optimization schemes are theoretically and empirically suboptimal, as they fail to fully exploit the intrinsic structure of the LoRA parameterization. In this work, we propose a novel continuous-time optimization dynamic for LoRA factor matrices in the form of an ordinary differential equation (ODE) that emulates the gradient flow of full fine-tuning on the balanced manifold. We term this approach ODELoRA. To faithfully track the trajectories of ODELoRA, we adopt well-established and theoretically grounded time-discretization schemes, including Euler and Runge--Kutta methods. Our framework provides a unified ODE-based perspective for understanding and designing LoRA training algorithms. We establish linear convergence of the proposed method under strongly convex objectives for certain discretization schemes under mild conditions, and further extend our analysis to the matrix sensing setting. Moreover, we show that ODELoRA achieves stable feature learning, a property that is crucial for training deep neural networks at different scales of problem dimensionality. Empirical results on matrix sensing tasks confirm the derived linear convergence behavior, and experiments on training physics-informed neural networks further demonstrate the superiority of ODELoRA over existing baselines, especially in the training stability.
Almost Asymptotically Optimal Active Clustering Through Pairwise Observations
Feb 05, 2026We propose a new analysis framework for clustering $M$ items into an unknown number of $K$ distinct groups using noisy and actively collected responses. At each time step, an agent is allowed to query pairs of items and observe bandit binary feedback. If the pair of items belongs to the same (resp.\ different) cluster, the observed feedback is $1$ with probability $p>1/2$ (resp.\ $q<1/2$). Leveraging the ubiquitous change-of-measure technique, we establish a fundamental lower bound on the expected number of queries needed to achieve a desired confidence in the clustering accuracy, formulated as a sup-inf optimization problem. Building on this theoretical foundation, we design an asymptotically optimal algorithm in which the stopping criterion involves an empirical version of the inner infimum -- the Generalized Likelihood Ratio (GLR) statistic -- being compared to a threshold. We develop a computationally feasible variant of the GLR statistic and show that its performance gap to the lower bound can be accurately empirically estimated and remains within a constant multiple of the lower bound.
Parameter-free Algorithms for the Stochastically Extended Adversarial Model
Oct 06, 2025

We develop the first parameter-free algorithms for the Stochastically Extended Adversarial (SEA) model, a framework that bridges adversarial and stochastic online convex optimization. Existing approaches for the SEA model require prior knowledge of problem-specific parameters, such as the diameter of the domain $D$ and the Lipschitz constant of the loss functions $G$, which limits their practical applicability. Addressing this, we develop parameter-free methods by leveraging the Optimistic Online Newton Step (OONS) algorithm to eliminate the need for these parameters. We first establish a comparator-adaptive algorithm for the scenario with unknown domain diameter but known Lipschitz constant, achieving an expected regret bound of $\tilde{O}\big(\|u\|_2^2 + \|u\|_2(\sqrt{\sigma^2_{1:T}} + \sqrt{\Sigma^2_{1:T}})\big)$, where $u$ is the comparator vector and $\sigma^2_{1:T}$ and $\Sigma^2_{1:T}$ represent the cumulative stochastic variance and cumulative adversarial variation, respectively. We then extend this to the more general setting where both $D$ and $G$ are unknown, attaining the comparator- and Lipschitz-adaptive algorithm. Notably, the regret bound exhibits the same dependence on $\sigma^2_{1:T}$ and $\Sigma^2_{1:T}$, demonstrating the efficacy of our proposed methods even when both parameters are unknown in the SEA model.
Automatic Rank Determination for Low-Rank Adaptation via Submodular Function Maximization
Jul 02, 2025In this paper, we propose SubLoRA, a rank determination method for Low-Rank Adaptation (LoRA) based on submodular function maximization. In contrast to prior approaches, such as AdaLoRA, that rely on first-order (linearized) approximations of the loss function, SubLoRA utilizes second-order information to capture the potentially complex loss landscape by incorporating the Hessian matrix. We show that the linearization becomes inaccurate and ill-conditioned when the LoRA parameters have been well optimized, motivating the need for a more reliable and nuanced second-order formulation. To this end, we reformulate the rank determination problem as a combinatorial optimization problem with a quadratic objective. However, solving this problem exactly is NP-hard in general. To overcome the computational challenge, we introduce a submodular function maximization framework and devise a greedy algorithm with approximation guarantees. We derive a sufficient and necessary condition under which the rank-determination objective becomes submodular, and construct a closed-form projection of the Hessian matrix that satisfies this condition while maintaining computational efficiency. Our method combines solid theoretical foundations, second-order accuracy, and practical computational efficiency. We further extend SubLoRA to a joint optimization setting, alternating between LoRA parameter updates and rank determination under a rank budget constraint. Extensive experiments on fine-tuning physics-informed neural networks (PINNs) for solving partial differential equations (PDEs) demonstrate the effectiveness of our approach. Results show that SubLoRA outperforms existing methods in both rank determination and joint training performance.
Log-Sum-Exponential Estimator for Off-Policy Evaluation and Learning
Jun 07, 2025Off-policy learning and evaluation leverage logged bandit feedback datasets, which contain context, action, propensity score, and feedback for each data point. These scenarios face significant challenges due to high variance and poor performance with low-quality propensity scores and heavy-tailed reward distributions. We address these issues by introducing a novel estimator based on the log-sum-exponential (LSE) operator, which outperforms traditional inverse propensity score estimators. Our LSE estimator demonstrates variance reduction and robustness under heavy-tailed conditions. For off-policy evaluation, we derive upper bounds on the estimator's bias and variance. In the off-policy learning scenario, we establish bounds on the regret -- the performance gap between our LSE estimator and the optimal policy -- assuming bounded $(1+\epsilon)$-th moment of weighted reward. Notably, we achieve a convergence rate of $O(n^{-\epsilon/(1+ \epsilon)})$ for the regret bounds, where $\epsilon \in [0,1]$ and $n$ is the size of logged bandit feedback dataset. Theoretical analysis is complemented by comprehensive empirical evaluations in both off-policy learning and evaluation scenarios, confirming the practical advantages of our approach. The code for our estimator is available at the following link: https://github.com/armin-behnamnia/lse-offpolicy-learning.
Best Arm Identification with Possibly Biased Offline Data
May 29, 2025We study the best arm identification (BAI) problem with potentially biased offline data in the fixed confidence setting, which commonly arises in real-world scenarios such as clinical trials. We prove an impossibility result for adaptive algorithms without prior knowledge of the bias bound between online and offline distributions. To address this, we propose the LUCB-H algorithm, which introduces adaptive confidence bounds by incorporating an auxiliary bias correction to balance offline and online data within the LUCB framework. Theoretical analysis shows that LUCB-H matches the sample complexity of standard LUCB when offline data is misleading and significantly outperforms it when offline data is helpful. We also derive an instance-dependent lower bound that matches the upper bound of LUCB-H in certain scenarios. Numerical experiments further demonstrate the robustness and adaptability of LUCB-H in effectively incorporating offline data.
BanditSpec: Adaptive Speculative Decoding via Bandit Algorithms
May 21, 2025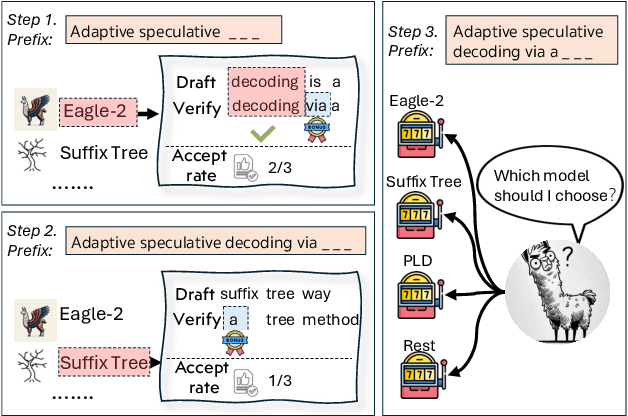
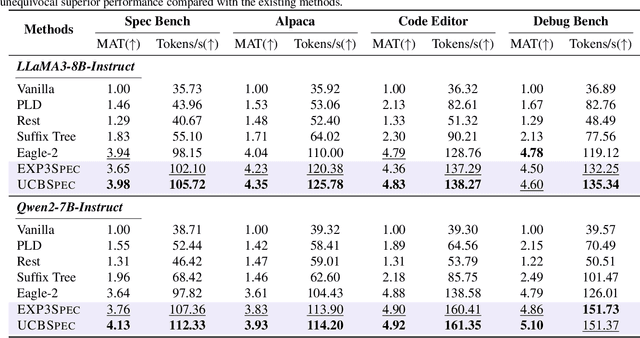
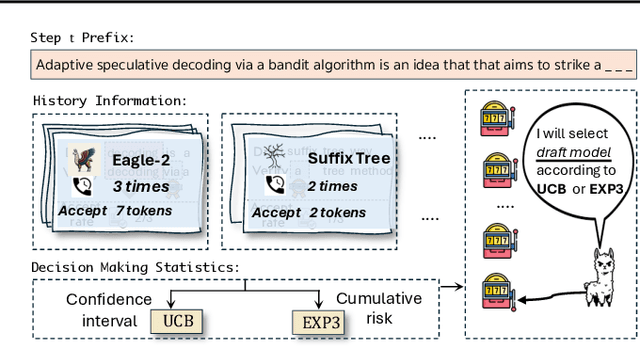
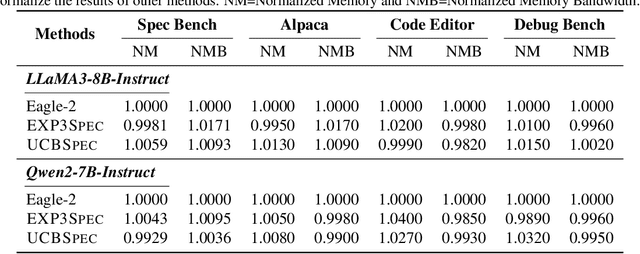
Speculative decoding has emerged as a popular method to accelerate the inference of Large Language Models (LLMs) while retaining their superior text generation performance. Previous methods either adopt a fixed speculative decoding configuration regardless of the prefix tokens, or train draft models in an offline or online manner to align them with the context. This paper proposes a training-free online learning framework to adaptively choose the configuration of the hyperparameters for speculative decoding as text is being generated. We first formulate this hyperparameter selection problem as a Multi-Armed Bandit problem and provide a general speculative decoding framework BanditSpec. Furthermore, two bandit-based hyperparameter selection algorithms, UCBSpec and EXP3Spec, are designed and analyzed in terms of a novel quantity, the stopping time regret. We upper bound this regret under both stochastic and adversarial reward settings. By deriving an information-theoretic impossibility result, it is shown that the regret performance of UCBSpec is optimal up to universal constants. Finally, extensive empirical experiments with LLaMA3 and Qwen2 demonstrate that our algorithms are effective compared to existing methods, and the throughput is close to the oracle best hyperparameter in simulated real-life LLM serving scenarios with diverse input prompts.